期刊:工程科学学报
引用:陈鹏,李擎,张德政,杨宇航,蔡铮,陆子怡.多模态学习方法综述[J/OL].工程科学学报:1-13[2020-05-18].https://doi-org-443.wvpn.hrbeu.edu.cn/10.13374/j.issn2095-9389.2019.03.21.003.
摘要:大数据是多源异构的。在信息技术飞速发展的今天,多模态数据已成为近来数据资源的主要形式。研究多模态 学习方法,赋予计算机理解多源异构海量数据的能力具有重要价值。本文归纳了多模态的定义与多模态学习的基本任 务,介绍了多模态学习的认知机理与发展过程。在此基础上,重点综述了多模态统计学习方法与深度学习方法。此 外,本文系统归纳了近两年较为新颖的基于对抗学习的跨模态匹配与生成技术。本文总结了多模态学习的主要形式, 并对未来可能的研究方向进行思考与展望。
早在公元前 4 世纪,多模态的相关概念和理论即被哲学家和艺术家所提出,用以定义融合不同内 容的表达形式与修辞方法[1-2]。20 世纪以来,这一概念被语言学家更为广泛地应用于教育学和认知科学领域[3]。近年来,描述相同、相关对象的多源数据在互联网场景中呈指数级增长,多模态已成为新 时期信息资源的主要形式。
人类的认知过程是多模态的。个体对场景进行感知时往往能快速地接受视觉、听觉乃至嗅觉、触觉的信号,进而对其进行融合处理和语义理解。多模态机器学习方法更贴近人类认识世界的形式。本 文首先介绍了多模态的概念与基本任务,分析了多模态认知学习的起源与发展。结合互联网大数据形态,本文重点综述了多模态统计学习方法、深度学习方法与对抗学习方法。
1 多模态学习的定义、基本任务与发展过程
- 多模态学习的定义
本文主要采用了新加坡国立大学 O'Halloran 对“模态”的定义,即相较于图像、语音、文本等多 媒体(Multi-media)数据划分形式,“模态”是一个更为细粒度的概念,同一媒介下可存在不同的模 态[4]。概括来说,“多模态”可能有以下三种形式。
- 描述同一对象的多媒体数据。如互联网环境下描述某一特定对象的视频、图片、语音、文本 等信息。图 1 即为典型的多模态信息形式。
- 来自不同传感器的同一类媒体数据。如医学影像学中不同的检查设备所产生的图像数据,包括B超(B-Scan ultrasonography)、计算机断层扫描(CT)、核磁共振等;物联网背景下不同传感器所检测到的同一对象数据等。
- 具有不同的数据结构特点、表示形式的表意符号与信息。如描述同一对象的结构化、非结构化的数据单元;描述同一数学概念的公式、逻辑符号、函数图及解释性文本;描述同一语义的词向量、词袋、知识图谱以及其它语义符号单元等[5]。


因此,从语义感知的角度切入,多模态数据涉及不同的感知通道如视觉、听觉、触觉、嗅觉所接收到的信息;在数据层面理解,多模态数据则可被看作多种数据类型的组合,如图片、数值、文本、 符号、音频、时间序列,或者集合、树、图等不同数据结构所组成的复合数据形式,乃至来自不同数 据库、不同知识库的各种信息资源的组合。对多源异构数据的挖掘分析可被理解为“多模态学习 (Multimodal machine learning)”,其相关概念有“多视角学习”和“多传感器信息融合”。来自不 同数据源、具有不同结构特征的数据被称作多视角数据,每个数据源、每种数据类型均可被看作一个视角。卡内基梅隆大学的 Morency 在 ACL2017(The 55th Annual Meeting of the Association for Computational Linguistics,CCF A 类会议)的 Tutorial 报告[6]中,将大量的多视角学习方法归类为多模态机器学习算法。笔者认为,“多视角学习”强调对数据“视角”的归纳和分析,“多模态学习”则侧重“模态”感知和通道。“视角”和“模态”的概念是相通的,一个模态即可被视作一个视角。“多传感器信息融合(Multi-sensor information fusion)”为在物理层面与“多模态学习”相关的术 语,即对不同传感器采集的数据进行综合利用,其典型应用场景有物联网、自动驾驶等。
- 多模态机器学习的基本任务
多模态学习的基本任务可包括以下几个方面。
多源数据分类:单模态的分类问题只关注对一类特定数据的分析和处理,相较于单一通道,多模态数据更接近大数据背景下信息流真实的形态,具有全面性和复杂性。
多模态情感分析:情感分析问题的本质也是分类问题,与常规分类问题不同,情感分类问题所提取的特征往往带有明确的情绪信号;从多模态的角度分析,网络社交场景中所衍生的大量图片、文 本、表情符号及音频信息均带有情感倾向。
多模态语义计算:语义分析是对数据更为高层次的处理,理想状态下,计算机能够处理一个特定场景下不同数据的概念关系、逻辑结构,进而理解不同数据中隐含的高层语义;对这种高层语义的理解是有效进行推理决策的前提。
跨模态样本匹配:现阶段,最常见的跨模态信息匹配即为图像、文本的匹配,如 Flickr30k[7]数据 集中的实例;图像文本匹配任务为较为复杂的机器学习任务,这一任务的核心在于分别对图像、文本的特征进行合理表示、编码,进而准确度量其相似性。
跨模态检索:在检索任务中,除了实现匹配外,还要求快速的响应速度以及正确的排序;多模态 信息检索通过对异构数据进行加工,如直接对图片进行语义分析,在有效特征匹配的情况下对图片采用基于内容的自动检索形式;为适应快速检索的需要,哈希方法被引入多模态信息检索任务中,跨模态哈希方法将不同模态的高维数据映射到低维的海明空间,有效减小了数据存储空间,提高了计算速度。
跨模态样本生成:跨模态生成任务可以有效构造多模态训练数据,同时有助于提高跨模态匹配与翻译的效果,目前由图像到文本(如图像语义自动标注)、图像到图像(如图片风格迁移)的生成任 务发展较为成熟,由文本到图像的生成任务则较为新颖。
多模态人机对话:即在基本对话(文本模态)生成任务的基础上,进一步对人的表情、语调、姿 势等多模态信息进行采集,采用模态融合的方法对多模态信号进行分析处理。多模态人机对话的理想状态是在有效感知多模态信号的前提下给出拟人化的多模态输出,构建更为智能、沟通更加顺畅的人机交互形式。
多模态信息融合:多模态融合要求对多源数据进行综合有效地筛选和利用,实现集成化感知与决策的目的,常见的信息融合方式有物理层融合、特征层融合、决策层融合几个类型。物理层融合指在感知的第一阶段,在传感器层级对采集到的数据进行融合处理,这种处理方式可被概括为多传感器信 息融合(Multi-sensor information fusion),是工业生产场景中极为常见的信息融合方法;特征层融合 指在特征抽取和表达的层级对信息进行融合,如对同一场景中不容摄像头采集到的图像采用相同的特征表达形式,进而进行相应的叠加计算;决策层融合指对不同模态的感知模型所输出的结果进行融合,这种融合方式具有较好的抗干扰性能,对于传感器性能和种类要求相对不高,但具有较大的信息损耗。
- 多模态机器学习的发展——从符号计算到深度学习
随着计算机技术的发展,多模态认知的概念从传统的教育学、心理学、语言学的范畴拓展至信息科学领域。上世纪 60~70 年代,科学家利用符号和逻辑结构模拟人类的思维逻辑,如利用语法树分析文本信息[8],利用规则库构建专家决策系统[9]。由于人类认知过程的复杂性与流动性,有效、实时地 制定逻辑结构和规则形式成为制约“符号主义”认知智能的主要因素。
上世纪 80 年代至 21 世纪初,统计机器学习方法在智能信息处理的各个领域取得了令人瞩目的成就。Cortes 和 Vapnik 提出的支持向量机模型可以快速、准确地处理高维、非线性的模式识别问 题[10];Pearl 所构建的概率图模型赋予了计算机依据概率推理的能力[11];进一步地,Jelinek 将信息论 与隐马尔科夫模型引入语音识别与自然语言处理领域,奠定了近代统计自然语言处理学派的根基,使 自然语言处理的工程化应用成为可能[12]。
在这一阶段,受麦格克效应的启发[13],许多计算机科学家致力于构建基于视觉信号和声音信号的 多模态语音识别系统,如唇语-声音语音识别系统[14],有效提高了识别准确率。这一时期的多模态信息系统还被应用于人机交互场景,如 Fels 等提出的 Glove-talk 框架(1992 年)采用 5 个多层神经网络实现对手势、声音、语义的机器感知[15]。这一神经网络模型的结构还比较简单,其采用的后向传播 训练方法易出现过拟合现象,因而无法对复杂的大规模数据进行处理。
2010 年至今,随着 Dropout 训练模式[16]的提出、Relu 激活函数[17]的引入乃至深度残差结构[18]对网络的调整,深度神经网络在许多单一模态的感知型机器学习任务中取得了优于传统方法的效果。以 AlexNet[19]、ResNet[18]、GoogleNet[20]为代表的改进卷积神经网络(Convolutional neural network, CNN)模型在 ImageNet[21]图像分类任务中甚至取得了超过人类的表现;长短记忆模型(Long short term memory,LSTM)和条件随机场(Conditional random field,CRF)的组合结构在自然语言序列标 注特别是命名实体识别任务中实现了极为成功的商业化、工程化应用[22]。多模态深度学习已成为人工 智能领域的热点问题。Ngiam 等在 ICML2011(28th International Conference on Machine Learning)的 大会论文中对多模态深度学习进行了前瞻性的综述,而这一阶段的深度学习主要网络结构为深度玻尔 兹曼机(Deep boltzmann machines)[23]。卡内基梅隆大学的 Baltrusaitis 等也开展了大量的多模态深度 学习研究[24]。
在国内,北京交通大学的 Zhang 等[25],北京邮电大学的 Wang 等在跨模态信息匹配和检索领域开展了许多卓有成效的工作[26];清华大学的 Liu 等对视觉模态、触觉模态的数据展开研究,并将其应用于机器人综合感知场景[27];清华大学的 Fu 等则在图像语义标注领域取得了若干突破[28]。
在人工智能技术突飞猛进的今天,开展数据驱动的多模态学习方法研究,能够取得更为全面有效 的解决方案。对多模态数据的分析处理可采用机器学习手段来完成,处理多模态数据的机器学习方法即可被视为多模态学习方法。机器学习是从数据中优化算法的一种人工智能手段,它涵盖统计学习与 深度学习等方法。近几年,对抗学习技术被广泛地应用于跨模态匹配和生成任务中,并取得了令人瞩 目的效果。后文将分别对多模态统计学习方法、多模态深度学习方法、多模态对抗学习方法进行综述与分析。
2 多模态统计学习方法
广义的统计学习(Statistical learning)即采用统计学的相关理论,赋予计算机处理数据能力的机器学习方法。如统计学家和数学家 Breiman 提出的随机森林(Random forest)算法[29],Breiman 和 Friedman 等一同提出的分类回归树(Classification and regression trees, CART)算法[30],Cortes 和 Vapnik 提出的支持向量机(Support vector machine, SVM)算法[10]等。统计学习方法和经典机器学习方法在概念上是基本重合的。上述统计学习界的领军学者分别在不同角度完善了该领域的基本概念和 理论体系。如 Breiman 在数据建模和算法建模两个角度重新解读了机器学习的建模方式,即数据建模 方式往往预设数据符合某种分布形式,如线性回归、逻辑回归等,进而进行参数估计和假设推断;而算法建模则试图通过算法去直接寻找映射函数以达到由输入预测输出的目的,如决策树与神经网络结 构[31]。Vapnik 和 Cervonenkis 归纳了他的 VC(Vapnik–Chervonenkis dimension)维理论,不仅对典型的分类器模型与这些模型所能区分的集合大小进行系统总结,还给出了对模型最大分类能力进行分析的有效方法[32]。
受计算资源等因素的制约,统计学习方法的处理样本往往是中小规模的数据集,在许多任务(如 图像处理和自然语言处理任务)的处理过程中,需要人为参与的特征处理过程。多模态机器学习技术 是伴随着统计学习理论的完备、大量新颖有效的统计学习方法的提出逐渐发展的。本节将结合多模态数据的特点,对相应的统计学习方法进行介绍。
- 核学习方法与多核学习
核学习(Kernel learning)方法是一种将低维不可分样本通过核映射的方式映射到高维非线性空间,实现对样本有效分类的方法[33],如图 2 所示。核学习方法是支持向量机(SVM)算法的有力理 论支撑,也随着支持向量机的广泛应用被研究者和工程技术人员所关注。事实上,早在 1909 年,英国数学家 Mercer 即提出了其重要的 Mercer 定理,即任何半正定的函数都可作为核函数,奠定了核学 习方法的理论基础[34]。在 Mercer 定理的基础上,波兰裔美国数学家 Aronszajn 进一步发展了再生核希尔伯特空间理论,使其能够被引入到模式识别任务中[35]。
多核学习方法为不同模态的数据和属性选取不同的核函数,进而采用特定方法对不同核函数进行融合。目前,随着多核学习方法被深入研究并应用于不同的场景,不同形式的核函数及其改进形式被提出。如对于数值型数据的分类问题,高斯核具有较好的处理效果[36];字符串核对序列型问题的分类处理(如文本、音频、基因表达等)具有较大的优势[37];对于人脸识别问题和行人识别问题,则可以采用直方图交叉核[38]。
多核学习方法可以较好地处理异构数据的分类和识别问题。早期的多核数据融合方法多采用对不同核进行线性叠加组合的形式,为生物医学工程领域许多问题的求解(如基因功能分析、蛋白质功能 预测与定位等)提供了有力的解决方案[39]。线性叠加的核融合方式具有机理简单、可解释性强、计算 速度快等优势,但其叠加系数往往较难确定,在叠加的同时可能造成一定的信息损失。文献[40]提出采用“核组合”的方式解决该问题,即将不同的核矩阵组合,构成一个更高维的矩阵作为新的核矩阵 完成映射与分类的任务。文献[41]提出了一种改进的判别函数,并采用梯度下降法优化该表达式中的核参数。文献[42]则采用粒子群优化算法对核参数进行优化选择。
- 典型相关性分析
典型相关性分析(Canonical correlation analysis, CCA)是一种用途广泛的统计学分析算法,由 Hotelling 于 1935 年提出[43],并由 Cooley 和 Lohnes 推动其发展[44]。在多模态领域,CCA 被广泛地应 用于度量两种模态信息之间的相关特征,并在计算中尽可能保持这种相关性。
CCA 算法的本质是一种线性映射,采用 CCA 对复杂的非线性多模态信息进行拟合可能造成信息的损耗。在 CCA 的基础上,Akaho 提出了与核方法结合的非线性的 Kernel CCA 算法[45]。CCA 的其他改进形式还有判别典型相关分析(Discriminant canonical correlation analysis, DCCA)[46]、稀疏典型 相关分析(Sparse discriminant canonical correlation analysis, SCCA)等[47]。
- 共享子空间学习
在高层语义空间中,多源数据具有较强的相关性。对于底层的特征表示,不同来源的数据往往具有较大差别。共享子空间学习对多源数据的相关关系进行挖掘,得到多模态特征的一致性表示,如图 3 所示。
共享子空间学习可通过投影的方式实现,最常见的投影方法即 2.2 节中给出的 CCA 方法及其改进形式。SVM-2K 算法是投影型共享子空间学习的典型算法,该算法结合 SVM 与 Kernel CCA[45]对两个模态的特征进行有效映射、表示和整合[48]。张量分析及因子分解也是典型的共享子空间学习方法, 这种方法的主要思想是将一个模态的信息看作一阶张量,通过因子分解、判别式分析等形式实现降维 并对特征进行相关表示,其典型方法为联合共享非负矩阵分解(Joint shared nnnegative matrix factorization, JSNMF)算法[49]。从任务驱动的角度来分类,典型的共享子空间学习方法还有基于多任 务学习的共享子空间学习方法[50]、基于多标签学习的共享子空间学习方法等[51]。
基于统计学习的子空间投影的形式相对简单,难以处理较为复杂的语义感知任务,对于相似模态的数据(如不同传感器的图像数据)优势明显,但在跨度较大的模态上表现不佳。近年来,随着深度 学习的兴起,许多研究者将深度学习模型应用于多源信息处理领域。从结果上来看,绝大多数的深度学习多源信息处理方法将不同模态的数据通过深度神经网络特征学习映射到了同一个共享子空间,因此深度学习方法也可被视为共享子空间学习。对该方法将在第三部分中作进一步的介绍。
- 协同训练方法
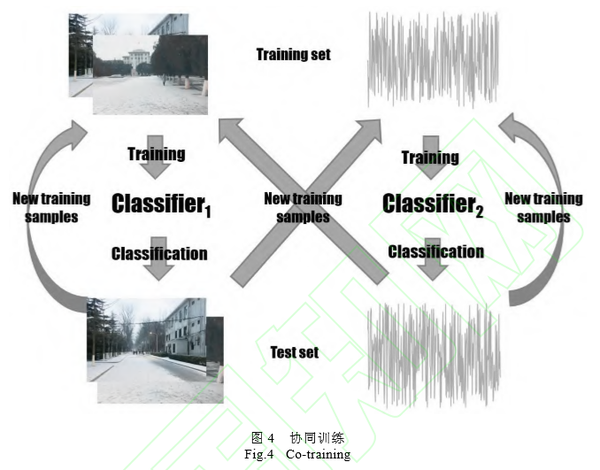
协同训练(Co-training)是一种典型的弱监督学习方法,该方法由 Blum 和 Mitchel 于 1998 年提出[52]。在多模态数据处理领域,它的大致思想是分别采用两个模态的有标签数据 X1、X2 训练两个分 类器,进而用这两个分类器对各自模态内的无标签数据进行处理。在此基础上,将分类结果中达到一 定置信度的样本作为训练集的补充,扩大训练集规模,进一步对分类器进行训练。在满足一定停止条件,如达到一定迭代代数后,将两个分类器的训练数据进行交换,即采用 X1模态中的数据对分类器 2 (Classifier2)进行训练,同时采用 X2中的数据对分类器 1(Classifier1)进行训练。协同训练的原理图 如图 4 所示。这种联合训练方法使分类器学习到不同数据源中尽可能多的知识,同时具备了较好的泛 化性能。协同训练假定数据集满足三个条件:1)数据之间相互独立;2)单一模态内的数据均能完整地对对象进行描述;3)存在充分的样本对分类器进行训练。然而在实际的应用场景中,往往很难满足上述的条件。研究者提出了多种改进手段以提升协同训练的性能。
3 多模态深度学习方法
基本的神经网络模型(浅层结构)可被归纳为一种特殊的统计学习方法。不同于支持向量机的核技巧采用核映射转化问题,神经网络结构直接采用非线性映射(激活函数)的形式拟合数据分布规 律。神经网络是深度学习的起源,后者是对采用深度神经网络完成机器学习任务的各种机器学习方法 的概括。近年来,深度学习方法已成为推动人工智能技术的主要力量。隐层大于 1 的神经网络即可被 看作深度神经网络,常见的深度神经网络模型有卷积神经网络(Convolutional neural networks, CNN)[56]、循环神经网络(Recurrent neural networks, RNN)[57]、深度信念网络(Deep belief networks, DBN)[58]等。深度学习的发展建立在统计学习的高度繁荣之上,得益于不断发展的互联网 技术积累了大量的数据资源,以及更为普及的高性能计算硬件。有别于统计学习依赖于专家知识来确定特征的限制,深度学习模型可以自动地在数据中学习特征表示,从而能够对海量数据进行处理,在一定程度上实现端到端的机器学习系统。
- 卷积神经网络与图像处理
Lécun 于 1998 年提出了经典卷积神经网络的雏形 LeNet,并将其应用于手写字符识别[56]。针对 CNN 训练过程中的过拟合问题,Srivastava 等提出了 Dropout 方法,即在网络结构中以一定概率将某 些神经元暂时丢弃[16]。这种方法被应用于 AlexNet[19]中。在 AlexNet 之后,改进了的 CNN 结构不断刷新 ImageNet 图像分类的记录。如牛津大学的 VGG (Visual geometry group)[59]模型和 Google 公司的 Inception[20]系列模型,在增加 CNN 网络层数的同时设计了精巧丰富的卷积核结构,从而降低参数数 量,提高训练速度。微软公司的ResNet[40]模型引入残差结构,有效解决了梯度消失问题。在图像分 类之外的计算机视觉任务中,CNN 同样取得了优于经典图像处理方法的效果。如目标检测(Object detection)领域的 Yolo(You only look once)模型[60],语义分割(Semantic segmentation)领域的 FCNN(Fully convolutional networks)模型[61]等。有理由认为,CNN 及其改进形式能够较好地对视觉 模态特征进行表示和处理。
- 循环神经网络与自然语言理解
近年来,自然语言处理域的研究热点正在从经典的统计学习方法向深度学习方法转变。典型的深 度文本处理模型即循环神经网络(Recurrent neural network, RNN)结构[57]。该结构源于蒙特利尔大学 Bengio 等于 2003 年提出的神经语言模型[65]。神经语言模型实现了语言最基本的单元——词的向量化表示。受文献[65]启发,C&W 词向量[66]、Word2Vec 词向量[67]等文本表示模型相继被提出。
神经语言模型的提出使文本转化为稠密的向量成为可能,已成为目前处理自然语言任务的主流算 法。值得一提的是,文献[65]至[67]中的文本表示及学习方法均为较为浅层的结构,其价值在于通过弱监督、无监督的手段得到文本的表示形式,进而供较为深层的神经网络机器学习模型进行挖掘分析。
在神经语言模型的基础上,大量的深度神经网络结构被改良并进一步应用于自然语言处理任务, 如 RNN[57]、LTSM [68]被广泛地应用于文本分类[69]、实体识别[22]等任务。由于 RNN 能够出色地学习 序列样本中不同时刻的信息及其相互关系,RNN 结构在机器翻译、对话生成等序列分析及序列生成 任务中的优势极为突出[70]。RNN 的主要改进形式为 LSTM[68]和 GRU(Gated recurrent unit)[71]。这些 变体在 RNN 中添加了特殊的“门”结构来判断信息的价值,进而模拟人类大脑的记忆和遗忘过程。 在 LSTM 的基础上,其双向形式 BiLSTM[72]、基于 Attention 的 BiLSTM[73]相继被提出。相较于经典 的 RNN[57],LSTM[68]和 GRU[71]可以更有效地对序列进行建模,建立更为精确的语义依赖关系。在合理标注的前提下,RNN 结构在自然语言实体识别任务中已实现了极为出色的工程应用,其典型算法 为 LSTM+CRF,即通过 LSTM 提取深度特征,用条件随机场(Conditional random field,CRF)模型 进行文本序列标注[22]。
- 面向多模态数据的深度学习
通过上文分析,可以发现深度学习模型具有更好的跨模态适应性。多模态深度学习始于 Ngiam 等发表于 ICML 2011 的《Multimodal Deep Learning》,文中的数据来源为视觉模态(唇语)和音频模态,其构建的深度学习模型以玻尔兹曼机(Restricted boltzmann machine,RBM)为基本单元,通过对视频、音频数据进行编码、联合表示、学习和重构,实现对字母、数字的识别[23]。
近年来,已有很多卓有成效的多模态深度学习方法被提出。如文献[76]在学习机制上进行改良, 即在对训练集进行学习时,不再构建图片-句子标签之间的映射关系,而是将图片中的对象和句子中 的实体匹配起来,首先对图片采取目标检测的任务,进而学习单词和细粒度图像区域之间的关系,在 此基础上生成标注句子。这一方式简化了对 Image-Caption 任务的训练集标注需求,即从句子简化为 单词。文献[77]结合 LSTM 的特性,构建了能够对多幅图像或视频内容进行理解和描述的深度神经网络框架,实现对视觉序列的文本描述。文献[78]设计了 CNN-LSTM 混合编码器对数据进行编码,进 而采用排序损失(Pairwise ranking loss)函数对数据进行训练。文献[79]借鉴了在基于 RNN 的机器翻译任务中的研究进展,用 CNN 替代 RNN 作为图片的编码器。在设计模型框架的同时,该文还提出了 得到相关细节描述的概率公式。文献[80]设计了基于图片的问答模型,该模型能够根据 CNN 编码的 图片和问题句子,生成正确的问题答案。文献[81]重点研究了采用 CNN 模型的基于内容的图片检索 问题,并分析了深度卷积神经网络对高维语义特征的有效表达能力。文献[82]则采用多模态深度学习 框架,通过构建多个 LSTM 结构处理情感分类问题。文献[83]提出一种多模态无监督机器翻译方法, 采用描述同一内容的图片链接跨语种语料,实现语义对应与融合。文献[84]采用强化学习的手段对文 本和视觉场景进行匹配,进而对自动驾驶决策进行推理。
4 结论与展望
大数据背景下,多模态数据对同一对象的描述存在形式多源异构、内在语义一致的特点。不同的 模态形式分别描述对象在某一特定角度下的特征。随着机器学习技术的发展,多模态学习领域的研究 热点逐渐从经典的统计学习方法转移到深度学习方法。对于视觉模态,CNN 逐渐成为最有效的特征表示方法;对于文本模态及相关、类似的序列预测任务,LSTM 也逐渐取代概率图模型,取得主导地位。而对抗学习的兴起使得跨模态任务更为多样化。
对于多模态学习方法的研究可以从以下几个方向进一步展开:(1)对不同模态的样本进行更为精细 化的特征表示,实现有效的跨模态匹配,利用模态互补构建更为完整的特征描述体系;(2)克服学习样 本数量的限制,研究弱监督、无监督的多模态学习方法;针对该问题,对抗学习方法是可行的解决方 案之一;(3)研究有效的模型融合框架,一方面是组合不同的算法以取得高质量的数据分析结果,另一 方面是用模型融合指导对多模态数据的融合;(4)研究效果更为真实、性能更加稳定的跨模态生成方法;(5)应用背景从通用领域向垂直领域拓展,针对特定的应用场景(如医疗场景)实现可行的解决方案。












