点击上方『早起Python』关注并星标
第一时间接收最新Python干货!

系列导读
Python办公自动化|从Word到Excel Python办公自动化|从Excel到Word Python办公自动化|批量合并PDF
大家好,又到了Python办公自动化专题
要说在工作中最让人头疼的就是用同样的方式处理一堆文件夹中文件,这并不难,但就是繁。所以在遇到机械式的操作时一定要记得使用Python来合理偷懒!今天我将以处理微博热搜数据来示例如何使用Python批量处理文件夹中的文件,主要将涉及:
Python批量读取不同文件夹(⭐⭐⭐)
Pandas数据处理(⭐⭐)
Python操作Markdown文件(⭐)
需求分析
首先来说明一下需要完成的任务,下面是我们的文件夹结构
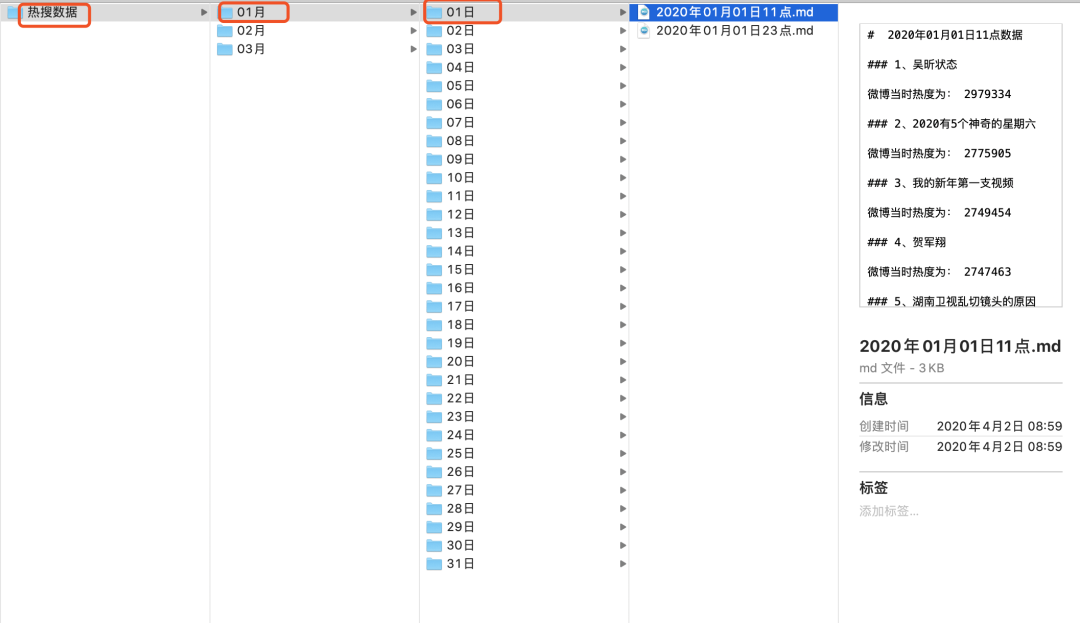

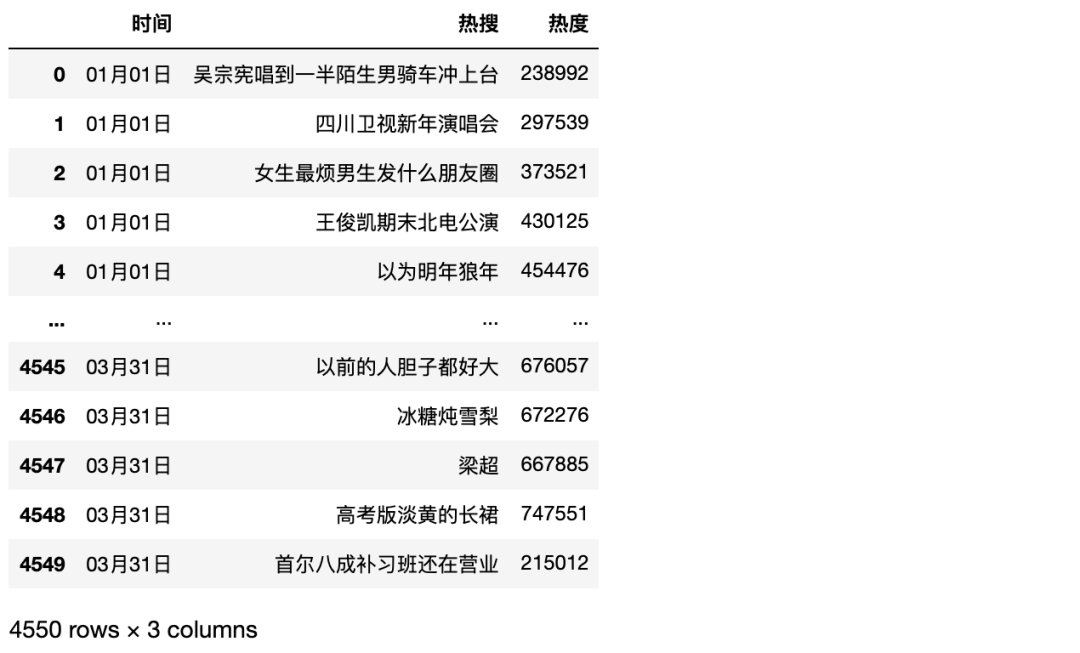
Python实现
在操作之前我们来思考一下如何使用Python实现,其实和手动的过程类似:先读取全部文件,再对每一天的数据处理、保存。所以第一步就是将我们需要的全部文件路径提取出来,首先导入相关库
importpandas读取全部文件名的方法有很多比如使用OS模块

os.path 使用 Pathlib 来操作,三行代码就能搞定,看注释 frompathlibimportPath
p=Path("/Users/liuhuanshuo/Desktop/热搜数据/")#初始化构造Path对象
FileList=list(p.glob("**/*.md"))#得到所有的markdown文件来看下结果
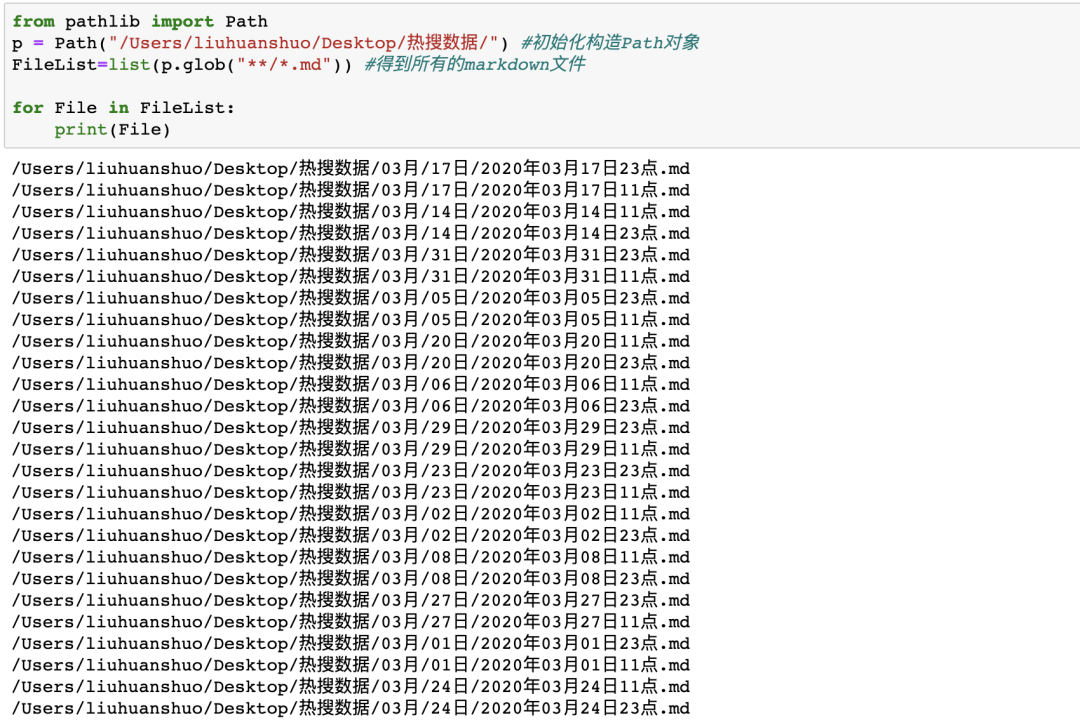
成功读取了热搜数据下多层文件夹中的全部md文件!但是新的问题来了,每天有两条热搜汇总,一个11点一个23点,考虑到会有重合数据所以我们在处理之前先进行去重,而这就简单了,不管使用正则表达式还是按照奇偶位置提取都行,这里我是用lambda表达式一行代码搞定
filelist=list(filter(lambdax:str(x).find("23点")>=0,FileList))现在我们每天就只剩下23点的热搜数据,虽然是markdown文件,但是Python依旧能够轻松处理,我们打开其中一个来看看
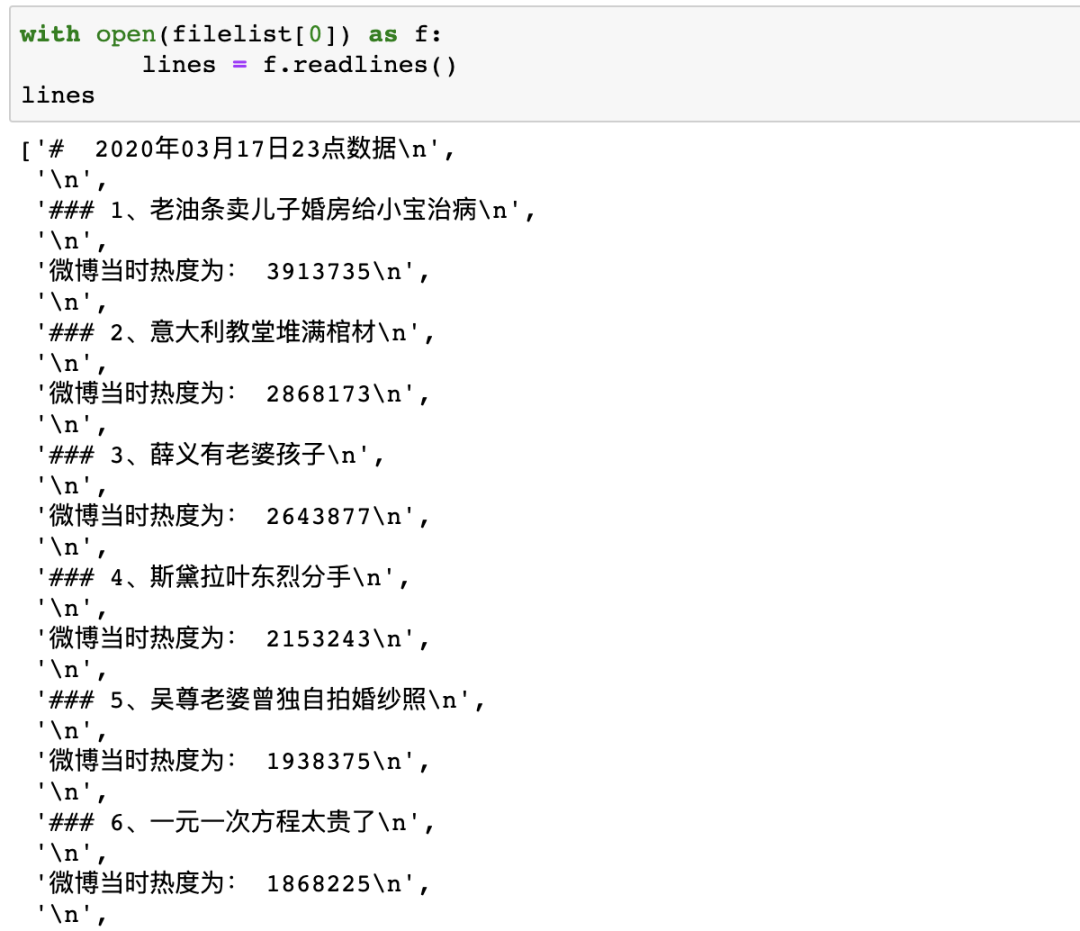
withopen(file)asf:
lines=f.readlines()
lines=[i.strip()foriinlines]#去除空字符
data=list(filter(None,lines))
deldata[0]
data=data[0:100]
date=re.findall('年(.+)2',str(file))[0]
content=data[::2]#奇偶分割
rank=data[1::2]
#提取内容与排名
foriinrange(len(content)):
content[i]=re.findall('、(.+)',content[i])[0]
foriinrange(len(rank)):
rank[i]=re.findall('(.+)',rank[i])[0]最后只需要写一个循环遍历每一天的文件并进行清洗,再创建一个DataFrame用于存储每天的数据即可
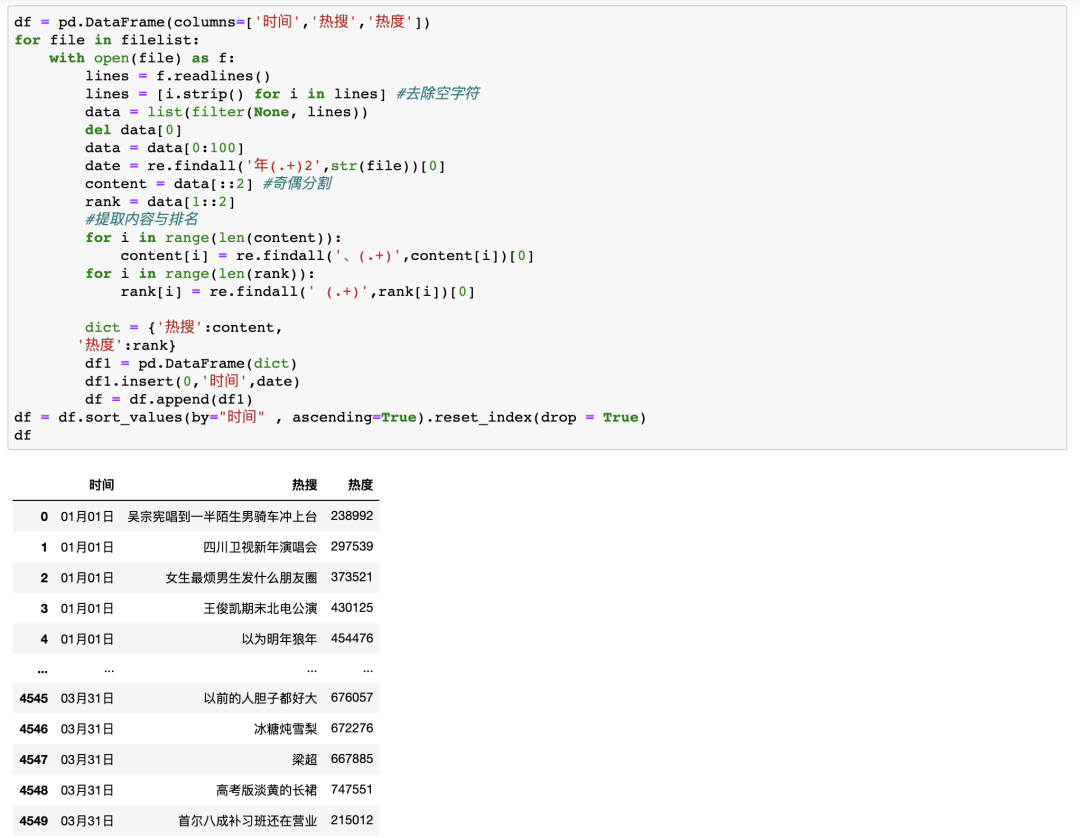
可以看到,并没有使用太复杂的代码就成功实现了我们的需求!
结束语
以上就是使用Python再一次解放双手并成功偷懒的案例,可能读取Markdown文件在你的日常工作中并用不到,但是通过本案例希望你能学会如何批量处理文件夹,批量读取清洗数据。更重要的是在你的工作学习中,遇到需要重复操作的任务时,是否能够想起使用Python来自动化解决!拜拜,我们下个案例见~
注1: 本文使用的数据与源码可在后台回复0511获取
注2: 以上代码需在Python3环境下运行
如果喜欢Python你自动化系列请点击在看并多多转发~

往期精选(?猛戳可查看) 在B站外,我看到了另一批“后浪”!为什么你会被限制登录网页版微信?一道Leetcode数据库题的三种解法|送书收藏|我的Mysql学习笔记开始你的第二个机器学习项目开始你的第一个机器学习项目
在B站外,我看到了另一批“后浪”!为什么你会被限制登录网页版微信?一道Leetcode数据库题的三种解法|送书收藏|我的Mysql学习笔记开始你的第二个机器学习项目开始你的第一个机器学习项目


