提取pdf文件中的图片
In NLP projects the input documents often come as PDFs. Sometimes the PDFs already contain underlying text information, which makes it possible to extract text without the use of OCR tools. In the following I want to present some open-source PDF tools available in Python that can be used to extract text. I will compare their features and point out some drawbacks.
在NLP项目中,输入文档通常以PDF格式出现。 有时,PDF已包含基础文本信息,这使得无需使用OCR工具即可提取文本。 在下面的内容中,我想介绍一些可用的Python开源PDF工具,这些工具可用于提取文本。 我将比较它们的功能并指出一些缺点。
Those tools are PyPDF2, pdfminer and PyMuPDF.
这些工具是PyPDF2 , pdfminer和PyMuPDF 。
There are other Python PDF libraries which are either not able to extract text or focused on other tasks. Furthermore, there are tools that are able to extract text from PDF documents, but which are not available in Python. Both will not be discussed here.
还有其他Python PDF库,它们要么无法提取文本,要么专注于其他任务。 此外,有些工具能够从PDF文档中提取文本,但是在Python中不可用。 两者都不会在这里讨论。
介绍 (Introduction)
We have already discussed different OCR tools for automatically extracting text from documents. Although there are well-performing tools, they still make errors. So, aiming at extracting information from documents one either has to build robust models which can manage small errors or seek for alternative ways of text extraction. For images and documents with no underlying text information, OCR tools are without alternative. But when it comes to PDF documents with underlying text, the question arises if one could access this text information directly, circumventing possible OCR errors. I want to discuss this and provide insights from our experiences in recent projects.
我们已经讨论了用于从文档中自动提取文本的各种OCR工具 。 尽管有性能良好的工具,但它们仍然会出错。 因此,以从文档中提取信息为目标,要么必须建立可以管理小错误的健壮模型,要么寻求文本提取的替代方法。 对于没有基础文本信息的图像和文档,OCR工具是不可替代的。 但是,当涉及带有基础文本的PDF文档时,就会出现一个问题,即是否可以直接访问此文本信息,从而避免可能的OCR错误。 我想对此进行讨论,并提供我们在最近项目中的经验中的见解。
First of all, it should be mentioned that PDF is not made for retrieving text information. PDF stands for Portable Document Format and was developed by Adobe. The main goal was to be able to exchange information platform-independently while preserving and protecting the content and layout of a document. This results in PDFs being hard to edit and difficult with extracting information from them. Which does not mean it is impossible.
首先,应该提到的是,PDF不是用于检索文本信息的。 PDF代表可移植文档格式 ,由Adobe开发。 主要目标是能够独立交换平台信息,同时保留并保护文档的内容和布局。 这导致PDF难以编辑,并且难以从中提取信息。 这并不意味着不可能。
Second, one has to decide how much information is actually needed. Do you only need the plain text information, do you also need the position of the text, do you maybe also want some font information? Those are questions which are also important when deciding on a suitable OCR tool. Everything is possible, but the task gets more complex and more messy with each additional layer of information needed.
其次,必须决定实际需要多少信息。 您只需要纯文本信息,是否还需要文本的位置,也许还需要一些字体信息? 这些是在决定合适的OCR工具时也很重要的问题。 一切皆有可能,但是任务变得更加复杂,并且每增加一层所需的信息就更加混乱。
We will test the three libraries on three simple sample PDFs:
我们将在三个简单的样本PDF上测试这三个库:

PyPDF2 (PyPDF2)
PyPDF2 is a pure Python PDF library capable of splitting, merging together, cropping, and transforming pages of different PDF files. We can retrieve metadata from PDFs, like author, creator, creation date and others. It can also retrieve the PDF text as found in the content stream. This means that the text might not be ordered logically if it is not done so in the stream object associated with the PDF. Illogical ordering should not happen in general, but as the documents get more complex the text ordering might too. The code for retrieving the plain text is rather simple:
PyPDF2是一个纯Python PDF库,能够拆分,合并,裁剪和转换不同PDF文件的页面。 我们可以从PDF中检索元数据,例如作者,创建者,创建日期等。 它还可以检索内容流中的PDF文本。 这意味着,如果未在与PDF关联的流对象中对文本进行逻辑排序,则可能无法对其进行逻辑排序。 一般而言,不合逻辑的排序不应该发生,但是随着文档变得越来越复杂,文本排序也可能会发生。 检索纯文本的代码非常简单:
样品表现 (Sample performance)
Let’s look at the output we get for the different PDFs:
让我们看一下获得不同PDF的输出:
Sample 1: “Adobe Acrobat PDF Files\n \nAdobe® Portable Document Format (PDF) is a universal file format that preserves all \nof the fonts, formatting, colours and graphics of any source document, regardless of the \napplication and platform used to create it.\n \nAdobe PDF is an ideal format for electr\nonic document distribution as it overcomes the \nproblems commonly encountered with electronic file sharing.\n \n\n \nAnyone, anywhere\n \ncan open a PDF file. All you need is the free Adobe Acrobat \nReader. Recipients of other file formats sometimes can’t open files beca\nuse they \ndon’t have the applications used to create the documents.\n \n\n \nPDF files \nalways print correctly\n \non any printing device.\n \n\n \nPDF files always display \nexactly\n \nas created, regardless of fonts, software, and \noperating systems. Fonts, and graphics are not lost \ndue to platform, software, and \nversion incompatibilities.\n \n\n \nThe free Acrobat Reader is easy to download and can be freely distributed by \nanyone.\n \n\n \nCompact PDF files are smaller than their source files and download a page at a time \nfor fast display on the Web.\n \n”
示例1 :“ Adobe Acrobat PDF文件\ n \nAdobe®便携式文档格式(PDF)是一种通用文件格式,可以保留所有\ n所有源文档的字体,格式,颜色和图形,而与\ n应用程序和平台无关来创建它。\ n \ nAdobe PDF是电子\ nonic文档分发的理想格式,因为它克服了\ n电子文件共享中常见的问题。\ n \ n \ n \ n任何地方的任何人\ n \ n可以打开PDF文件。 您只需要免费的Adobe Acrobat \ nReader。 其他文件格式的接收者有时无法打开文件,因为\没有用于创建文档的应用程序。\ n \ n \ n \ nPDF文件\始终可以正确打印\ n \没有任何打印设备。\ n \ n \ n \ nPDF文件始终显示\ nxactly \ n \ nas创建,而不管字体,软件和\ n操作系统如何。 字体和图形不会丢失\由于平台,软件和\ n版本的不兼容性。\ n \ n \ n \ n免费的Acrobat Reader易于下载,并且可以由\ nanyone免费分发。\ n \ n \ n \ nCompact PDF文件小于其源文件,并一次下载页面\ n以便在Web上快速显示。\ n \ n”
Sample 2: “\n\n\n\n\n\n\nˇˇˇ\nˇ\n\n\n\nˆˇ\n˝\n\nˇ˛\nˇ\n\n˚\n˜˙ˆ\n\nˇˆ\n\n\n\nˆ\nˇˇ\n·˘\n·\n· ˜\n·ˆˇ!\n˜ˇ\n\n\n·ˆ\n·ˆˇ”ˇ\n\n\n\n\n\n\n\n\n\n”
示例2 :“ \ n \ n \ n \ n \ n \ n \ nˇˇˇ \ nˇ \ n \ n \ n \ nˆˇ \n˝\ n \ nˇ˛ \ nˇ \ n \n˚\ n〜˙ˆ \ n \ nˇˆ \ n \ n \ n \ nˆ \ nˇˇ \ n·˘\ n·\ n·〜\ n·ˆˇ!\ n〜ˇ \ n \ n \ n·ˆ \ n·ˆˇ” ˇ \ n \ n \ n \ n \ n \ n \ n \ n \ n \ n”
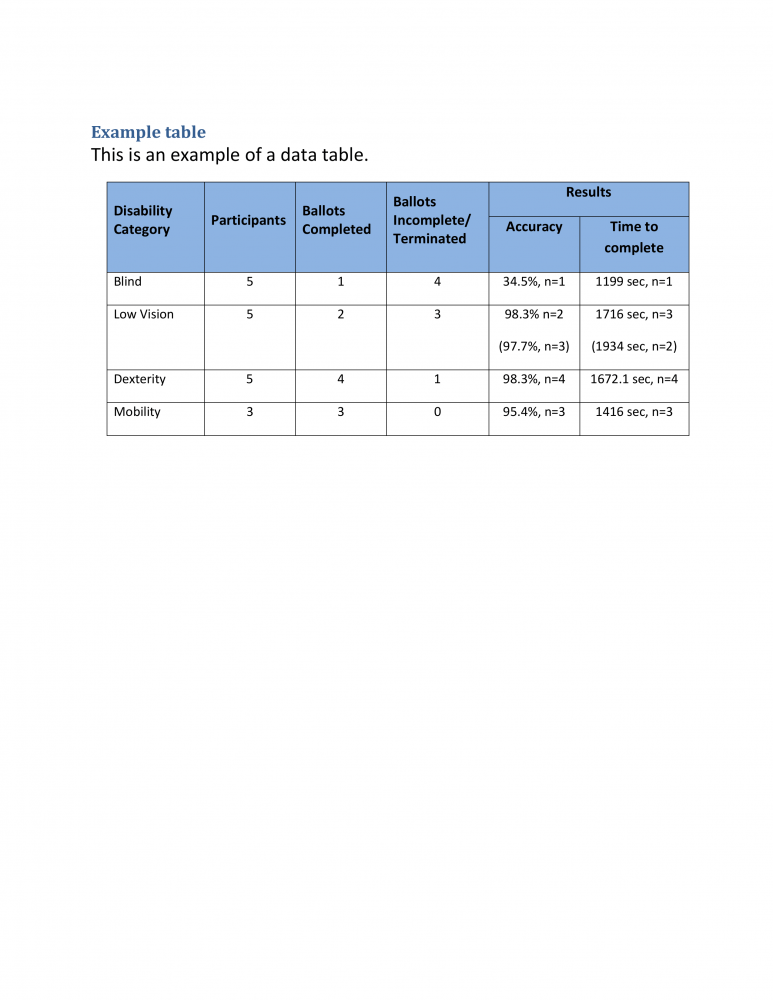
Sample 3: “Example table\n This is an example of a data table.\n Disability \nCategory\n Participants\n Ballots \nCompleted\n Ballots \nIncomplete/\n Terminated\n Results\n Accuracy\n Time to \ncomplete\n Blind\n 5 1 4 34.5%, n=1\n 1199 sec, n=1\n Low Vision\n 5 \n2 \n3 \n98.3% n=2\n (97.7%, n=3)\n 1716 \nsec, n=3\n (1934 sec, n=2)\n Dexterity\n 5 \n4 \n1 \n98.3%, n=4\n 1672.1 sec, n=4\n Mobility\n 3 \n3 \n0 \n95.4%, n=3\n 1416 sec, n=3\n”
示例3 :“示例表\ n这是数据表的示例。\ n残障\ n类别\ n参与者\ n选票\ n已完成\ n选票\ n未完成/ \ n终止\ n结果\ n准确性\ n达到时间\ ncomplete \ n盲目\ n 5 1 4 34.5%,n = 1 \ n 1199秒,n = 1 \ n低视力\ n 5 \ n2 \ n3 \ n98.3%n = 2 \ n(97.7%,n = 3)\ n 1716 \ nsec,n = 3 \ n(1934秒,n = 2)\ n敏捷度\ n 5 \ n4 \ n1 \ n98.3%,n = 4 \ n 1672.1秒,n = 4 \ n移动性\ n 3 \ n3 \ n0 \ n95.4%,n = 3 \ n 1416秒,n = 3 \ n”
Sample 2 actually looks like rubbish. PyPDF2 seems to have some problems with this file, although it looks quite normal when accessed with a PDF viewer. This can happen if the PDF creation software misses to link some font information when creating the PDF. Some more sophisticated PDF viewers and packages are capable of handling those issues, PyPDF2 fails with this particular document. Sample 1 also has some escape characters \n added where there shouldn't be any (e.g. the bold text). Sample 3 looks quite fine.
示例2实际上看起来像垃圾。 PyPDF2似乎与此文件有些问题,尽管使用PDF查看器访问时看起来很正常。 如果PDF创建软件在创建PDF时未链接某些字体信息,则可能会发生这种情况。 一些更复杂的PDF查看器和程序包能够处理这些问题, PyPDF2对此特定文档失败。 示例1还在不应该存在的转义字符\n添加了\n (例如,粗体)。 示例3看起来还不错。
缺少文字信息或文字信息过多时 (On missing text information or too much text information)
Those errors like the one of PyPDF2 on Sample 2 can even occur when working with more sophisticated PDF libraries and can be hard to detect. Furthermore, things become much more difficult if the PDF is a mixture of text with available underlying text information and scan like areas, where text is visible but no text information can be obtained. Then you will miss some of the text information. The other way round is also possible: areas with no visible text, but obtainable underlying text information. Then you get too much text information (which can be a good thing, if you aim at detecting such hidden information). Both are hard to detect and difficult to cope with. Again, PDFs are a messy business.
使用更复杂的PDF库时,甚至会出现样本2上PyPDF2错误,并且很难检测到。 此外,如果PDF是文本与可用的基础文本信息的混合,并且扫描类似的区域(其中文本可见但无法获取文本信息),则事情将变得更加困难。 然后,您将错过一些文本信息。 也可以采用另一种方式:没有可见文本,但是可获得底层文本信息的区域。 然后,您会收到太多的文本信息(如果您打算检测这种隐藏的信息,这可能是一件好事)。 两者都难以发现且难以应对。 同样,PDF是一团糟。
pdfminer (pdfminer)
In contrast to PyPDF2, pdfminer does not take the ordering of the text from the content stream, but extracts additional information like text coordinates. Using them, it tries to merge all available characters to words, the words to associated text lines and the lines to paragraph-like objects. The image below illustrates this process. The blue boxes are the word objects, the green boxes the text line objects and the red box delineates the paragraph-like object (not all of them are labeled here).
与PyPDF2 , pdfminer不会从内容流中获取文本的顺序,而是会提取其他信息,例如文本坐标。 它使用它们尝试将所有可用字符合并到单词,将单词合并到关联的文本行以及将这些行合并到类似段落的对象。 下图说明了此过程。 蓝色框表示单词对象,绿色框表示文本行对象,红色框表示类似段落的对象(此处未全部标记)。
This geometric analysis can be manipulated in order to influence how pdfminer finds words, text lines and text blocks. The code for retrieving the plain text is a bit more difficult than the one for PyPDF2:
可以操纵这种几何分析,以影响pdfminer如何查找单词,文本行和文本块。 检索纯文本的代码比PyPDF2要难一些:
This is very high-level and should just extract the plain text. We can manipulate the geometric analysis with the LAParams() object and additionally retrieve the before-mentioned geometrical information of the objects as well as some font information.
这是非常高级的,应该只提取纯文本。 我们可以使用LAParams()对象进行几何分析,并另外检索对象的上述几何信息以及一些字体信息。
样品表现 (Sample performance)
Let’s look at the output we get for the different PDFs:
让我们看一下获得不同PDF的输出:
Sample 1: “Adobe Acrobat PDF Files \nAdobe® Portable Document Format (PDF) is a universal file format that preserves all \nof the fonts, formatting, colours and graphics of any source document, regardless of the \napplication and platform used to create it. \nAdobe PDF is an ideal format for electronic document distribution as it overcomes the \nproblems commonly encountered with electronic file sharing. \n* Anyone, anywhere can open a PDF file. All you need is the free Adobe Acrobat \nReader. Recipients of other file formats sometimes can’t open files because they \ndon’t have the applications used to create the documents. \n* PDF files always print correctly on any printing device. \n* PDF files always display exactly as created, regardless of fonts, software, and \noperating systems. Fonts, and graphics are not lost due to platform, software, and \nversion incompatibilities. \n* The free Acrobat Reader is easy to download and can be freely distributed by \nanyone. \n* Compact PDF files are smaller than their source files and download a page at a time \nfor fast display on the Web. \n”
示例1 :“ Adobe Acrobat PDF文件\nAdobe®可移植文档格式(PDF)是一种通用文件格式,可以保留所有\ n所有源文档的字体,格式,颜色和图形,而与创建该文档的\ n应用程序和平台无关它。 \ nAdobe PDF是电子文档分发的理想格式,因为它克服了电子文件共享中常见的\ n问题。 \ n *任何地方的任何人都可以打开PDF文件。 您只需要免费的Adobe Acrobat \ nReader。 其他文件格式的收件人有时无法打开文件,因为它们没有用于创建文档的应用程序。 \ n * PDF文件始终可以在任何打印设备上正确打印。 \ n *不论字体,软件和操作系统如何,PDF文件始终显示与创建时完全相同的格式。 字体和图形不会由于平台,软件和\ n版本不兼容而丢失。 \ n *免费的Acrobat Reader易于下载,\ nanyone可以免费分发。 \ n *精巧的PDF文件小于其源文件,并一次下载一个页面,以便在网络上快速显示。 \ n”
Sample 2: “Lorem ipsum \nLorem ipsum dolor sit amet, consectetur adipiscing \nelit. Nunc ac faucibus odio. \nVestibulum neque massa, scelerisque sit amet ligula eu, congue molestie mi. Praesent ut\nvarius sem. Nullam at porttitor arcu, nec lacinia nisi. Ut ac dolor vitae odio interdum\ncondimentum. Vivamus dapibus sodales ex, vitae malesuada ipsum cursus\nconvallis. Maecenas sed egestas nulla, ac condimentum orci. Mauris diam felis,\nvulputate ac suscipit et, iaculis non est. Curabitur semper arcu ac ligula semper, nec luctus\nnisl blandit. Integer lacinia ante ac libero lobortis imperdiet. Nullam mollis convallis ipsum,\nac accumsan nunc vehicula vitae. Nulla eget justo in felis tristique fringilla. Morbi sit amet\ntortor quis risus auctor condimentum. Morbi in ullamcorper elit. Nulla iaculis tellus sit amet\nmauris tempus fringilla.\nMaecenas mauris lectus, lobortis et purus mattis, blandit dictum tellus.\n* Maecenas non lorem quis tellus placerat varius. \n* Nulla facilisi. \n* Aenean congue fringilla justo ut aliquam. \n* Mauris id ex erat. Nunc vulputate neque vitae justo facilisis, non condimentum ante\nsagittis. \n* Morbi viverra semper lorem nec molestie. \n* Maecenas tincidunt est efficitur ligula euismod, sit amet ornare est vulputate.\n12\n10\n8\n6\n4\n2\n0\nColumn 1\nColumn 2\nColumn 3\nRow 1\nRow 2\nRow 3\nRow 4\n”
示例2 :“ Lorem ipsum \ nLorem ipsum dolor坐着,安全贴合\ nelit。 Nunc ac faucibus dioo。 \ n前庭马萨诸塞州,坐在amet ligula eu的celesqueque,congue s鼠mi。 ut \ nvarius sem。 Nullam at Porttitor arcu,nec lacinia nisi。 统一的生活条件。 Vivamus dapibus sodales前,履历书\ nconvallis。 Maecenas s eg egesta nulla,ac调味品。 毛里斯·迪亚斯·费利斯(Mauris diam felis),\ n不知所措等等,科拉比斯·森Perl(curabitur semper)阿库斯·埃·普利古拉·森Perl(nec luctus \ nnisl blandit)。 整数cincin ac ero libortis imperdiet。 Nullam mollis convallis ipsum,\ nac accumsan nunc vehicula vitae。 Nulla eget justo in felis tristique fringilla。 莫比(Morbi)坐着。 莫拉(Ultracorper)中的莫尔比。 Nulla iaculistellus坐在amet \ nmauris tempus fringilla。\ nMaecenas mauris lectus,Lobortis et purus mattis,Blandit dictumtellus。\ n * Maecenas non lorem quis tellus placerat varius。 \ n * Nulla facilisi。 \ n * Aenean congue fringilla justo ut aliquam。 \ n *毛里斯身分证。 Nunc vulputate neque vitae justo facilisis,非调味品前\ n矢状。 \ n * Morbi viverra semper lorem nec molestie。 \ n * Maecenas tincidunt est effligtur ligula euismod,amet ornare est vulputate。\ n12 \ n10 \ n8 \ n6 \ n4 \ n2 \ n0 \ n第1 \ n列2 \ n第3 \ n行1 \ nRow 2 \ nRow 3 \ nRow 4 \ n”
Sample 3: “Example table \nThis is an example of a data table. \nDisability \nCategory \nParticipants \nBallots \nCompleted \nBallots \nIncomplete/ \nTerminated \nBlind \nLow Vision \nDexterity \nMobility \n \n5 \n5 \n5 \n3 \n1 \n2 \n4 \n3 \n4 \n3 \n1 \n0 \nResults \nAccuracy \nTime to \ncomplete \n34.5%, n=1 \n1199 sec, n=1 \n98.3% n=2 \n1716 sec, n=3 \n(97.7%, n=3) \n(1934 sec, n=2) \n98.3%, n=4 \n1672.1 sec, n=4 \n95.4%, n=3 \n1416 sec, n=3 \n”
示例3 :“示例表\ n这是数据表的示例。 \ n残障\ n类别\ n参与者\ nBallots \ n已完成\ nBallots \ nIncomplete / \ n已终止\ nBlind \ n低视力\ nDexterity \ n移动性\ n \ n5 \ n5 \ n5 \ n3 \ n1 \ n2 \ n4 \ n3 \ n4 \ n \ n0 \ n结果\ n精度\ n完成\ n的时间\ n34.5%,n = 1 \ n1199秒,n = 1 \ n98.3%n = 2 \ n1716秒,n = 3 \ n(97.7%,n = 3)\ n(1934秒,n = 2)\ n98.3%,n = 4 \ n1672.1秒,n = 4 \ n95.4%,n = 3 \ n1416秒,n = 3 \ n”
This looks good. pdfminer is able to extract the text in Sample 2 too and also extracts the text from the figure in it (which can be turned off). For Sample 1 the font information could be accessed too, thus resulting in better text extraction than PyPDF2 which tries to indicate bold text by grouping it with "\n". However, the code is not as straightforward as with PyPDF2.
看起来不错 pdfminer也能够提取示例2中的文本,也可以从其中的图中提取文本(可以将其关闭)。 对于示例1,字体信息也可以访问,因此与PyPDF2相比, PyPDF2试图通过将其与“ \ n”分组来表示粗体文本,从而可以更好地提取文本。 但是,该代码并不像PyPDF2那样简单。
PyMuPDF (PyMuPDF)
Both pdfminer and PyPDF2 are pure Python libraries. In contrast, PyMuPDF is based on MuPDF, a lightweight but extensive PDF viewer. This has huge advantages when it comes to handling difficult PDFs but is more strict on the licensing, since MuPDF is a commercial product. Additionally, PyMuPDF claims to be significantly faster than pdfminer and PyPDF2 in various tasks. PyMuPDF, as pdfminer, can extract geometrical text information and font information too, but has, like PyPDF2, also the possibility to extract the plain text directly. In contrast to pdfminer, there is no possibility to manipulate the algorithm of geometric text analysis. PyMuPDF groups the text in textblocks and textlines as done by MuPDF.
pdfminer和PyPDF2都是纯Python库。 相反, PyMuPDF基于MuPDF , MuPDF是一种轻量级但功能广泛的PDF查看器。 当处理困难的PDF时,这具有巨大的优势,但是由于MuPDF是商业产品,因此对许可的要求更加严格。 此外, PyMuPDF声称在各种任务中比 pdfminer 和 PyPDF2 快得多 。 PyMuPDF作为pdfminer ,也可以提取几何文本信息和字体信息,但是像PyPDF2一样,也可以直接提取纯文本。 与pdfminer ,没有可能操纵几何文本分析算法。 PyMuPDF集团在文本textblocks和textlines作为所做MuPDF 。
The simple code for just retrieving the plain text looks the following:
检索纯文本的简单代码如下所示:
This is simple and straighforward.
这很简单明了。
样品表现 (Sample performance)
Let’s look at the output:
让我们看一下输出:
Sample 1: “Adobe Acrobat PDF Files \nAdobe® Portable Document Format (PDF) is a universal file format that preserves all \nof the fonts, formatting, colours and graphics of any source document, regardless of the \napplication and platform used to create it. \nAdobe PDF is an ideal format for electronic document distribution as it overcomes the \nproblems commonly encountered with electronic file sharing. \n* \nAnyone, anywhere can open a PDF file. All you need is the free Adobe Acrobat \nReader. Recipients of other file formats sometimes can’t open files because they \ndon’t have the applications used to create the documents. \n* \nPDF files always print correctly on any printing device. \n* \nPDF files always display exactly as created, regardless of fonts, software, and \noperating systems. Fonts, and graphics are not lost due to platform, software, and \nversion incompatibilities. \n* \nThe free Acrobat Reader is easy to download and can be freely distributed by \nanyone. \n* \nCompact PDF files are smaller than their source files and download a page at a time \nfor fast display on the Web. \n”
示例1 :“ Adobe Acrobat PDF文件\nAdobe®可移植文档格式(PDF)是一种通用文件格式,可以保留所有\ n所有源文档的字体,格式,颜色和图形,而与创建该文档的\ n应用程序和平台无关它。 \ nAdobe PDF是电子文档分发的理想格式,因为它克服了电子文件共享中常见的\ n问题。 \ n * \ n任何人都可以在任何地方打开PDF文件。 您只需要免费的Adobe Acrobat \ nReader。 其他文件格式的收件人有时无法打开文件,因为它们没有用于创建文档的应用程序。 \ n * \ nPDF文件始终可以在任何打印设备上正确打印。 \ n * \ nPDF文件始终显示与创建时完全相同的格式,而与字体,软件和\ n操作系统无关。 字体和图形不会由于平台,软件和\ n版本不兼容而丢失。 \ n * \ n免费的Acrobat Reader易于下载,并且可由\ nanyone免费分发。 \ n * \ n紧凑的PDF文件小于其源文件,并一次下载一个页面,以便在网络上快速显示。 \ n”
Sample 2: “Lorem ipsum \nLorem ipsum dolor sit amet, consectetur adipiscing \nelit. Nunc ac faucibus odio. \nVestibulum neque massa, scelerisque sit amet ligula eu, congue molestie mi. Praesent ut\nvarius sem. Nullam at porttitor arcu, nec lacinia nisi. Ut ac dolor vitae odio interdum\ncondimentum. Vivamus dapibus sodales ex, vitae malesuada ipsum cursus\nconvallis. Maecenas sed egestas nulla, ac condimentum orci. Mauris diam felis,\nvulputate ac suscipit et, iaculis non est. Curabitur semper arcu ac ligula semper, nec luctus\nnisl blandit. Integer lacinia ante ac libero lobortis imperdiet. Nullam mollis convallis ipsum,\nac accumsan nunc vehicula vitae. Nulla eget justo in felis tristique fringilla. Morbi sit amet\ntortor quis risus auctor condimentum. Morbi in ullamcorper elit. Nulla iaculis tellus sit amet\nmauris tempus fringilla.\nMaecenas mauris lectus, lobortis et purus mattis, blandit dictum tellus.\n*\nMaecenas non lorem quis tellus placerat varius. \n*\nNulla facilisi. \n*\nAenean congue fringilla justo ut aliquam. \n*\nMauris id ex erat. Nunc vulputate neque vitae justo facilisis, non condimentum ante\nsagittis. \n*\nMorbi viverra semper lorem nec molestie. \n*\nMaecenas tincidunt est efficitur ligula euismod, sit amet ornare est vulputate.\nRow 1\nRow 2\nRow 3\nRow 4\n0\n2\n4\n6\n8\n10\n12\nColumn 1\nColumn 2\nColumn 3\n”
示例2 :“ Lorem ipsum \ nLorem ipsum dolor坐着,安全贴合\ nelit。 Nunc ac faucibus dioo。 \ n前庭马萨诸塞州,坐在amet ligula eu的celesqueque,congue s鼠mi。 ut \ nvarius sem。 Nullam at Porttitor arcu,nec lacinia nisi。 统一的生活条件。 Vivamus dapibus sodales前,履历书\ nconvallis。 Maecenas s eg egesta nulla,ac调味品。 毛里斯·迪亚斯·费利斯(Mauris diam felis),\ n不知所措等等,科拉比斯·森Perl(curabitur semper)阿库斯·埃·普利古拉·森Perl(nec luctus \ nnisl blandit)。 整数cincin ac ero libortis imperdiet。 Nullam mollis convallis ipsum,\ nac accumsan nunc vehicula vitae。 Nulla eget justo in felis tristique fringilla。 莫比(Morbi)坐着。 Morbi在ullamcorper精英中 Nulla iaculistellus坐在amet \ nmauris tempus fringilla。\ nMaecenas mauris lectus,Lobortis et purus mattis,Blandit dictumtellus。\ n * \ nMaecenas non lorem quistellus placerat varius。 \ n * \ nNulla facilisi。 \ n * \ nAenean congue fringilla justo ut aliquam。 \ n * \ nMauris ID已过期。 Nunc vulputate neque vitae justo facilisis,非调味品前\ n矢状。 \ n * \ n莫尔比·维维拉·森珀·洛雷姆·莫斯蒂。 \ n * \ n雌性猕猴的最佳功效,坐在寻常的小窝中。\ n行1 \ n行2 \ n行3 \ n行4 \ n0 \ n2 \ n4 \ n6 \ n8 \ n10 \ n12 \ n列1 \ n列2 \ n第3列\ n”
Sample 3: “Example table \nThis is an example of a data table. \nDisability \nCategory \nParticipants \nBallots \nCompleted \nBallots \nIncomplete/ \nTerminated \nResults \nAccuracy \nTime to \ncomplete \nBlind \n5 \n1 \n4 \n34.5%, n=1 \n1199 sec, n=1 \nLow Vision \n5 \n2 \n3 \n98.3% n=2 \n(97.7%, n=3) \n1716 sec, n=3 \n(1934 sec, n=2) \nDexterity \n5 \n4 \n1 \n98.3%, n=4 \n1672.1 sec, n=4 \nMobility \n3 \n3 \n0 \n95.4%, n=3 \n1416 sec, n=3 \n \n”
示例3 :“示例表\ n这是数据表的示例。 \ n残障\ n类别\ n参与者\ nBallots \ n已完成\ nBallots \ n未完成/ \ n已终止\ n结果\ n准确度\ n到\ ncomplete的时间\ nBlind \ n5 \ n1 \ n4 \ n34.5%,n = 1 \ n1199 sec,n = 1 \ n低视力\ n5 \ n2 \ n3 \ n98.3%n = 2 \ n(97.7%,n = 3)\ n1716秒,n = 3 \ n(1934秒,n = 2)\ n灵活性\ n5 \ n4 \ n1 \ n98.3%,n = 4 \ n1672.1秒,n = 4 \ n移动性\ n3 \ n3 \ n0 \ n95.4%,n = 3 \ n1416秒,n = 3 \ n \ n”
This looks pretty much the same as for pdfminer. Again, the text from every document could be extracted. With different parameters like dict, rawdict or xml one can obtain different output formats with additional information like text coordinates, font and text level like text block or text line.
这看起来与pdfminer几乎相同。 同样,可以提取每个文档中的文本。 使用诸如dict , rawdict或xml类的不同参数,可以获得具有其他信息(如文本坐标,字体和文本级别,如文本块或文本行)的不同输出格式。
结论 (Conclusion)
To sum up, there are different tools with different methodologies and functionalities available in python for PDF text extraction. Since PDF documents are quite messy, I would always go for libraries based on an existing PDF viewer instead of pure Python development. Nevertheless, there are some advantages and disadvantages of using one over the other. If you can, retrieve the information you try to extract in a more direct way, circumventing the writing to and extracting from PDF.
综上所述,python中提供了具有不同方法和功能的不同工具,可用于提取PDF文本。 由于PDF文档非常混乱,因此我总是选择基于现有PDF查看器的库,而不是基于纯Python开发的库。 然而,使用一个相对于另一个存在一些优点和缺点。 如果可以的话,以更直接的方式检索尝试提取的信息,从而避免了对PDF的撰写和从PDF中的提取。
Originally published at https://dida.do.
最初发布在 https://dida.do 。
翻译自: https://medium.com/dida-machine-learning/how-to-extract-text-from-pdf-files-16df0830aa66
提取pdf文件中的图片
