网页:
注意网页标签必须关闭,不可以单个标签
Title网页controller
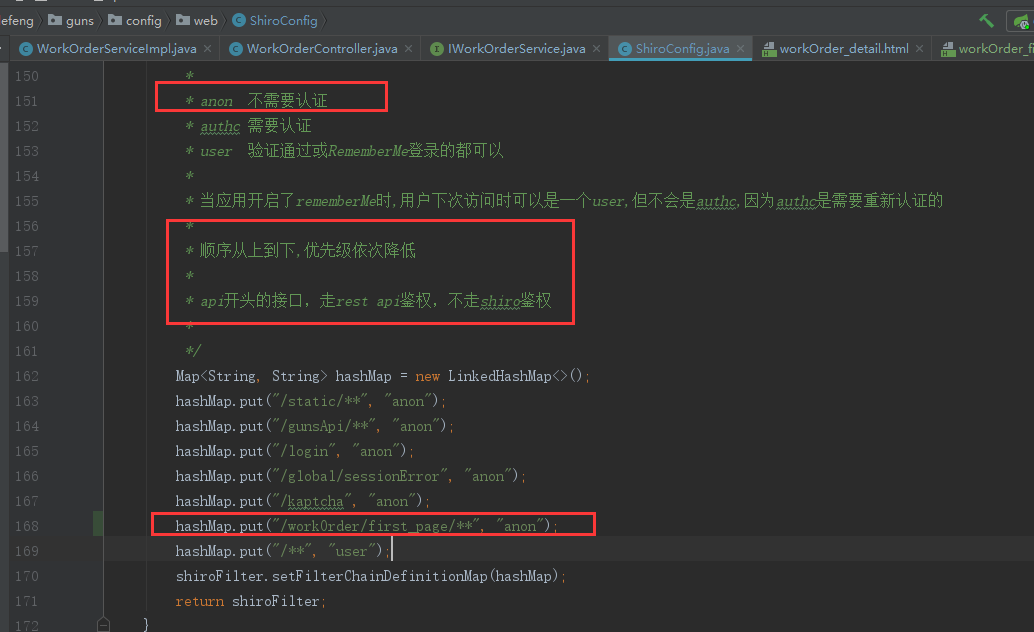
/**
* 网页报表首页
*/
@RequestMapping(value = "/first_page/{workOrderId}")
public String firstPage(@PathVariable Integer workOrderId , Model model){
WorkOrder workOrder = workOrderService.selectById(workOrderId);
model.addAttribute("workOrder",workOrder);
SimpleDateFormat sdf = new SimpleDateFormat("d MMM yyyy", Locale.ENGLISH);
String reportDateStr = sdf.format(workOrder.getAppointTimeStart());//使用预约日期
model.addAttribute("reportDateStr",reportDateStr);
return PREFIX + "workOrder_firstPage.html";
}
网页连接必须当成外接api开放
前端pdf生成按钮
js:
利用pdfjs 产生pdf预览界面
WorkOrderDetail.printReceipt = function () {
var workOrderId = $("#workOrderId").text();
window.open('/static/js/plugins/pdfjs/web/viewer.html?file=' + encodeURIComponent(Feng.ctxPath + "/workOrder/print_receipt/"+ workOrderId,"pdf"));
};
controller:
/**
* 完工记录pdf
*/
@Permission
@RequestMapping(value = "/print_receipt/{workOrderId}")
@ResponseBody
public void printReceipt(@PathVariable Integer workOrderId){
workOrderService.printReceipt(workOrderId);
}
pom.xml : 需要引入的包
com.itextpdf
itextpdf
5.5.6
com.itextpdf.tool
xmlworker
5.5.6
com.itextpdf
itext-asian
5.2.0
org.jsoup
jsoup
1.10.1
serviceImpl 接口就省略不放上来
1: 代码没有写完,感觉效果不是太理想就放弃了
2: 可以把获取打印网页html,保存本地html 文件,再重启读取html文件,生成pdf 文件后,再删除html文件的的过程, 改成直接append 拼接html的string然后直接生成pdf文件
3: 后续可以利用document 的 add page 增加页面,
/**
* 完工记录pdf入口,
*/
public boolean printReceipt(Integer workOrderId){
//html预览title
WorkOrder workOrder = this.selectById(workOrderId);
String title = workOrder.getShopNameCh() + "-完工记录.pdf";
int port = serverProperties.getPort();
//首页生成pdf文件
try {
URL url = new URL("http://localhost:" + port + "/workOrder/first_page/" + workOrderId);
File file = createPdfByUrl(url);
showReceiptOrder(file , title);
} catch (MalformedURLException e) {
e.printStackTrace();
}
return true;
}
/**
* 利用网页url 创建单个pdf文件
* @param url
* @return
*/
private File createPdfByUrl(URL url){
//pdf 路径
String fileName = String.valueOf(System.currentTimeMillis()).substring(4, 13) + ".pdf";
String picSavePath = gunsProperties.getFileUploadPath();
String subFile = "workOrderPdf"+ "/";
String realPath = ServerUtils.createShopPictureUploadPath(picSavePath+subFile) + fileName;
File file = new File(realPath);
//html路径
String htmlFileName = String.valueOf(System.currentTimeMillis()).substring(4, 13) + ".HTML";
String htmlPath = ServerUtils.createShopPictureUploadPath(picSavePath+subFile) + htmlFileName;
PdfWriter writer = null;
try {
//第一步,创建一个 iTextSharp.text.Document对象的实例:
Rectangle pageSize = new Rectangle(720, 540); //这只页面大小
Document document = new Document(pageSize);
// 测试页面大小
// PdfReader reader = new PdfReader(picSavePath + subFile + "xxxx店-完工记录-.pdf");
// Document document2 = new Document(reader.getPageSize(1));
// reader.close();
// document2.close();
//第二步,为该Document创建一个Writer实例:
FileOutputStream fos = new FileOutputStream(realPath);
writer = PdfWriter.getInstance(document, fos);
//第三步,打开当前Document
document.open();
//第四步,为当前Document添加内容:
//document.add(new Paragraph("Hello World"));
if(convertUrlToHtml(url , htmlPath) == false){
throw new GunsException(BizExceptionEnum.CREATE_HTML_FILE_ERROR);
}
FileInputStream fis = new FileInputStream(htmlPath);
XMLWorkerHelper.getInstance().parseXHtml(writer, document, fis);
//第五步,关闭Document
document.close();
fis.close();
fos.close();
new File(htmlPath).delete(); // 删除html文件
if(ToolUtil.isEmpty(file)){
throw new GunsException(BizExceptionEnum.CREATE_PDF_ERROR);
}
return file;
} catch (DocumentException e) {
e.printStackTrace();
return null;
} catch (FileNotFoundException e) {
e.printStackTrace();
return null;
} catch (IOException e) {
e.printStackTrace();
return null;
}finally {
writer.close();
}
}
/**
* 把url 上的html 保存为本地html文件
* @param url
* @param htmlPath
* @return
*/
public boolean convertUrlToHtml(URL url , String htmlPath){
try {
File htmlFile = new File(htmlPath);
InputStream is;//接收字节输入流
FileOutputStream fos = new FileOutputStream(htmlFile);//字节输出流
is = url.openStream();
BufferedInputStream bis = new BufferedInputStream(is);//为字节输入流加缓冲
BufferedOutputStream bos = new BufferedOutputStream(fos);//为字节输出流加缓冲
int length;
byte[] bytes = new byte[1024*20];
while((length = bis.read(bytes, 0, bytes.length)) != -1){
fos.write(bytes, 0, length);
}
bos.close();
fos.close();
bis.close();
is.close();
return true;
} catch (FileNotFoundException e) {
e.printStackTrace();
return false;
} catch (IOException e) {
e.printStackTrace();
return false;
}
}
/**
* pdf文件前端展示
* @param file
* @param httpTitleName
*/
private void showReceiptOrder(File file ,String httpTitleName){ // httpTitleName = "xx店-完工记录.pdf"
try{
FileInputStream fileInputStream = new FileInputStream(file);
HttpServletResponse response = HttpKit.getResponse();
response.setHeader(
"Content-Disposition",
"attachment;fileName="
+ new String( httpTitleName.getBytes("utf-8"),"ISO8859-1")
);
response.setContentType( "multipart/form-data");
OutputStream outputStream = response.getOutputStream();
IOUtils.write(IOUtils.toByteArray(fileInputStream), outputStream);
fileInputStream.close();
outputStream.flush();
outputStream.close();
}catch (IOException e){
e.printStackTrace();
}catch(Exception e) {
e.printStackTrace();
}finally {
System.out.println("成功显示文件!");
}
}
效果如下:
html 文件

看上去效果还可以,
但是生成的pdf文件

其实这个还要考虑中文直接,导入simsun 宋体包,还有考虑把图片改成base64格式才可以读取, 由于对应的html文件,无法读取js,以及大部分的css效果,如果对报表要求比较严格,内容比较多,样式调整就非常麻烦
