这个阶段该如何学习
1.回顾前面学习的知识点
- JavaSE
- 数据库
- 前端
- Servlet
- Http
- Mybatis
- Spring
- SpringMVC
- SpringBoot
- Dubbo、Zookeeper、分布式基础
- Maven、Git
- Ajax、Json
2.学习SpringCloud的基础
- 数据库
- Mybatis
- Spring
- SpringMVC
- SpringBoot
- Dubbo、Zookeeper、分布式基础
- Maven、Git
- Ajax、Json
3.为什么要学习SpringCloud
1.MVC三层架构
1.MVC三层架构
- 首先SpringCloud是一个微服务架构,而我们最早接触的架构为:三层架构 MVC
- 架构的本质:为了解耦,降低功能模块之间的耦合性
2.简化MVC三层架构的Spring
- 升级三层架构 MVC,就是我们使用的框架,本质还是在使用三层架构MVC,只是简化了开发
- 粘合剂Spring:核心 IOC + AOP
- Spring是一个轻量级的Java开源框架,也是一个容器;用于解决企业开发的复杂性
- IOC:控制反转,实现方式DI(依赖注入),将原来要做的准本都丢给容器,要用东西直接去容器中取
- AOP:切面,本质为动态代理(Proxy),为了在不影响原来的业务的情况下(不改源码),实现功能的新增
- 比如:日志、事务等
- 目的:解决企业开发的复杂性
- 粘合剂Spring:核心 IOC + AOP
3.简化Spring的SpringBoot
- spring本意是简化开发,但是spring经过多年的发展,集成的东西越来越多,这使得它使用起来并不简单,使用的过程中涉及到了很多的配置文件的配置
- 这偏离了spring本来简化开发的目的, 简化MVC三层架构开发的作用越来越弱,所以出现了springBoot,用于简化使用spring的时候对配置文件的配置
- SpringBoot:新一代的Java EE开发标准,开箱即用(因为自动帮我们配置了很多的东西,所以可以开箱即用)
- 最大的特点就是"自动配置/装配",所以SpringBoot的约定大于配置
- 注意:SpringBoot不是一个全新概念,它是为了简化现在使用起来越来越复杂的spring而诞生的,所以SpringBoot就是Spring的一个升级版
- 小结:传统的三层架构MVC用于将企业Java开发分层,各层之间子职责清晰,但是代码量庞大且冗余, 所以出现了spring,用于简化企业开发的代码,但是经过多年发展spring需要配置的文件越来越多,所以出现了springBoot,用于简化使用spring的时候对配置文件的配置
2.新的架构:微服务架构
1.为什么需要新的架构
- 但是SpringBoot本质终归还是在对原来的三层架构MVC的开发做简化,还是使用的传统的开发架构, 因为传统的开发架构本质就是All in one,即一个项目作为一个整体进行开发和部署,整个项目需要作为一个 整体部署在一台服务器上,当这一台服务器支持不了当前用户量的时候我们的解决办法就是"横向"的扩展服务器
- 一台服务器不够就再加一台服务器,但是加上服务器之后就需要考虑负载均衡问题;说白了就是在服务器集群前面加一个程序,程序根据算法实现,用于保证后面的一大堆服务器被雨露均沾,不会出现一台服务器上的资源都要被耗光了,另一台服务器上的资源还没用的情况
- 但是一旦出现了整个服务中的某一个模块需要升级改造,后果就是整个项目的所有服务停机,一般看到的就是"我们需要停机维护XXX的时间",在这个期间,公司的服务器是停止向用户提供服务的,这对于用户体量很大,或者说国际化的公司来说是不能忍受的,因为停止服务就会出现客户流失的风险;除此之外还有很多其他的原因,比如可能我只需要这个项目中某一个模块的功能,但是为了正常运行我需要部署整个项目等
- 所以为了解决这个问题,提出了新的开发架构 —— 微服务架构
2.什么是微服务架构
- 微服务架构,一个你没见过的全新版本,它的特点就是"模块化、功能化"
- 微服务架构的本质:将原来的整体项目划分成多个功能模块,一个功能模块就可以独立运行提供服务
- 比如现在我们需要开发一个管理系统,这个系统有用户模块、支付模块、签到模块…, 但是在实际的使用中,我们发现,用户和支付模块使用远高于签到模块;
- 在微服务架构中我们就给用户和支付模块多一些服务器去支撑运行,给签到模块少一些服务器去支持它的运行;而按照原来MVC三层架构,不管你的签到功能使用的频率是多大,只要你部署服务,签到都要占用服务器一部分资源,多台服务器上被占用的资源累加起来可能就是好几台服务器的资源量,而实际用户的使用量一台服务器就能满足,这样看来原来的MCV三层架构不就是对于资源的一种浪费了吗?所有微服务架构势在必行
3.微服务架构的需要解决的问题
- 但是微服务架构就出现了新的问题,如果要使用复杂功能,那么各个模块/单独的项目之间怎么通信?怎么交互?
- 这个是微服务架构中显而易见的问题,微服务架构中的问题可以分为如下的4类
微服务的四个核心问题?
1,服务很多,客户端怎么访问?(怎么获取服务?设置注册中心,用户请求都发送到注册中心,再由注册中心分发用户请求到具体服务器)2,这么多服务,服务之间如何通信?(服务之间怎么通信?)3,这么多服务,如何管理?(对于这么多服务怎么统一管理?设置一个统一的服务管理平台,比如zookeeper)4,服务挂了怎么办?(服务器崩溃、断电之后怎么应对?熔断机制)4.微服务架构问题解决办法/方案
-
微服务的四个核心问题的解决方案:
Spring Cloud 是一套生态!专门用于解决微服务的四个核心问题的生态 -
学习SpringCloud的前提是学习SpringBoot,原因就是因为SpringCloud是基于SpringBoot的
1.SpringCloud NetFilx(第一套SpringCloud生态)
NetFilx公司推出了一套解决SpringCloud生态,或者说一站式解决微服务架构中问题的方案,我们要使用直接拿来使用即可
- 问题1:服务很多,客户端怎么访问?
- API网关,实现统一服务治理,使用zuul组件
- 问题2:这么多服务,服务之间如何通信?
- 网络通信都是基于HTTP的通信,NetFilx推出了一个自己对HTTP的包装版Feign(Feign基于HttpClient,HttpClient基于HTTP),通信方式:同步并阻塞
- 问题3:这么多服务,如何管理?
- 服务注册与发现,使用插件Eureka解决
- 问题4:服务挂了怎么办?
- 熔断机制,Hystrix
- 但是2018年12月,NetFilx宣布无限期的停止对于SpringCloud NetFilx的维护,停止维护就会导致解决方案和当前技术的脱节,最大的隐患就是出现了新的安全问题,但是原来的解决方案没有应对机制,而安全是一个公司应该注重的根本,所以现在很多公司又不使用它了
2.Apache Dubbo zookeeper(第二套SpringCloud生态)
- 问题1:服务很多,客户端怎么访问?
- API网关,没有,要么使用第三方的组件实现,要么自己实现
- 问题2:这么多服务,服务之间如何通信?
- Dubbo:高性能的基于Java实现并开源的RPC通信框架,简单易用且专业
- 问题3:这么多服务,如何管理?
- 服务注册与发现,使用第三方的zookeeper(Hadoop、Hive等),下载安装即可使用
- 问题4:服务挂了怎么办?
- 熔断机制,没有,要么使用第三方的组件实现,要么自己实现,一般都是借助NetFilx的熔断机制
- 可见Apache的SpringCloud生态并不完善,虽然问题2和3解决的比较好,但是1和4都是需要依赖其他的第三方,不是自己出来的一套完整的解决方案
- 即半自动的,需要整合别人的技术
3.SpringCloud Alibaba(第三套SpringCloud生态)
- 一站式解决微服务架构中的问题,全部都是Alibaba自己给出的解决方案
- 最新的SpringCloud生态,使用起来更简单,2019年第一代才出来
4.未来的SpringCloud生态(服务网格,Server Mesh)
- 服务网格,下一代微服务标准
- 什么是服务网格
- 代表解决方案:istio【未来需要掌握的技术】
5.小结
- 上面的解决方案其实都是在解决微服务架构中的4个问题,所以万变不离其宗,一通百通
- API网格,服务的路由问题
- HTTP或RPC来实现,实现跨服务器的调用/异步调用
- 服务注册与发现,解决高可用问题
- 熔断机制,服务降级
- 为什么要解决上面的问题?因为网络是不可靠的,网络不可靠就导致了用户使用的时候,可能会丢包、丢帧、数据被拦截、数据出现丢失,这就降低了用户体验,我们要解决的就是让用户使用微服务架构的应用,但是感觉和使用单体应用一样,甚至更好
- 所以我们可以通过学习最先出来的SpringCloud NetFilx,入门SpringCloud生态圈,然乎通过SpringCloud NetFilx作为跳板去学习其他的解决方案
5.需要区分的概念
集群、分布式和微服务的区别
- 集群:同一个业务,部署在多个服务器上,一台服务器垮了,其它的服务器可以顶上来。
- 分布式:一个业务分拆多个子业务,部署在不同的服务器上,分布式的每一个节点,都完成不同的业务,一个节点垮了,那这个业务就不可访问了。
- 分布式是指将不同的业务分布在不同的地方。而集群指的是将几台服务器集中在一起,实现同一业务;简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率
- 分布式和微服务的区别
4.常见面试题
- 什么是微服务?
- 微服务之间是如何独立通讯的?
- SpringCloud 和 Dubbo有哪些区别?
- SpringBoot 和 SpringCloud,请谈谈你对他们的理解
- 什么是服务熔断?什么是服务降级?
- 微服务的优缺点分别是什么?说下你在项目开发中遇到的坑
- 你所知道的微服务技术栈有哪些?列举一二
- Eureka和Zookeeper都可以提供服务注册与发现的功能,请说说两者的区别
一,这个阶段如何学习
1.什么是微服务
-
微服务(Microservice Architecture) 是近几年流行的一种架构思想,关于它的概念很难一言以蔽之
-
究竟什么是微服务呢?我们在此引用ThoughtWorks 公司的首席科学家 Martin Fowler 于2014年提出的一段话
- 就目前而言,对于微服务,业界并没有一个统一的,标准的定义
- 但通常而言,微服务架构是一种架构模式,或者说是一种架构风格,它提倡将单一的应用程序划分成一组小的服务,每个服务运行在其独立的自己的进程内,服务之间互相协调,互相配置,为用户提供最终价值,服务之间采用轻量级的通信机制(HTTP)互相沟通,每个服务都围绕着具体的业务进行构建,并且能狗被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应该根据业务上下文,选择合适的语言,工具(Maven)对其进行构建,可以有一个非常轻量级的集中式管理来协调这些服务,可以使用不同的语言来编写服务,也可以使用不同的数据存储
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7M5OaMKI-1653555417747)(SpringCloud.assets/image-20211001094352140.png)]](https://img-blog.csdnimg.cn/f5598639d68246cfb4c9581e16decad4.png)
-
再来从技术维度角度理解下:
- 微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底地去耦合,每一个微服务提供单个业务功能的服务,一个服务做一件事情,从技术角度看就是一种小而独立的处理过程,类似进程的概念,能够自行单独启动或销毁,拥有自己独立的数据库
2.微服务与微服务架构
1.微服务
-
强调的是服务的大小,它关注的是某一个点,是具体解决某一个问题/提供落地对应服务的一个服务应用,狭义的看,可以看作是IDEA中的一个个微服务工程,或者Moudel
IDEA 工具里面使用Maven开发的一个个独立的小Moudel,它具体是使用SpringBoot开发的一个小模块,专业的事情交给专业的模块来做,一个模块就做着一件事情强调的是一个个的个体,每个个体完成一个具体的任务或者功能
2.微服务架构
- 一种新的架构形式,Martin Fowler 于2014年提出
- 微服务架构是一种架构模式,它体长将单一应用程序划分成一组小的服务,服务之间相互协调,互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务之间采用轻量级的通信机制(如HTTP)互相协作,每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具(如Maven)对其进行构建
3.微服务优缺点
1.优点
- 每个服务足够内聚,足够小,代码也容易理解,这样能聚焦一个指定的业务功能或业务需求【符合OOP7大原则中单一职责原则】
- 开发简单,开发效率高,一个服务可能就是专一的只干一件事情
- 微服务能够被小团队单独开发,这个团队只需要2~5个开发人员组成
- 微服务是松耦合的,是功能意义的服务,无论是在开发阶段或者部署阶段都是独立的【每个微服务单独部署和运行】
- 微服务能使用不同的语言开发
- 易于和第三方集成,微服务允许弱且灵活的方式集成自动部署,通过持续集成工具,如jenkins,Hudson,bamboo
- 微服务易于被一个开发人员理解,修改和维护,这样的小团队能够更关注自己的工作成果,无需通过合作才能体现价值
- 微服务允许利用和融合最新技术
- 微服务只是业务逻辑代码,不会和HTML,CSS,或者其他的界面混合
- 每个微服务都有自己的存储能力,可以有自己的数据库,也可以有统一的数据库
2.缺点
- 开发人员要处理分布式系统的复杂性
- 多服务运维难度,随着服务的增加,运维的压力也在增大
- 系统部署依赖问题
- 服务间通信成本问题
- 数据一致性问题
- 系统集成测试问题
- 性能和监控问题
4.微服务技术栈有那些?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QGRGhKrV-1653555417748)(SpringCloud.assets/image-20211001104526889.png)]](https://img-blog.csdnimg.cn/967f3e1457d84198bcae40784251b035.png)
5.为什么选择SpringCloud作为微服务架构?
-
选型依据
- 整体解决方案和框架成熟度
- 社区热度
- 可维护性
- 学习曲线
-
当前各大IT公司用的微服务架构有那些?
- 阿里:dubbo+HFS
- 京东:JFS
- 新浪:Motan
- 当当网:DubboX
- …
-
各微服务框架对比
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-asirdzUN-1653555417749)(SpringCloud.assets/微服务框架对比.png)]](https://img-blog.csdnimg.cn/e087354a947b49998c73b189bac1adce.png)
二,SpringCloud入门概述
1.什么是SpringCloud
-
Spring Cloud provides tools for developers to quickly build some of the common patterns in distributed systems (e.g. configuration management, service discovery, circuit breakers, intelligent routing, micro-proxy, control bus, one-time tokens, global locks, leadership election, distributed sessions, cluster state). Coordination of distributed systems leads to boiler plate patterns, and using Spring Cloud developers can quickly stand up services and applications that implement those patterns. They will work well in any distributed environment, including the developer’s own laptop, bare metal data centres, and managed platforms such as Cloud Foundry.
-
翻译:Spring Cloud为开发人员提供了在分布式系统中快速构建一些常见模式的工具(例如配置管理、服务发现、断路器、智能路由、微代理、控制总线、一次性令牌、全局锁、领导选举、分布式会话、集群状态)。分布式系统的协调产生了一些样板性质的模式,使用Spring Cloud开发人员可以快速地建立实现这些模式的服务和应用程序。它们在任何分布式环境下都能很好地工作,包括开发人员自己的笔记本电脑、裸机数据中心和云计算等托管平台
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EHm3KT8P-1653555976182)(SpringCloud.assets/image-20211001163133910.png)]](https://img-blog.csdnimg.cn/645eb89b4fe44103872a4cf2f747c94a.png)
-
SpringCloud,基于SpringBoot提供了一套微服务解决方案,包括服务注册与发现,配置中心,全链路监控,服务网关,负载均衡,熔断器等组件,除了基于NetFlix的开源组件做高度抽象封装之外,还有一些选型中立的开源组件
-
SpringCloud利用SpringBoot的开发便利性,巧妙地简化了分布式系统基础设施的开发,SpringCloud为开发人员提供了快速构建分布式系统的一些工具,包括配置管理,服务发现,断路器,路由,微代理,事件总线,全局锁,决策竞选,分布式会话等等,他们都可以用SpringBoot的开发风格做到一键启动和部署
-
SpringBoot并没有重复造轮子,它只是将目前各家公司开发的比较成熟,经得起实际考验的服务框架组合起来,通过SpringBoot风格进行再封装,屏蔽掉了复杂的配置和实现原理(这就导致我们对于它的原理的掌握更加困难,那么当服务出现错误的时候,我们的排错难度将会增加,所以在学习这些框架的时候,掌握它的原理非常重要),最终给开发者留出了一套简单易懂,易部署和易维护的分布式系统开发工具包
-
SpringCloud是分布式微服务架构下的一站式解决方案,是各个微服务架构落地技术的集合体,俗称微服务全家桶
2.SpringCloud和SpringBoot的关系
- SpringBoot专注于快速方便的开发单个个体微服务【一个个的Jar包】
- SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务,整合并管理起来,为各个微服务之间提供:配置管理、服务发现、断路器、路由、为代理、事件总栈、全局锁、决策竞选、分布式会话等等集成服务
- SpringBoot可以离开SpringCloud独立使用,开发项目,但SpringCloud离不开SpringBoot,属于依赖关系
- SpringBoot专注于快速、方便的开发单个个体微服务,SpringCloud关注全局的服务治理框架
3.Dubbo和SpringCloud技术选型
分布式+服务治理Dubbo
目前成熟的互联网架构,应用服务化拆分+消息中间件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b8eMgde3-1653555976184)(SpringCloud.assets/image-20211001163729700.png)]](https://img-blog.csdnimg.cn/85b95ccdb9dd4299a20fa00b96bc674f.png)
-
CND:CDN的全称是Content Delivery Network,即内容分发网络
-
lvs: 是 Dracula 的验证工具,用来验证版图和逻辑图是否匹配
-
Nginx:是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。
-
Dubbo 和 SpringCloud对比
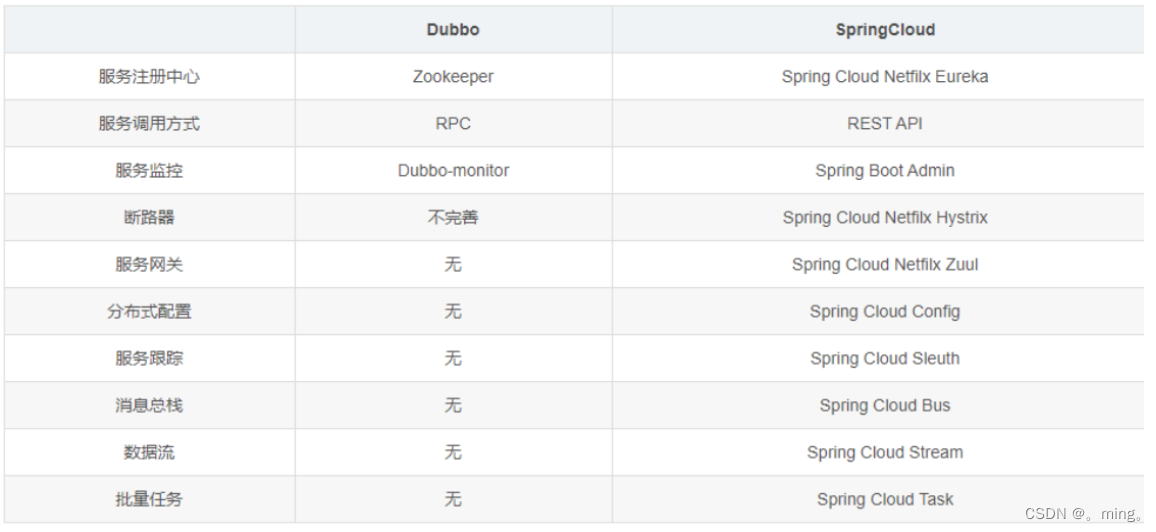
- 最大区别:Spring Cloud 抛弃了Dubbo的RPC通信,采用的是基于HTTP的REST方式
- 严格来说,这两种方式各有优劣。虽然从一定程度上来说,后者牺牲了服务调用的性能,但也避免了上面提到的原生RPC带来的问题,而且REST相比RPC更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的强依赖,这个优点在当下强调快速演化的微服务环境下,显得更加合适
- 品牌机(Spring Cloud)和组装机(DUBBO)的区别
- 很明显,Spring Cloud的功能比DUBBO更加强大,涵盖面更广,而且作为Spring的明星项目,它也能够与Spring Framework、Spring Boot、Spring Data、Spring Batch等其他Spring项目完美融合,这些对于微服务而言是至关重要的。使用Dubbo构建的微服务架构就像组装电脑,各环节我们的选择自由度很高,但是最终结果很有可能因为一条内存质量不行就点不亮了,总是让人不怎么放心,但是如果你是一名高手,那这些都不是问题;而SpringCloud就像品牌机,在Spring Source的整合下,做了大量的兼容性测试,保证了机器拥有更高的稳定性,但是如果要在使用非原装组件外的东西,就需要对其基础有足够的了解
- 社区支持与更新力度的区别
- 最为重要的是,DUBBO停止了5年左右的更新,虽然2017.7重启了。对于技术发展的新需求,需要由开发者自行拓展升级(比如当当网弄出了DubboX),这对于很多想要采用微服务架构的中小软件组织,显然是不太合适的,中小公司没有这么强大的技术能力去修改Dubbo源码+周边的一整套解决方案,并不是每一个公司都有阿里的大牛+真实的线上生产环境测试过
- 后面需要重点学习设计模式+微服务拆分思想,在公司有很多技术很强但是不善于表达的大牛(编码硬实力强),如果你很会说,很会提意见,即你的软实力强,你可以变成他们的领导;其次就是要注意自己在开源社区中的活跃度,活跃的是猎头找到你的一个重要因素
- 总结
- 二者解决的问题域不一样:Dubbo的定位是一款RPC框架,而SpringCloud的目标是微服务架构下的一站式解决方案
4. SpringCloud的作用
- Distributed/versioned configuration 分布式/版本控制配置
- Service registration and discovery 服务注册与发现
- Routing 路由
- Service-to-service calls 服务到服务的调用
- Load balancing 负载均衡配置
- Circuit Breakers 断路器
- Distributed messaging 分布式消息管理
5.SpringCloud下载
-
SpringCloud是一个由众多独立子项目组成的大型综合项目,每个子项目有不同的发行节奏,都维护着自己的发布版木号。spring cloud通过一个资源清单BOM(Bil1 of Materials)来管理每个版木的子项目清单,为避免与子项目的发布号混淆,所以没有采用版本号的方式,而是通过命名的方式
-
SpringCloud没有采用数字编号的方式命名版本号,而是采用了伦敦地铁站的名称,同时根据字母表的顺序来对应版本时间顺序,比如最早的Realse版本:Angel,第二个Realse版本:Brixton,然后是Camden、Dalston、Edgware,目前最新的是Hoxton SR8 CURRENT GA通用稳定版
-
自学参考网站:
三,Rest学习环境搭建:服务提供者
1.总体介绍
-
我们会使用一个Dept部门模块做一个微服务通用案例Consumer消费者(Client)通过REST调用Provider提供者(Server)提供的服务
-
回顾Spring,SpringMVC,Mybatis等以往学习的知识
-
Maven的分包分模块架构复习
一个简单的Maven模块结构是这样的:-- app-parent: 一个父项目(app-parent)聚合了很多子项目(app-util\app-dao\app-web...) |-- pom.xml | |-- app-core ||---- pom.xml | |-- app-web ||---- pom.xml ...... -
一个父工程带着多个model子模块
-
MicroServiceCloud父工程(Project)下初次带着3个子模块(Module)
- microservicecloud-api 【封装的整体entity/接口/公共配置等】
- microservicecloud-consumer-dept-80 【服务提供者】
- microservicecloud-provider-dept-8001 【服务消费者】
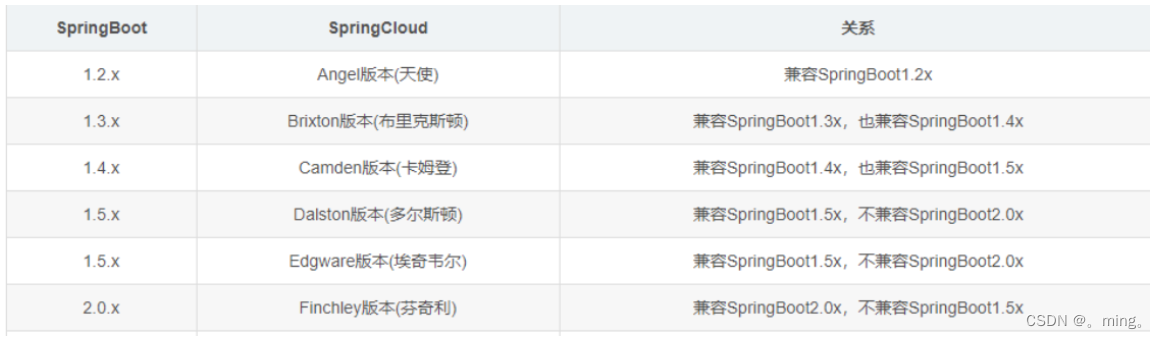
2.SpringCloud版本选择
-
大版本说明
-
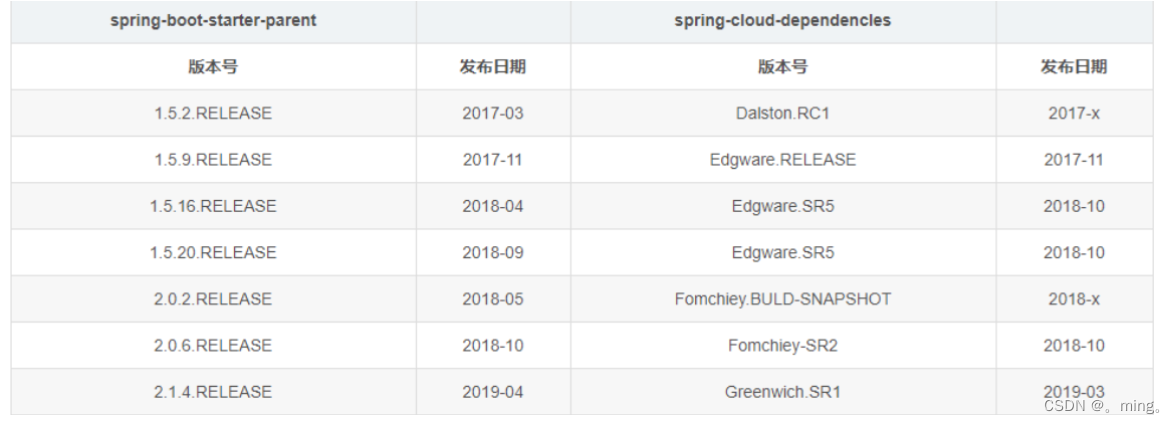
实际开发版本关系
-
使用后两个
3.创建工程
1.创建父工程
-
创建新项目(普通的maven项目)
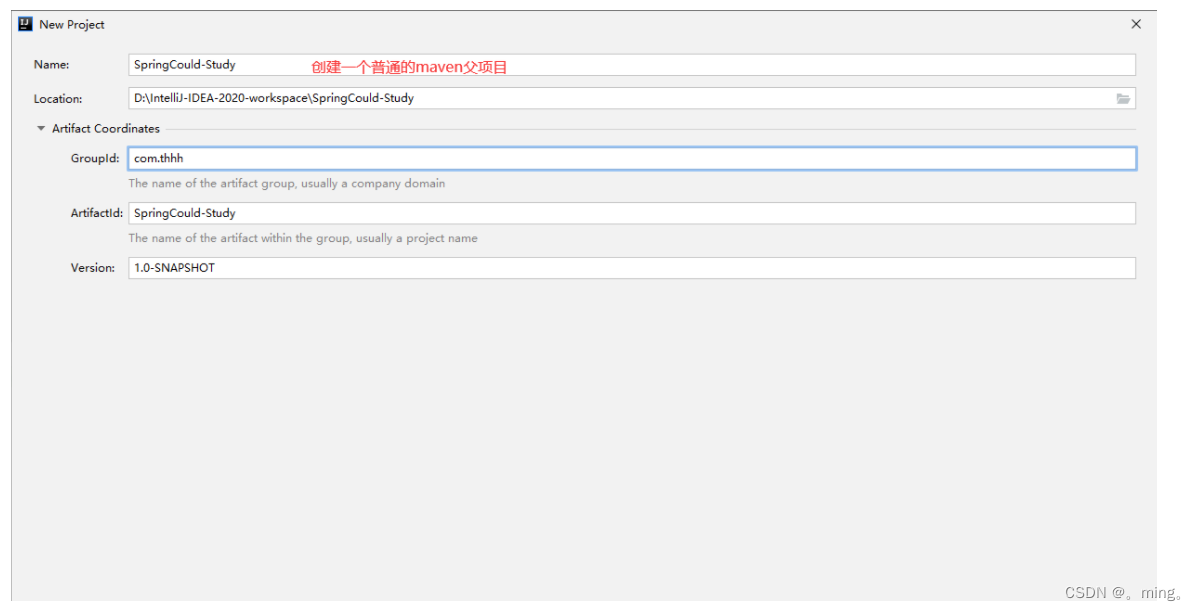
-
首先导入项目依赖,首先当然是导入核心依赖,依赖名称我们可以在官方Doc上面找
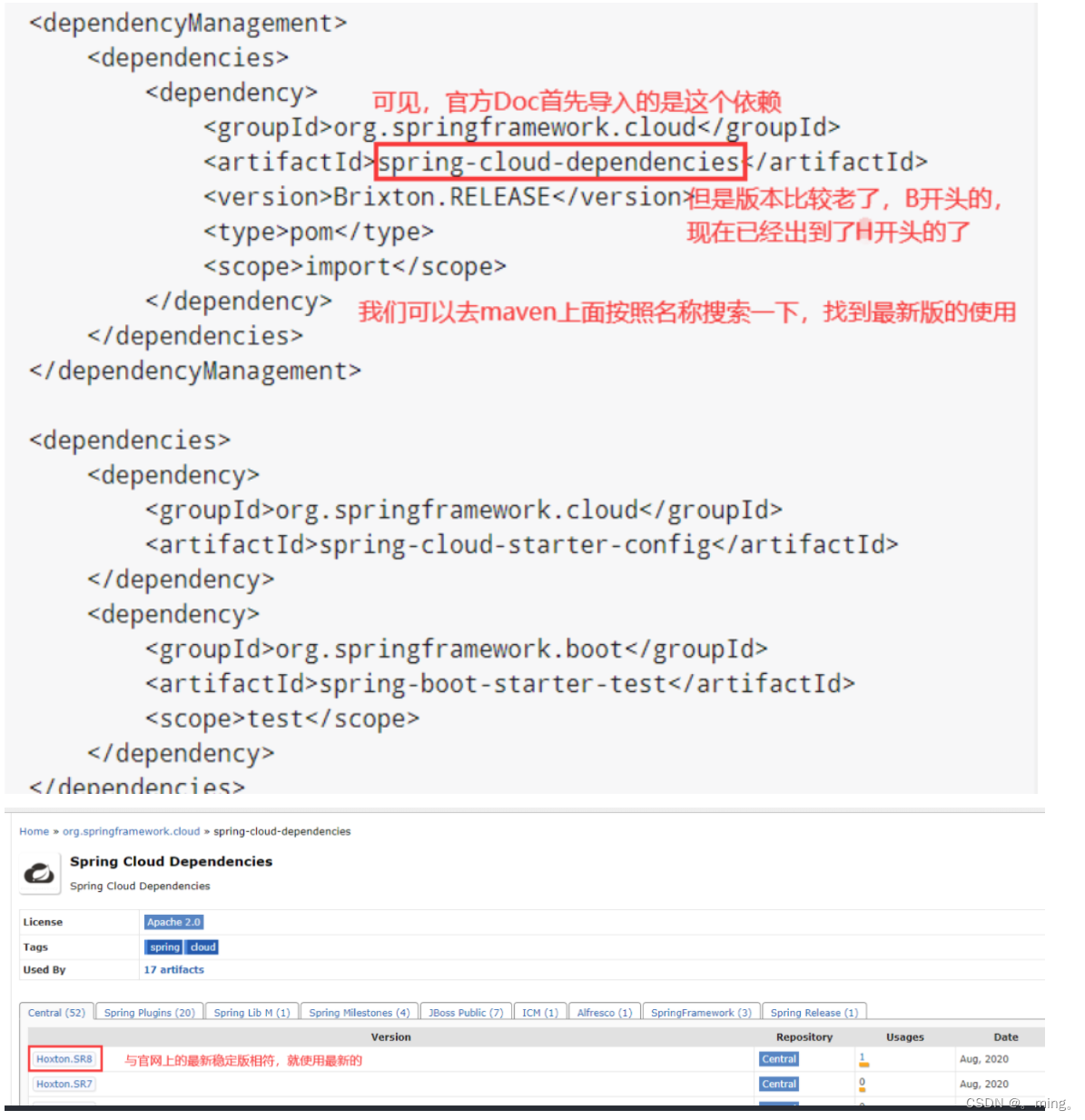
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-dependencies --><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Hoxton.SR8</version> <type>pom</type> <scope>import</scope><!--可以直接删除,也可以改成import--></dependency> -
第二个需要导入的依赖为spring boot的依赖,因为spring could的使用是依赖于spring boot的,所以我们应该导入spring boot的依赖;但是我们需要spring could和spring boot之间的版本对应(版本对应网址,注意:需要使用火狐才能正常的解析查看下图样式,其他的浏览器就是正常的JSON字符串,没有样式我们可以直接搜索也可以找到对应的版本选择)
-
所以我们使用的最新稳定版sr8对应的spring boot版本需要在2.2.0-2.3.5之间,而我们前面使用的spring boot刚好为2.3.4,所以我们沿用前面的spring boot依赖即可
<!--spring boot的依赖--><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.3.4.RELEASE</version> <type>pom</type> <scope>import</scope><!--可以直接删除,也可以改成import--></dependency> -
数据库依赖
<!--数据库依赖--><dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version></dependency><!--数据源--><dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.24</version></dependency> -
mybatis启动器
<!--spring boot中mybatis的启动器--><dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.3</version></dependency> -
其他的一些杂七杂八的依赖
<!--日志log4j依赖--><dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>${log4j.version}</version></dependency><!--单元测试依赖--><dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>${junit.version}</version> <!--注意:该版本号我们可以不在这里写死,而是使用我们上面的properties节点中定义的参数来实现版本可变--></dependency><dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version></dependency> -
注意:上面3个依赖的版本号我都是写的${变量名}进行取值,这些变量名都写在上面的节点properties中的
<!--日志log4j依赖--><dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>${log4j.version}</version></dependency><!--单元测试依赖--><dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>${junit.version}</version> <!--注意:该版本号我们可以不在这里写死,而是使用我们上面的properties节点中定义的参数来实现版本可变--></dependency><dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version></dependency> -
这种做法可以实现我们动态的修改对应依赖的版本号,虽然我们可以直接去对应的依赖中直接修改,但是当依赖太多的时候,寻找对应的依赖就变成了一件麻烦事,所以我们可以通过自定义变量将变量的控制集中在properties节点中,后面要修改直接在properties中进行修改即可
<properties> <lombok.version>1.18.12</lombok.version> <junit.version>4.13</junit.version> <log4j.version>1.2.17</log4j.version></properties> -
还有一个log4j需要的依赖
<dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> <version>1.2.3</version></dependency> -
除了上面的依赖导入,我们还需要配置一些资源导出配置过滤,主要防止maven项目约定大于配置,导致非resources文件夹下的资源文件无法导出的问题
<build> <resources> <resource> <directory>src/main/java</directory> <includes> <include>**/*.yml</include> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>false</filtering> </resource> <resource> <directory>src/main/resources</directory> <includes> <include>**/*.yml</include> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>false</filtering> </resource> </resources></build> -
所以完整的父工程的pom.XML
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.thhh</groupId> <artifactId>SpringCould-Study</artifactId> <version>1.0-SNAPSHOT</version> <!--导包方式 pom打包方式--> <packaging>pom</packaging> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <lombok.version>1.18.12</lombok.version> <junit.version>4.13</junit.version> <log4j.version>1.2.17</log4j.version> </properties> <dependencyManagement> <dependencies> <!--spring could的依赖--> <!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-dependencies --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Hoxton.SR8</version> <type>pom</type> <scope>import</scope><!--可以直接删除,也可以改成import--> </dependency> <!--spring boot的依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.3.4.RELEASE</version> <type>pom</type> <scope>import</scope><!--可以直接删除,也可以改成import--> </dependency> <!--数据库依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <!--数据源--> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.24</version> </dependency> <!--spring boot中mybatis的启动器--> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.3</version> </dependency> <!--日志和测试--> <!--log4j需要的依赖--> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> <version>1.2.3</version> </dependency> <!--日志log4j依赖--> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>${log4j.version}</version> </dependency> <!--单元测试依赖--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>${junit.version}</version> <!--注意:该版本号我们可以不在这里写死,而是使用我们上面的properties节点中定义的参数来实现版本可变--> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version> </dependency> </dependencies> </dependencyManagement> <build> <resources> <resource> <directory>src/main/java</directory> <includes> <include>**/*.yml</include> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>false</filtering> </resource> <resource> <directory>src/main/resources</directory> <includes> <include>**/*.yml</include> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>false</filtering> </resource> </resources> </build></project>
2.创建子model
-
创建一个普通的maven子mode
-
配置子model中需要的依赖,注意:我们的父工程中对于依赖是使用< dependencyManagement >对于导入的依赖进行的管理,在子model创建之后,并不能直接使用父工程中已经导入的依赖,而是需要我们自己手动的导入,但是导入的依赖不需要对其版本进行管理,因为子model中导入的依赖都是从父项目中获取的,所以版本的管理都放在了父项目中;而当子model导入父项目中没有的依赖时,版本就需要自己进行管理,这和前面学习spring boot是一样的
<dependencies> <!--lombok--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency></dependencies> -
创建该子model的数据库
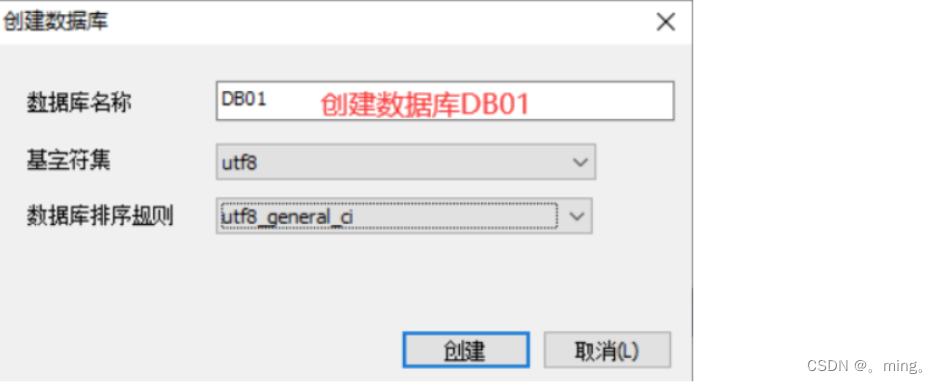
-
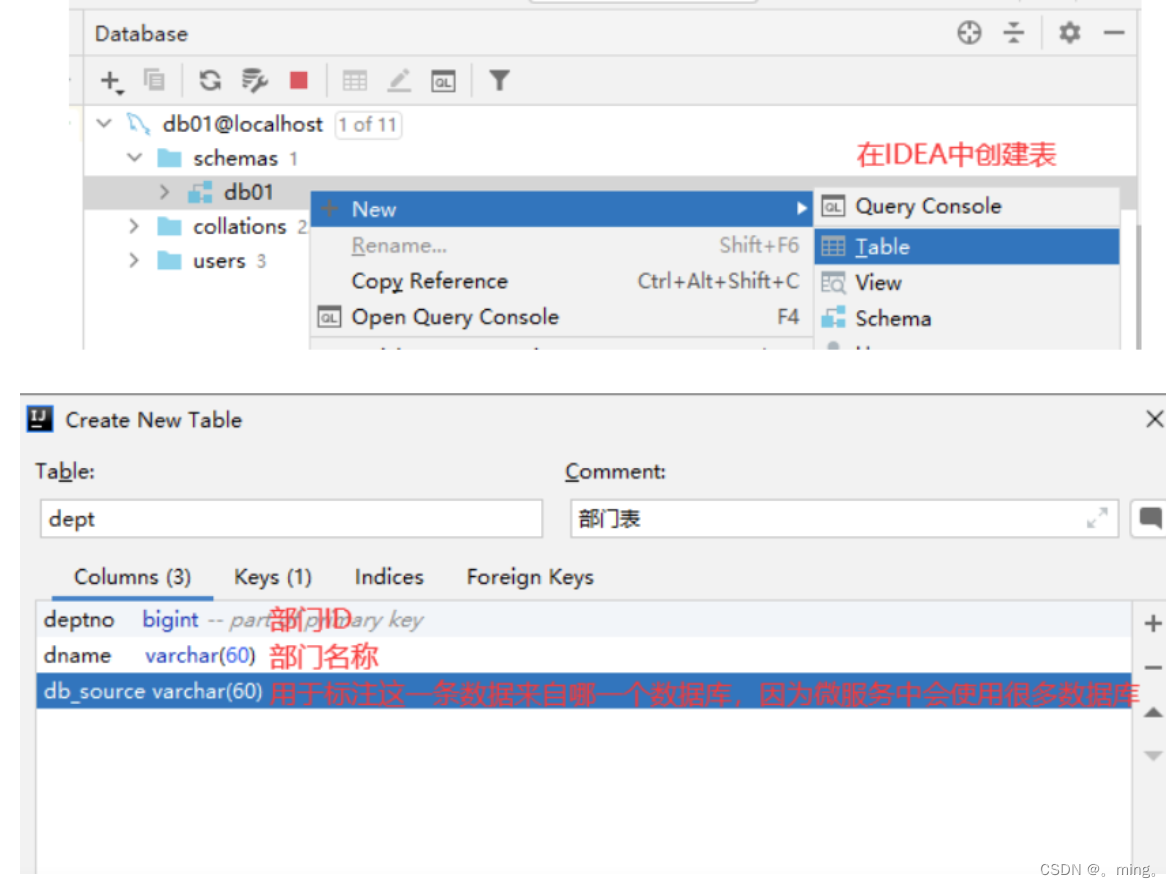
接下来就是给数据库创建表,我们可以选择在IDEA中进行创建,因为它的可视化做的很好,创建起来很快,很方便
-
插入测试数据
insert into dept(dname, db_source)VALUES ('开发部',database());insert into dept(dname, db_source)VALUES ('人事部',database());insert into dept(dname, db_source)VALUES ('财务部',database());insert into dept(dname, db_source)VALUES ('市场部',database());insert into dept(dname, db_source)VALUES ('运维部',database());![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1GanNJFl-1653568339274)(SpringCloud.assets/image-20220311222304015.png)]](https://img-blog.csdnimg.cn/820aeb8f5c7e47668e65c30f0270136d.png)
-
编写实体类pojo
@Data@NoArgsConstructor@Accessors(chain = true)//链式写法//网络传输中,最好将实体类序列化/*链式写法 * Dept dept = new Dept(); * dept.setDeptno().setDname().setDb_source() * */public class Dept implements Serializable { private Long deptno; //主键 private String dname; //部门名称 private String db_source;//标识数据来自哪一个数据库 public Dept(String dname) { //注意:构造器只需要传入部门名称即可,因为部门主键是自增的,来自哪一个数据库是调用数据库函数database()获取的 this.dname = dname; }} -
到此,这个微服务就写完了
3.服务提供者编写
-
接下来就来写服务的提供者,再创建一个model:springcould-provider-dept-8001,注意名称:springcould-provider表示这个是一个spring could中的服务提供者,dept表示提供dept服务,8001表示这个服务运行在哪一个端口上,因为后面服务一多起来,我们可以直接通过子model的名称知道它运行在哪一个端口上就很方便
-
配置子model的依赖,注意:首先这个子model是用来提供dept实体类的服务的,所以它首先就要导入pojo实体类的依赖,直接在依赖中输入我们前面写的那个子model的名称springcould-api即可导入
<dependencies> <dependency> <groupId>com.thhh</groupId> <artifactId>springcould-api</artifactId> <version>1.0-SNAPSHOT</version> </dependency></dependencies> -
完整的子model的pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>SpringCould-Study</artifactId> <groupId>com.thhh</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>springcould-provider-dept-8001</artifactId> <dependencies> <!--实体类dept依赖--> <dependency> <groupId>com.thhh</groupId> <artifactId>springcould-api</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <!--单元测试--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> </dependency> <!--数据库依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> </dependency> <!--logback依赖,讲解:https://zhuanlan.zhihu.com/p/136893269--> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> </dependency> <!--mybatis依赖--> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> </dependency> <!--spring boot的web启动器--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--spring boot的测试依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-test</artifactId> </dependency> <!--jetty--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jetty</artifactId> </dependency> <!--热部署依赖:写完项目之后可以不重启项目,而是刷新一下就可以更新最新改动的资源到项目中--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> </dependency> </dependencies></project> -
编写配置文件
server: port: 8001 #端口号#mybatis配置mybatis: type-aliases-package: com.thhh.springcould.pojo #mybatis的别名扫描 mapper-locations: classpath:mybatis/mapper/*.xml #mybatis去哪里读取pojo对应的mapper接口的mapper.xml文件 config-location: classpath:mybatis/mybatis-config.xml #mybatis核心配置文件,可要可不要,不要就把配置写在spring配置中#spring配置spring: application: name: springcould-provider-dept datasource: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/db01?useSSL=false&useUnicode=true&characterEncoding=utf-8 username: root password: 123 -
编写mybatis核心配置文件(可要可不要)
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"><configuration> <settings> <setting name="cacheEnabled" value="true"/> <!--开启mybatis二级缓存,一级缓存是默认开启的--> </settings></configuration> -
为pojo编写对应的mapper接口
package com.thhh.springcould.mapper;import com.thhh.springcould.pojo.Dept;import org.apache.ibatis.annotations.Mapper;import org.springframework.stereotype.Repository;import java.util.List;@Mapper //声明这是一个mapper@Repository //托管到spring容器中public interface DeptMapper { //新增一个部门 public boolean addDept(Dept dept); //删除一个部门 public boolean deleteDeptById(long id); //修改一个部门 public boolean updateDeptById(long id); //查询一个部门 public Dept queryDeptById(long id); //查询所有部门 public List<Dept> queryDeptList();} -
编写mapper接口的mapper.xml
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.thhh.springcould.mapper.DeptMapper">注意绑定namespace,且是绑定到对应的接口 <insert id="addDept" parameterType="Dept"> insert into db01.dept(dname, db_source) values (#{dname},database()) </insert> <select id="queryDeptById" resultType="Dept"> select * from db01.dept where deptno = #{deptno} </select> <select id="queryDeptList" resultType="Dept"> select * from db01.dept </select></mapper> -
编写service层
package com.thhh.springcould.service;import com.thhh.springcould.mapper.DeptMapper;import com.thhh.springcould.pojo.Dept;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import java.util.List;@Servicepublic class DeptServiceImpl implements DeptService{ @Autowired private DeptMapper deptMapper; @Override public boolean addDept(Dept dept) { return deptMapper.addDept(dept); } @Override public Dept queryDeptById(long id) { return deptMapper.queryDeptById(id); } @Override public List<Dept> queryDeptList() { return deptMapper.queryDeptList(); }} -
编写controller,向前端提供服务接口
package com.thhh.springcould.controller;import com.thhh.springcould.pojo.Dept;import com.thhh.springcould.service.DeptService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.PathVariable;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController //提供restful服务public class DeptController { @Autowired private DeptService deptService; //controller调用service层的服务 //新增一个部门 @PostMapping("/dept/add") public boolean addDept(Dept dept){ return deptService.addDept(dept); } //查询一个部门 @GetMapping("/dept/queryById/{deptno}") public Dept queryDeptById(@PathVariable("deptno") long id){ return deptService.queryDeptById(id); } //查询所有部门 @GetMapping("/dept/queryList") public List<Dept> queryDeptList(){ return deptService.queryDeptList(); }} -
由于我们创建的是一个普通的maven项目,并不是一个spring boot项目,所以我们需要自己手动的创建一个项目的主启动程序/入口程序DeptProvider_8001,注意:入口程序要和我们创建的文件夹平级,否则我们创建的文件夹将不会被扫描到
package com.thhh.springcould;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplicationpublic class DeptProvider_8001 { public static void main(String[] args) { SpringApplication.run(DeptProvider_8001.class,args); }}
四,Rest学习环境搭建:服务消费者
1.环境搭建
- 再创建一个子model
-
导入依赖,不需要连接数据库,所以只需要实体类+web的依赖即可
<dependencies> <!--实体类dept--> <dependency> <groupId>com.thhh</groupId> <artifactId>springcould-api</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <!--spring boot的web启动器--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--热部署工具--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> </dependency></dependencies> -
项目配置文件配置,只需要配置端口号即可
server: port: 80
2.代码实现
-
接下来就是编写消费者的controller了,注意:消费者子model中没有service层,service层在提供者中,所以我们在消费者的controller层想要调用服务者提供的服务,我们需要通过请求服务者提供的API实现
-
但是我们怎么在消费者的controller中的方法中模拟浏览器向运行在其他服务器上8001端口的服务站发送请求呢?
-
在前面学习dubbo+zookeeper的时候,我们是通过注册中心完成提供者和消费者之间的联系的,即先将服务者向外提供的服务注册到注册中心中,而消费者使用dubbo的注解@Reference将注册中心中对应的实例注入到消费者的controller中,使得消费者就可以调用提供者向外提供的服务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5jss6WCH-1653575666171)(SpringCloud.assets/image-20211002142525296.png)]](https://img-blog.csdnimg.cn/9bf5f062175b4555b68b7644dab99882.png)
-
但是在讲解"SpringCloud(2) —— SpringCloud入门概述"的时候我们就说过了,Dubbo和SpringCloud最大的区别就是:Spring Cloud 抛弃了Dubbo的RPC通信,采用的是基于HTTP的REST方式
-
而在实际使用SpringCloud的时候,我们使用的步骤也很简单,直接在controller中添加一个RestTemplate对象的引用,然后自己编写一个config类将RestTemplate对象注入到spring容器中就可以使用这个类来模拟浏览器向服务器发送HTTP请求,这样就实现了客户端只需要知道服务端对应服务的请求就可以实现对于服务端提供的服务的调用
【补充:RestTemplate 】
-
RestTemplate 是从 Spring3.0 开始支持的一个 HTTP 请求工具,它提供了常见的REST请求方案的模版,例如 GET 请求、POST 请求、PUT 请求、DELETE 请求以及一些通用的请求执行方法 exchange 以及 execute。RestTemplate 继承自 InterceptingHttpAccessor 并且实现了 RestOperations 接口,其中 RestOperations 接口定义了基本的 RESTful 操作,这些操作在 RestTemplate 中都得到了实现
-
小结:RestTemplate就是用来模拟浏览器发送HTTP请求的一个包装类,它将整个步骤精简到只需要调RestTemplate.xxxForObject()就可以实现,XXX就是请求的方式,比如:get、post等,它是spring提供的一个简单的restful服务模板
-
3个参数可以简单理解为:从哪里获取服务器响应,本次请求需要携带的参数(可缺省,有对应的重载),服务器返回的数据的类型
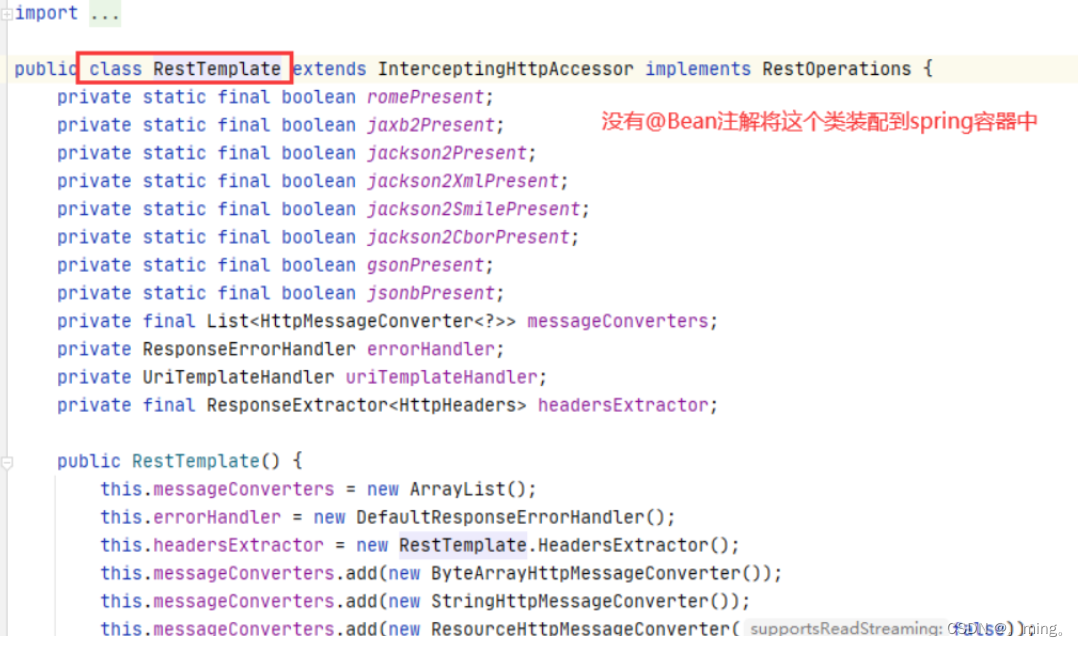
-
为什么要定义一个config类将将RestTemplate对象注入到spring容器中?原因当然是这个对象没有被spring boot自动装配到spring容器中,我们可以通过它的源码发现没有一个@Bean注解
-
好处:这完全实现了服务者和消费者的解耦,因为消费者获取服务者的服务就是按照HTTP请求的方式获取的;而原来使用dubbo+zookeeper的时候,我们需要在客户端写一个服务端提供服务的service的引用,然后在客户端调用该service的方法实现消费者对于提供者提供的服务的消费,这样显然两边是有耦合的
-
编写一个config类,将RestTemplate注入spring容器中
//@Configuration想法偶遇相当于spring中的applicationContext.xml@Configurationpublic class ConfigBean { @Bean public RestTemplate getRestTemplate(){ return new RestTemplate(); }} -
写一个控制层
@Controllerpublic class DeptConsumerController { //理解:消费者,不应该有service层,因为我是直接调用提供者的服务 //RestTemplate...供我们直接调用就可以了,注册到spring中 //(url,实体:map,Class<T> responseType) @Autowired private RestTemplate restTemplate; //请求服务者提供的服务的url的固定前缀,就是服务者程序的主机名+端口名。它的后面还应该接上对应服务的请求url/映射的地址 private static final String REST_URL_PREFIX = "http://localhost:8001"; @RequestMapping("/consumer/dept/add") public boolean add(Dept dept){ //三个参数分别是调用方的id,返回的参数,返回的类型 return restTemplate.postForObject(REST_URL_PREFIX+"/dept/add",dept,boolean.class); } @RequestMapping("/consumer/dept/queryById/{deptno}") public Dept queryById(@PathVariable("deptno") long id){ return restTemplate.getForObject(REST_URL_PREFIX+"/dept/queryById/"+id,Dept.class); } @RequestMapping("/consumer/dept/queryAll") public List<Dept> queryAll(){ return restTemplate.getForObject(REST_URL_PREFIX+"/dept/queryList",List.class); }} -
编写一个主函数入口
@SpringBootApplicationpublic class DeptConsumer_80 { public static void main(String[] args) { SpringApplication.run(DeptConsumer_80.class,args); }} -
通过上面的例子我们就实现了通过spring cloud的方式实现提供者和消费者之间的通信,这有别于前面学习的dubbo+zookeeper通过注册中心实现的方式,spring cloud利用了spring提供的RestTemplate对象模拟浏览器向服务器发送对应的服务请求,整个流程为:客户端–(请求消费者的API)–>消费者程序–(请求提供者的API)–>提供者,但是真正的服务提供的API是封装在消费者程序中的,它向正在的提供者进行访问的时候的URI也是封装在消费者程序中的,这样提高了服务的安全性
-
注意:这里踩坑了,在SpringBoot中如果有多个modul,会出现找不到或无法加载主类 ,这个时候能只要在该类中使用maven的clean和install方法即可
3.对比dubbo+zookeeper和spring cloud实现服务注册与发现
- 相比于dubbo+zookeeper,使用spring cloud中的RestTemplate,使用步骤相对更加的简单,并且封装性更好
- dubbo+zookeeper中消费者需要从远程注入提供者提供的服务实例对象才能消费服务,而spring cloud中的RestTemplate只需要服务站提供服务的API即可消费服务,并且将所有的操作都放在了提供者中;而消费者程序,只是起到了一个代替真实用户向提供者发送服务请求的作用
五,Eureka:什么是Eureka
1.什么是Eureka
- 读音
- Netflix在涉及Eureka时,遵循的就是API原则.
- Eureka是Netflix的有个子模块,也是核心模块之一。Eureka是基于REST的服务,用于定位服务,以实现云端中间件层服务发现和故障转移,服务注册与发现对于微服务来说是非常重要的,有了服务注册与发现,只需要使用服务的标识符,就可以访问到服务,而不需要修改服务调用的配置文件了,功能类似于Dubbo的注册中心,比如Zookeeper
2.Eureka原理理解
1.Eureka基本的架构
-
Springcloud 封装了Netflix公司开发的Eureka模块来实现服务注册与发现 (对比Zookeeper)
-
Eureka采用了C-S的架构设计,Eureka Server作为服务注册功能的服务器,它是服务注册中心
-
而系统中的其他微服务,使用Eureka的客户端连接到Eureka Server并维持心跳连接,这样系统的维护人员就可以通过Eureka Server来监控系统中各个微服务是否正常运行,Spring cloud 的一些其他模块 (比如Zuul) 就可以通过Eureka Server来发现系统中的其他微服务,并执行相关的逻辑
- 在dubbo+zookeeper中我们可以使用dubbo-admin来实现可视化的监控,在spring cloud中我们可以使用Eureka Server实现监控功能
-
Eureka和Dubbo对比
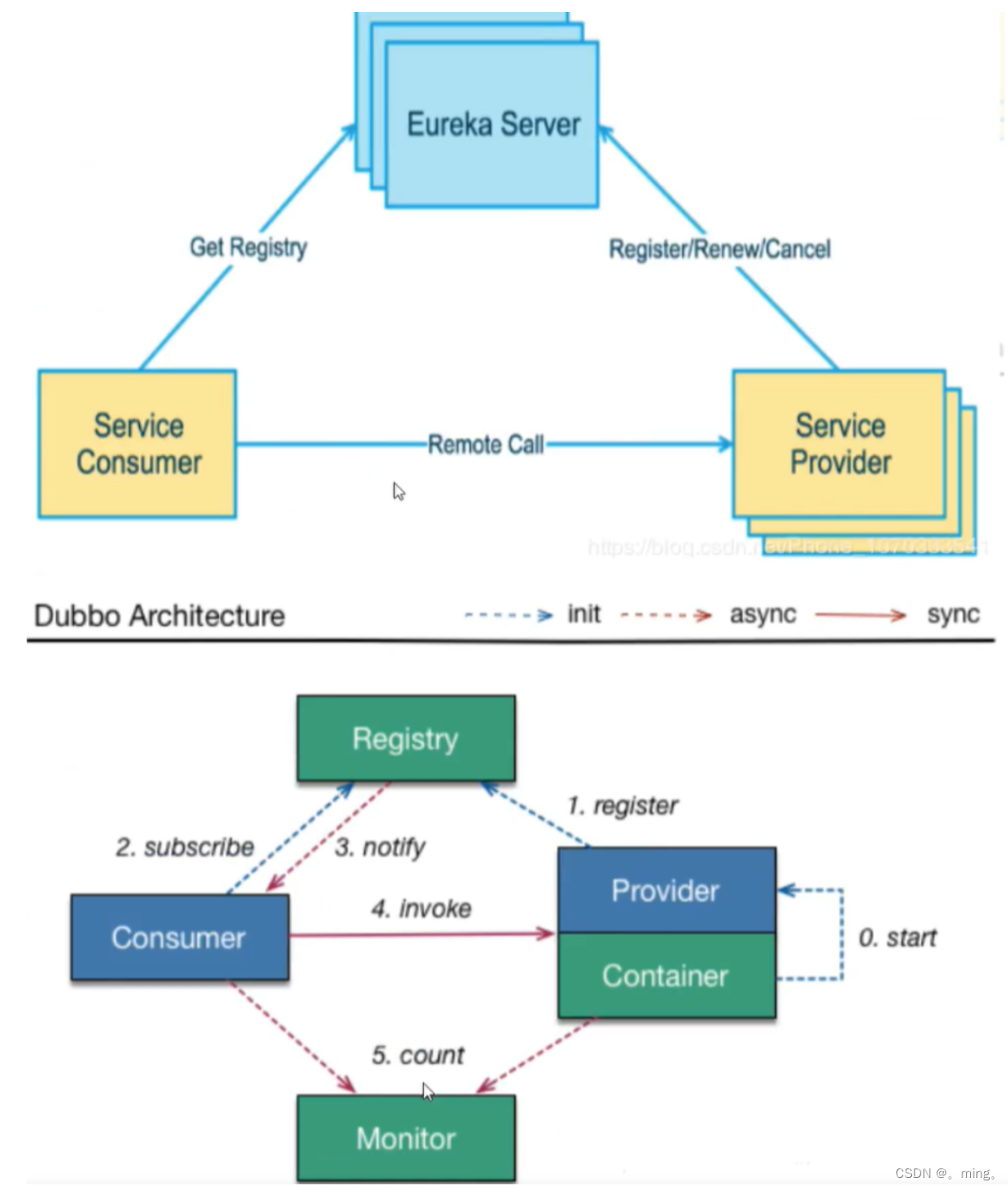
-
Eureka 包含两个组件:Eureka Server 和 Eureka Client
-
Eureka Server 提供服务注册,各个节点启动后,会在Eureka Server中进行注册,这样Eureka Server中的服务注册表中将会储存所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到
-
Eureka Client 是一个Java客户端,用于简化Eureka Server的交互,客户端同时也具备一个内置的,使用轮询负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳 (默认周期为30秒) 。如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除掉 (默认周期为90s)
-
Eureka 三大角色
- Eureka Server:提供服务的注册与发现
- Service Provider:服务生产方,将自身服务注册到Eureka中,从而使服务消费方能够找到
- Service Consumer:服务消费方,从Eureka中获取注册服务列表,从而获取可以进行消费的服务
-
原来的zookeeper的服务端不需要我们进行编写,只需要我们将下载的zookeeper中的服务端启动即可,但是Eureka的服务端需要我们自己进行编写,但是编写的步骤也很简单,只需要使用注解开启即可使用
3.代码实现Eureka注册中心
-
创建一个新的model,专门用来实现Eureka 注册中心,model名称为:springcould-eureka-7001
-
其实我们只需要导入需要的依赖,配置一些参数就可以实现Eureka注册中心,我们使用的监控页面还是我们导入的依赖自带的,我们只需要按照自己的需求修改一些注册中心的参数,并在spring boot项目的入口程序上添加注解@EnableEurekaServer即完成
-
导入依赖
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-eureka-server --><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka-server</artifactId> <version>1.4.7.RELEASE</version></dependency> -
还可以导入一个热部署依赖
<!--eureka依赖--><dependencies> <!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-eureka-server --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka-server</artifactId> <version>1.4.7.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> </dependency></dependencies> -
编写配置文件
server: port: 7001#eureka配置eureka: instance: hostname: localhost #eureka server运行的主机名,所以访问eureka监控页面的url为http://localhost:7001/ client: register-with-eureka: false #表示是否向eureka注册中心注册自己,但是由于这个子model本来就是用来充当eureka服务器/注册中心的,所以设置为false #这个属性设为false同时也就表明了这个微服务是eureka服务器程序 fetch-registry: false #fetch-registry为false表示这个微服务为eureka注册中心 service-url: defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/ #微服务提供者向注册中心的注册服务的地址,它有默认的url,为"http://localhost:7001/eureka/" #但是我们自己配置了eureka运行的主机名和端口号,所以我们在配置的时候不会将配置写死,而是获取上面我们的配置,这样后面更改的时候就只需要更改上面的显式配置,而不需要更改引用处的值 -
编写主启动类
package com.thhh.springcloud;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;@SpringBootApplication@EnableEurekaServer //开启EurekaServer,可以接收其他的服务注册进来public class EurekaServer_7001 { public static void main(String[] args) { SpringApplication.run(EurekaServer_7001.class,args); }} -
测试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FJ1PJZYf-1653576712334)(SpringCloud.assets/image-20211002150958353.png)]](https://img-blog.csdnimg.cn/f14297d488ee4a9dbdfed50d70db4a76.png)
-
到此eureka的注册中心我们就实现并启动了,我们可以小结一下我们从服务者、消费者,再到eureka的注册中心我们大概的实现步骤
- 创建子model
- 导入依赖【难点,需要导全需要的依赖】
- 编写配置文件【基本就是固定的配置,每写一个微服务,按照它的角色配置响应的参数即可,或者可以直接复制粘贴以前的来改】
- 【可选】编写实现当前微服务功能的代码,可能需要写完整的MVC 3层架构(服务提供者),也可能只需要写一个controller+一个RestTemplate(服务消费者)
- 编写入口程序/主启动类
- 【可选】如果有需要就要在入口程序/主启动类上加上对应的注解@EnableXXX
- 启动项目测试功能
六,Eureka:服务注册-信息配置-自我保护机制
1.服务注册
-
我们首先将前面写的服务提供者提供的服务注册到eureka注册中心中去
-
我们需要明白,作为注册中心它应该是被动的接收提供者需要注册的服务,而不是主动的去发现服务者提供了哪些服务,所以要将服务注册到注册中心中去,我们需要在服务者的微服务模块中进行注册
-
首先,在服务提供者的model中导入eureka的依赖:Spring Cloud Starter Eureka,用于和eureka server连接并注册自己的服务
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-eureka --><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactId> <version>1.4.7.RELEASE</version></dependency> -
配置文件配置要注册到的注册中心的配置
server: port: 8001 #端口号#mybatis配置mybatis: type-aliases-package: com.thhh.springcould.pojo #mybatis的别名扫描 mapper-locations: classpath:mybatis/mapper/*.xml #mybatis去哪里读取pojo对应的mapper接口的mapper.xml文件 config-location: classpath:mybatis/mybatis-config.xml #mybatis核心配置文件,可要可不要,不要就把配置写在spring配置中#spring配置spring: application: name: springcould-provider-dept datasource: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/db01?useSSL=false&useUnicode=true&characterEncoding=utf-8 username: root password: 123456#eureka的配置eureka: client: service-url: defaultZone: http://localhost:7001/eureka/ -
主启动类中加上注解支持
package com.thhh.springcould;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.cloud.netflix.eureka.EnableEurekaClient;@SpringBootApplication@EnableEurekaClient //标识这是一个eureka注册中心提供服务的客户端,加上配置文件中配置的注册中心的url,服务就会被自动注册到eureka注册中心中去public class DeptProvider_8001 { public static void main(String[] args) { SpringApplication.run(DeptProvider_8001.class,args); }} -
测试,注意:先将所有项目停掉,先启动eureka注册中心微服务,再启动服务提供者提供的微服务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kCONT65L-1653577473222)(SpringCloud.assets/image-20220311222357213.png)]](https://img-blog.csdnimg.cn/61c188e3b0e4459c8cea5d8a4536f0af.png)
2.信息配置
-
首先注册的服务有一个Application字段,它的值就是服务提供者在配置文件中为当前微服务取得名字
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lpE2b76r-1653577473222)(SpringCloud.assets/image-20211002155536444.png)]](https://img-blog.csdnimg.cn/f5ca4e1bb6894cf699844f0725cf66ff.png)
-
Status字段是对于这个注册的微服务的描述信息,我们可以自己进行修改/自定义,只需要在配置文件eureka节点上进行配置即可
#eureka的配置eureka: client: service-url: defaultZone: http://localhost:7001/eureka/ instance: instance-id: springcould-provider-dept-8001 #配置注册的服务的描述信息![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VbqDfsfc-1653577473223)(SpringCloud.assets/image-20211002155604058.png)]](https://img-blog.csdnimg.cn/495fce8dbd284dd0add7e5fd7f9ba575.png)
-
修改跳转的页面就是对于这个服务的监控信息,要配置监控信息,我们需要导入依赖
<!--eureka完善对应服务的监控信息依赖--><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId></dependency> -
配置文件配置要展示的信息
#完善监控信息展示info: app.name: dept服务者 #服务的名称 company.name: com.thhh -
测试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YBPEgeck-1653577473223)(SpringCloud.assets/image-20211002155656596.png)]](https://img-blog.csdnimg.cn/bd9e60b598e44fc0bacf012ee2b67d60.png)
-
可见,现在这个页面可以访问,并且将刚刚我们在配置文件中配置的数据作为一个JSON字符串返回在前端进行展示;这有什么用呢?主要在微服务过多的时候,起到别人点击之后可以快速了解这个微服务的一些基础信息
3.自我保护机制
-
当我们将注册到eureka注册中心中的某一个微服务重启的时候,再次刷新eureka监控页面,我们将会发现页面上多出了一行红字
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4oyONqDa-1653577473223)(SpringCloud.assets/image-20211002155911864.png)]](https://img-blog.csdnimg.cn/0feb4829999f4ec886b19fb614f4ce5d.png)
-
EureKa自我保护机制:好死不如赖活着
-
一句话总结就是:某时刻某一个微服务不可用,eureka不会立即清理,依旧会对该微服务的信息进行保存!
-
默认情况下,当eureka server在一定时间内没有收到实例的心跳,便会把该实例从注册表中删除(默认是90秒),但是,如果短时间内丢失大量的实例心跳,便会触发eureka server的自我保护机制,比如在开发测试时,需要频繁地重启微服务实例,但是我们很少会把eureka server一起重启(因为在开发过程中不会修改eureka注册中心),当一分钟内收到的心跳数大量减少时,会触发该保护机制。可以在eureka管理界面看到Renews threshold和Renews(last min),当后者(最后一分钟收到的心跳数)小于前者(心跳阈值)的时候,触发保护机制,会出现红色的警告:EMERGENCY!EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY’RE NOT.RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEGING EXPIRED JUST TO BE SAFE.从警告中可以看到,eureka认为虽然收不到实例的心跳,但它认为实例还是健康的,eureka会保护这些实例,不会把它们从注册表中删掉
-
该保护机制的目的是避免网络连接故障,在发生网络故障时,微服务和注册中心之间无法正常通信,但服务本身是健康的,不应该注销该服务,如果eureka因网络故障而把微服务误删了,那即使网络恢复了,该微服务也不会重新注册到eureka server了,因为只有在微服务启动的时候才会发起注册请求,后面只会发送心跳和服务列表请求,这样的话,该实例虽然是运行着,但永远不会被其它服务所感知。所以,eureka server在短时间内丢失过多的客户端心跳时,会进入自我保护模式,该模式下,eureka会保护注册表中的信息,不在注销任何微服务,当网络故障恢复后,eureka会自动退出保护模式。自我保护模式可以让集群更加健壮
-
但是我们在开发测试阶段,需要频繁地重启发布,如果触发了保护机制,则旧的服务实例没有被删除,这时请求有可能跑到旧的实例中,而该实例已经关闭了,这就导致请求错误,影响开发测试。所以,在开发测试阶段,我们可以把自我保护模式关闭,只需在eureka server配置文件中加上如下配置即可:eureka.server.enable-self-preservation=false【但是不推荐关闭EureKa自我保护机制】
4.扩展:服务发现 DiscoveryClient
-
注意:扩展的部分只是在你和别人一起进行分布式开发的时候才会使用,个人开发一般用不到
-
我们可以在服务者的controller中返回当前提供的微服务的详细信息,前面我们在配置文件中进行的信息配置其实都是我们自己一点点写上去的,显然没有获取已经配置好的参数来的爽和齐全,所以我们可以在服务者的controller中添加一个API接口,专门用户返回当前微服务的具体信息,具体效果如下图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nUJEnklH-1653577473223)(SpringCloud.assets/image-20211002160205340.png)]](https://img-blog.csdnimg.cn/5c980f8313b040418dac7d04bdacdd3e.png)
-
添加一个controller的方法,这个方法需要使用到一个接口DiscoveryClient,这个接口有几个实现,显然我们需要使用eureka的实现
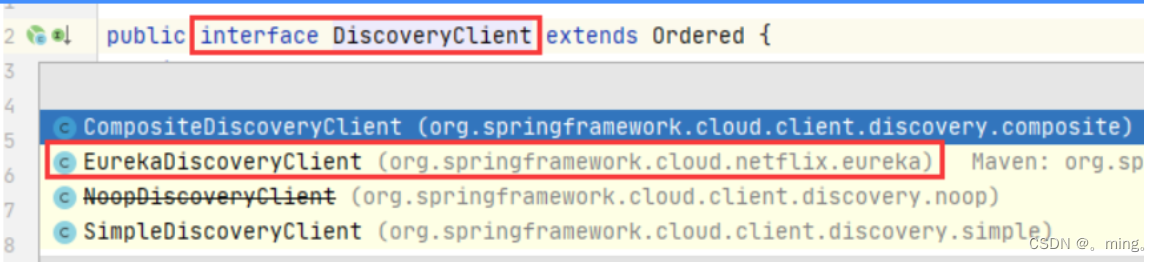
-
我们可以搜索一下接口实现类EurekaDiscoveryClient是否在spring cloud中有自动配置类,还真搜到了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xeIs4bR6-1653577473224)(SpringCloud.assets/image-20211002160258494.png)]](https://img-blog.csdnimg.cn/34d2356be0b04b938231e5e286c01e40.png)
-
所以我们只需要在controller中自动注入这个接口的实例即可
@Autowiredprivate DiscoveryClient discoveryClient; -
编写使用它的controller方法,这个方法中就只调用DiscoveryClient.getInstances()来获取指定的注册到注册中的的服务实例,注意:这个方法需要传入参数,参数就是注册的微服务在注册中心中Application字段的值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8c5ik2i5-1653577473224)(SpringCloud.assets/image-20211002160327097.png)]](https://img-blog.csdnimg.cn/4ffb62b714454925ada0599066a52838.png)
@GetMapping("/dept/discovery")public Object discovery(){ List<ServiceInstance> instanceList = discoveryClient.getInstances("SPRINGCOULD-PROVIDER-DEPT");//通过注册的微服务的id来获取注册的微服务实例 for (ServiceInstance instance: instanceList) { System.out.println( //输出获取到的注册的微服务实例的信息 instance.getHost()+"\t"+ instance.getUri()+"\t"+ instance.getPort()+"\t"+ instance.getServiceId()+"\t"+ instance.getMetadata()+"\t"+ instance.getScheme()+"\t"+ instance.getInstanceId() ); } return instanceList;} -
可见,通过getInstances()可以获取所有同名称注册的微服务list集合,我们通过foreach遍历取到集合中的ServiceInstance对象,即服务实例对象,这些服务实例对象就是在注册中心中注册的提供服务的微服务对象,所以我们可以通过"."获取到当前遍历到的这个微服务几乎所有重要的数据,比如我们上面输出的数据,我们可以通过输出效果来反观这些属性的作用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jEEVhqBS-1653577473224)(SpringCloud.assets/image-20211002160448151.png)]](https://img-blog.csdnimg.cn/7441a21d5588461aa6a305a3e2356e07.png)
-
在方法的最后,我将获取到的服务实例对象集合返回了出去,前端将会收到这个集合中数据的JSON格式数据,由于前端只有一个对象,所以获取到的应该是只有一个服务对象的JSON字符串
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U4T8izX3-1653577473224)(SpringCloud.assets/image-20211002160501505.png)]](https://img-blog.csdnimg.cn/69e029f7aafb42f7b3ee94038de4d7e0.png)
-
我们可以使用火狐浏览器,它对JSON数据进行了比较好的格式解析
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YiLsg3oh-1653577473225)(SpringCloud.assets/image-20211002160533249.png)]](https://img-blog.csdnimg.cn/32f2714a953c479ba5ad899c9a75dd3d.png)
-
通过上图我们就可以获取到当前微服务对象的详细信息
七,Eureka:集群环境配置
1.环境准备
-
这里我们实现的是注册中心的集群配置,比如这里我们实现3个注册中心

-
由于是实现集群,所以基本都只需要复制粘贴,修改对应端口即使投入使用
-
首先导入3个集群的依赖,保持相同
<!--eureka依赖--> <dependencies> <!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-eureka-server --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka-server</artifactId> <version>1.4.7.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> </dependency></dependencies> -
粘贴7001中的application.yml,修改服务端口
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gaWhElHb-1653578575112)(SpringCloud.assets/image-20211002171224512.png)]](https://img-blog.csdnimg.cn/3d9831ede88346309d35d4bb80f678df.png)
-
为7002和7003粘贴入口程序
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WupanHI4-1653578575112)(SpringCloud.assets/image-20211002171241210.png)]](https://img-blog.csdnimg.cn/2270262cdd064c7684cf1ef057a1c54f.png)
-
到此,3个注册中心就搭建完成了
-
随便启动一个注册中心,看看能不能正常访问监控页面,如果能表明上面的操作都是正确的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GOz22h3n-1653578575112)(SpringCloud.assets/image-20211002171502400.png)]](https://img-blog.csdnimg.cn/bed5277639204049b808ea89f2ed7f2b.png)
-
注册中心是搭建完成了,但是3个注册中心是相互独立的,那么怎么实现集群呢?我们可以在7001中绑定7002和7003,另外两个同理,这样当7001出问题了/不能正常服务的时候将让请求转到7002/7003上,另外两个同理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1z35xsIa-1653578575112)(SpringCloud.assets/image-20211002171534919.png)]](https://img-blog.csdnimg.cn/e2a52f71bb064cb9850afe7969a24d38.png)
2.代码实现
-
首先,我们3个注册中心的hostname都叫localhost,为了便于区分以及更像真实情况,我们可以去修改本地的HOSTS文件中127.0.0.1的映射,文件路径:C:\Windows\System32\drivers\etc
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DSi0YERA-1653578575113)(SpringCloud.assets/image-20211002171604529.png)]](https://img-blog.csdnimg.cn/e5442b28a86c47368fb2f6ca38eed324.png)
-
保存推退出,并去对应的注册中心微服务的配置文件中修改hostname的值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ygKSsVGB-1653578575113)(SpringCloud.assets/image-20211002171623158.png)]](https://img-blog.csdnimg.cn/37afd2440bb84ecdacffebf2e73c92b8.png)
-
接下来就是关联eureka7001、eureka7002、eureka7003,关联的操作很简单,直接修改配置文件中的defaultZone节点的值为所有集群中注册中心的注册服务的url,比如7001原来服务者向它内部注册服务的url为:http:// $ {eureka.instance.hostname}: ${server.port}/eureka/,进行集群之后需要修改为
7001注册中心:defaultZone: http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/7002注册中心:defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7003.com:7003/eureka/7003注册中心:defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/ -
就是将向自己这个注册中心的url修改为其他两个注册中心的url,并列的两个使用","隔开即可
-
现在我们需要修改提供者提供的服务向集群中所有的注册中心都发布
#eureka的配置eureka: client: service-url: defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ instance: instance-id: springcould-provider-dept-8001 #配置注册的服务的描述信息 -
也就是去修改提供者的application配置文件中的defaultZone节点的值,将需要发布的注册中心的defaultZone的值全部写上即可
-
测试
-
关闭所有服务,再将3个注册中心全都启动起来,然后再启动服务提供者
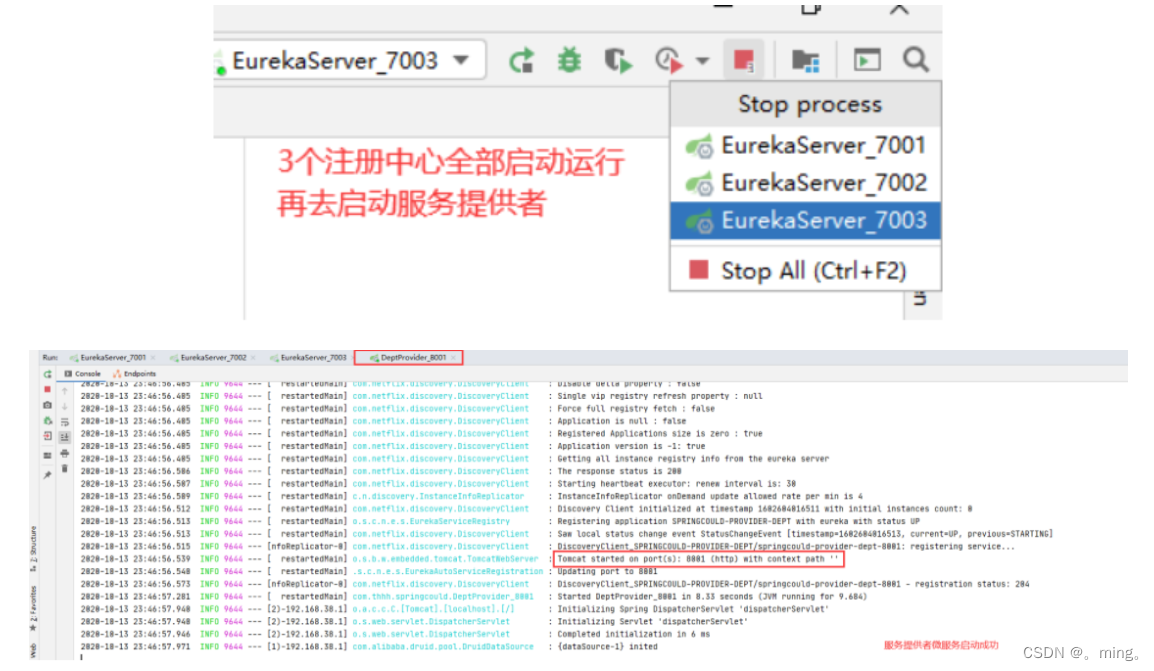
-
-
页面访问测试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tl8JES3A-1653578575114)(SpringCloud.assets/image-20211002171843861.png)]](https://img-blog.csdnimg.cn/b9c2e1bc97aa41b7b5a3ab2a4e999b84.png)
3.小结
-
通过以上的案例我们就实现了Eureka中注册中心的集群环境配置
-
小结一下步骤
- 创建3个平行的eureka注册中心子model
- 配置3个注册中心的配置文件【注意端口和hostname不一样,3个配置文件中的defaultZone节点的值为其他两个注册中心的defaultZone在单机情况下的值,两个defaultZone值之间使用","隔开】
- 编写3个注册中心的入口程序
- 启动3个注册中心微服务
- 编写提供微服务的服务者的配置文件【它的defaultZone中需要将上面集群的3个注册中心的defaultZone在单机情况下的值全都写上】
- 启动提供微服务的服务者的微服务model
- 访问3个集群的eureka注册中心的监视页面验证页面上是否挂载了其他两个注册中心服务者向它们注册服务时的url,以及服务者注册的服务是否成功注册到本注册中心
-
整个eureka注册中心的集群核心就是下面这张图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JMDuzz6O-1653578575114)(SpringCloud.assets/image-20211002172258135.png)]](https://img-blog.csdnimg.cn/4c215bf6c03a406d853c410851687b28.png)
八,Eureka:CAP原则及对比zookeeper
1.CAP原则
- RDBMS (MySQL\Oracle\sqlServer) ===> ACID【关系型数据库遵循的特性】
- NoSQL (Redis\MongoDB) ===> CAP【非关系型数据库遵循的特性】
2.ACID是什么?
- A (Atomicity) 原子性
- C (Consistency) 一致性
- I (Isolation) 隔离性
- D (Durability) 持久性
3.CAP是什么?
- C (Consistency) 强一致性
- A (Availability) 可用性
- P (Partition tolerance) 分区容错性
在分布式系统中最多只能保证上面3个特点中的两个同时满足,所以就出现了CAP的三进二特性,CAP的三进二:CA、AP、CP
4.CAP理论的核心
- 一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求
- 根据CAP原理,将NoSQL数据库分成了满足CA原则,满足CP原则和满足AP原则三大类
- CA:单点集群,满足一致性,可用性的系统,通常可扩展性较差
- CP:满足一致性,分区容错的系统,通常性能不是特别高
- AP:满足可用性,分区容错的系统,通常可能对一致性要求低一些
5.作为分布式服务注册中心,Eureka比Zookeeper好在哪里?
著名的CAP理论指出,一个分布式系统不可能同时满足C (一致性) 、A (可用性) 、P (容错性),由于分区容错性P在分布式系统中是必须要保证的,因此我们只能再A和C之间进行权衡,即三进二变为了2选1
- Zookeeper 保证的是CP【满足一致性,分区容错的系统,通常性能不是特别高】
- Eureka 保证的是AP【满足可用性,分区容错的系统,通常可能对一致性要求低一些】
Zookeeper保证的是CP
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息【可用性降低】,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但zookeeper会出现这样一种情况:当master节点(即主节点或称为注册中心)因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30-120s,且选举期间整个zookeeper集群是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因为网络问题使得zookeeper集群失去master节点是较大概率发生的事件,虽然服务最终能够恢复,但是,漫长的选举时间导致注册长期不可用,是不可容忍的
Eureka保证的是AP
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的(就是我们前面做的注册中心的集群保证了各个节点之间是平等的,因为集群的注册中心会相互挂载其他注册中心的注册服务的地址),几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册中心进行注册时,如果发现连接失败,则会自动切换至其他节点,只要有一台Eureka还在,就能保住注册服务的可用性,只不过查到的信息可能不是最新的,除此之外,Eureka还有之中自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点上 (即保证当前节点依然可用)【同步性降低】
- 当网络稳定时,当前实例新的注册信息会被同步到其他节点中【弥补降低的同步性】
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪,所以在选择的时候我们更倾向Eureka。
九,Ribbon:负载均衡及Ribbon
1.Ribbon是什么?
- Spring Cloud Ribbon 是基于Netflix Ribbon 实现的一套 客户端 负载均衡 的工具
- 3个关键词,表明了Ribbon 是与客户端相关的,所以我们在使用它的时候需要在客户端的中使用;并且它是实现客户端负载均衡的一个工具;
- 对于负载均衡就是对于集群技术中每个站点使用不均衡的情况,简单的解决办法可以使用轮询解决集群中的服务器均摊客户端请求,除了使用轮询我们还可以使用hash随机算法,每次随机选中一个集群服务器处理客户端的请求
- 简单的说,Ribbon 是 Netflix 发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将 Netflix 的中间层服务连接在一起。Ribbon 的客户端组件提供一系列完整的配置项,如:连接超时、重试等。简单的说,就是在配置文件中列出 LoadBalancer (简称LB:负载均衡) 后面所有的集群服务器,Ribbon 会自动的帮助你基于某种规则 (如简单轮询,随机连接等等) 去连接这些服务器,我们也容易使用 Ribbon 实现自定义的负载均衡算法!
- 面试造飞机,工作拧螺丝
2.Ribbon的作用
- LB,即负载均衡 (LoadBalancer) ,在微服务或分布式集群中经常用的一种应用。
- 负载均衡简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA (高可用)
- 常见的负载均衡软件有 Nginx、Lvs 等等
- Dubbo、SpringCloud 中均给我们提供了负载均衡,SpringCloud 的负载均衡算法可以自定义
- 负载均衡简单分类:
- 集中式LB(在消费者请求到达服务器集群之前,首先通过服务器集群前面运行着负载均衡程序的服务器,由它来决定消费者的这个请求发送到服务器集群中的哪一台服务器上进行处理)
- 即在服务的提供方和消费方之间使用独立的LB设施,如Nginx:反向代理服务器,由该设施负责把访问请求通过某种策略转发至服务的提供方!
- 进程式LB(将负载均衡的处理交给用户,即消费者在本地发送请求的时候就已经知道了自己应该将这个请求发送到集群服务器中的那一台具体的服务器进行处理,这是由集成在客户端的负载均衡算法实现的)
- 将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用(负载均衡的依据),然后自己再从这些地址中选出一个合适的服务器
- Ribbon 就属于进程内LB,它只是一个类库,集成于消费方进程,消费方通过它来获取到服务提供方的地址
- 集中式LB(在消费者请求到达服务器集群之前,首先通过服务器集群前面运行着负载均衡程序的服务器,由它来决定消费者的这个请求发送到服务器集群中的哪一台服务器上进行处理)
3. 集成Ribbon
- 导入依赖,首先是要继承ribbon,所以它的依赖一定需要,再者是ribbon需要连接eureka的注册中心获取已经注册的服务列表,所以我们还需要eureka的依赖
<!-- Ribbon --><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-ribbon</artifactId> <version>1.4.7.RELEASE</version></dependency><!--eureka--><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactId> <version>1.4.7.RELEASE</version></dependency>-
编写消费者微服务中的配置文件,配置eureka
#eureka配置eureka: client: register-with-eureka: false #表示不向eureka中注册自己,即表明自己是一个消费者 service-url: defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ #配置可以连接的eureka注册中心的url -
启动eureka客户端,即加上注解@EnableEurekaClient
-
上面的操作只是使得客户端可以连接eureka获取并消费服务提供者提供的服务,真正的负载均衡要怎么配置呢?在前面我们说过了ribbon是将负载均衡集成在了客户端,在客户端发出请求的时候进行负载均衡,所以要实现负载均衡,我们只需要修改消费者发出服务请求的代码即可
-
在前面我们讲解了,在spring cloud中消费者请求可以消费的服务依赖的是spring的一个工具类RestTemplate,通过它模拟浏览器向注册中心发送服务请求,所以我们只需要对这个类进行改造,使得它在发送请求之前进行负载均衡即可;实现方法很简单,只需要在将这个类装配到spring容器中的方法上添加一个注解@LoadBalanced即可
@Configuration //spring容器的配置类public class ConfigBean { @Bean @LoadBalanced public RestTemplate getRestTemplate(){ return new RestTemplate(); }} -
在前面搭建消费者环境的时候,还没有使用注册中心,所以消费者的controller代码中我们将服务者的请求地址写死在了代码中
private static final String REST_URL_PREFIX = "http://localhost:8001/";//请求服务者提供的服务的url的固定前缀,就是服务者程序的主机名+端口名。它的后面还应该接上对应服务的请求url/映射的地址![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QhJkUxzH-1653614360561)(SpringCloud.assets/image-20211002224316430.png)]](https://img-blog.csdnimg.cn/d6b3f15e7f734feca40496871c437f93.png)
-
但是现在我们使用了注册中心,并且已经将服务提供者提供的服务成功的注册到了注册中心中,我们的消费者就不应该再使用写死的url进行拼接来获取服务提供者提供的服务,而是应该通过注册中心获取服务进行消费
-
消费者从注册中心获取指定服务的方法就是通过服务名称/注册的服务的application字段的值来获取该服务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QqmFquOh-1653614360562)(SpringCloud.assets/image-20211002224404331.png)]](https://img-blog.csdnimg.cn/e7611135c6ae498ea2eb3c3826800f02.png)
-
测试
-
先启动注册中心集群,再启动服务提供者微服务,最后启动服务消费者
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ByTM02xA-1653614360563)(SpringCloud.assets/image-20211002224451393.png)]](https://img-blog.csdnimg.cn/82f98f328e5f4505ae31419acaa485f4.png)
-
4.小结
- 通过上面的例子,我们可以发现,消费者在请求服务的时候是通过服务者提供的服务名称实现的,这样做的好处在于客户端不需要关心服务提供者的主机名、服务运行的端口号,只需要知道自己想要消费的服务在注册中心的名称,及这个获取具体服务的API(即服务提供者在controller中暴露的API)即可消费服务
- 但是上面的好处只是eureka作为注册中心实现的,与我们使用的ribbon没有显式的关系,原因就是我们的服务提供者只有一个,所以ribbon并不能进行负载均衡,为了测试ribbon的作用,我们应该实现服务提供者的集群,具体做法在下一篇博客中讲述
十,Ribbon:使用Ribbon实现负载均衡
1.实现服务提供者集群
-
在上一章中,我们只是在消费者端集成了ribbon,但是并没有明显的感受到ribbon的作用,原因是因为我们的服务提供者只有一个,不是集群,ribbon不能进行负载均衡,所以为了测试ribbon的功能,我们需要实现服务提供者的集群
-
现在已有的服务提供者端口为8001,扩展两个服务提供者8002和8003,但是需要注意:前面在编写服务消费者的时候虽然模块名称上写的是80端口,但是在实际使用的时候发现80端口已经被占用,所以改成使用其他端口,就改成了8002端口,这就和下面要实现的一个注册服务提供者的端口冲突了,所以决定将消费者端口改为9001,模块名称上还是保留80
-
首先创建两个服务者模块的数据库,和第一个服务者的数据库除了名字以外以他的都相同
-
直接将db1数据库导出备份,获取到创建的sql语句
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7ofrRcHx-1653614980437)(SpringCloud.assets/image-20211002231327448.png)]](https://img-blog.csdnimg.cn/4b0329ea00104d388e8b9613015be03a.png)
-
通过标识db_source可以知道这一条数据到底来自哪一个数据库
-
创建了数据库就要去创建对应的服务提供者子model
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sXqNLdC2-1653614980438)(SpringCloud.assets/image-20211002231354560.png)]](https://img-blog.csdnimg.cn/e485e61f9435492889d607a01253ccc6.png)
-
导入依赖,和8001相同
<dependencies> <!--eureka完善对应服务的监控信息依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--eureka的服务提供者的依赖--> <!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-eureka --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactId> <version>1.4.7.RELEASE</version> </dependency> <!--实体类dept依赖--> <dependency> <groupId>com.thhh</groupId> <artifactId>springcould-api</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <!--单元测试--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> </dependency> <!--数据库依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> </dependency> <!--logback依赖,讲解:https://zhuanlan.zhihu.com/p/136893269--> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> </dependency> <!--mybatis依赖--> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> </dependency> <!--spring boot的web启动器--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--spring boot的测试依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-test</artifactId> </dependency> <!--jetty--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jetty</artifactId> </dependency> <!--热部署依赖:写完项目之后可以不重启项目,而是刷新一下就可以更新最新改动的资源到项目中--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> </dependency></dependencies> -
编写8002和8003的配置文件,可以直接粘贴8001的配置文件,然后进行对应的修改
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XHRNXfnW-1653614980439)(SpringCloud.assets/image-20211002231444180.png)]](https://img-blog.csdnimg.cn/8462c2805f90465f8b85089fb3e3da6c.png)
-
可见,注册中心已经接受到了同一个服务名称的3个服务提供者注册的服务的集群,在监控页面显式的就是同一个注册名称后面的Status字段有3个不同的instanceid展示,点击访问可以看到3个集群的服务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nsHkQlhY-1653614980439)(SpringCloud.assets/image-20211002231603930.png)]](https://img-blog.csdnimg.cn/bceb6a67071c47a4a9f621cc029fa901.png)
-
可以从上面结果看出ribbon默认实现的负载均衡是轮询
-
注意:前面我们做了注册中心的集群是为了注册中心的高可用,当一个注册中心崩了服务还能使用其他注册中心提供的服务继续使用;现在我们做了提供者的集群,这是为了服务提供者提供的服务的高可用,当一个服务者崩了,集群中的其他服务者还可以顶上继续提供正常的服务
-
其中,ribbon是用于在消费者请求服务提供者提供的服务的时候实现负载均衡
十一,Ribbon:自定义负载均衡算法
1.切换ribbon自带的负载均衡算法
-
在上一篇博客中我们测试了ribbon的默认负载均衡算法,就是轮询,但是我们还可以自定义它的负载均衡算法,代替它的默认轮询算法
-
在自己实现策略之前,还是按照原来的套路,先去看看ribbon怎么实现的负载均衡算法,我们在客户端集成ribbon实现负载均衡的时候只是导入了ribbon的依赖,并自定义了一个config类,用于编写一个@Bean方法将RestTemplate对象装配到spring容器中,并在该@Bean方法上使用了注解@LoadBalanced用于开启客户端使用ribbon实现负载均衡
-
所以我们需要去注解@LoadBalanced中查询ribbon实现的负载均衡的算法,但是通过查看注解@LoadBalanced的源码我们可以发现,这个注解中并没有什么特别的地方,所以就去百度了一下,通过百度结果我们可以发现ribbon的负载均衡算法实现都是根据接口IRule实现的,所以我们可以看看这个接口的源码
public interface IRule { Server choose(Object var1); void setLoadBalancer(ILoadBalancer var1); ILoadBalancer getLoadBalancer();} -
可以发现这个接口中主要的就是设置负载均衡的算法(setLoadBalancer())和设置选中的server(choose())两个方法,所以我们需要参考的实行类来实现自定义负载均衡算法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iR1Jr4Ih-1653615477757)(SpringCloud.assets/image-20211003000009954.png)]](https://img-blog.csdnimg.cn/9c17f5d4292e43a782577b40ee1dadf3.png)
-
第一个一般不会使用
-
AvailabilityFilteringRule:用于首先过滤掉已经崩溃的服务者提供的服务(或者说已经跳闸的服务),即先过滤掉已经故障的服务,然后再在剩下的服务中进行轮询【所以AvailabilityFilteringRule就是优化版的轮询】
-
RoundRobinRule:就是我们说的轮询策略
-
RandomRule:这也是我们前面说过的随机策略
-
WeightedResponseTimeRule:就是按照权重实现负载均衡
-
RetryRule:首先使用轮询获取服务,如果获取的服务跳闸了,就会在指定的时间内进行重连
-
测试默认轮询效果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7fDcyqK9-1653615477758)(SpringCloud.assets/image-20211003000107721.png)]](https://img-blog.csdnimg.cn/1df4c8c37f2d42af8cceaf6d557b2d54.png)
-
使用ribbon自己提供的随机负载均衡算法,只需要在config类中将RandomRule对象注入spring容器中即可
@Beanpublic IRule myRule(){ return new RandomRule();}![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lQQVmE0N-1653615477758)(SpringCloud.assets/image-20211003000152098.png)]](https://img-blog.csdnimg.cn/2ab763a6491742f981f4c6130d654579.png)
-
通过上面的测试效果,我们可以发现只要将不同的ribbon的负载均衡策略的实现类通过config类装配到spring容器中,就可以实现ribbon不同的负载均衡算法的切换,上面的例子中就是要了默认算法轮询和指定算法随机,开启消费者model之后都是刷新3次查看结果
-
所以我们自己在实现了自定义负载均衡算法之后,也需要将实现的算法类通过config类装配到spring容器中去
2.分析如何实现ribbon的自定义负载均衡算法
-
以上就是常用的几种ribbon实现负载均衡的算法,我们可以观察它的的共性,然后照猫画虎实现自定义的负载均衡算法
-
首先上面的这些是实行类都直接或间接的继承了一个IRule接口的实行类AbstractLoadBalancerRule,所以我们自己实现的时候也应该去继承它,除此之外实行类的具体实现还是需要具体的去参考1-2个ribbon的具体实行类,这里我们就参考最经典的轮询算法的实现
-
ribbon中轮询算法实现源码
public class RoundRobinRule extends AbstractLoadBalancerRule { private AtomicInteger nextServerCyclicCounter; private static final boolean AVAILABLE_ONLY_SERVERS = true; private static final boolean ALL_SERVERS = false; private static Logger log = LoggerFactory.getLogger(RoundRobinRule.class); public RoundRobinRule() { this.nextServerCyclicCounter = new AtomicInteger(0); } public RoundRobinRule(ILoadBalancer lb) { this(); this.setLoadBalancer(lb); } public Server choose(ILoadBalancer lb, Object key) { if (lb == null) { log.warn("no load balancer"); return null; } else { Server server = null; int count = 0; while(true) { if (server == null && count++ < 10) { List<Server> reachableServers = lb.getReachableServers(); List<Server> allServers = lb.getAllServers(); int upCount = reachableServers.size(); int serverCount = allServers.size(); if (upCount != 0 && serverCount != 0) { int nextServerIndex = this.incrementAndGetModulo(serverCount); server = (Server)allServers.get(nextServerIndex); if (server == null) { Thread.yield(); } else { if (server.isAlive() && server.isReadyToServe()) { return server; } server = null; } continue; } log.warn("No up servers available from load balancer: " + lb); return null; } if (count >= 10) { log.warn("No available alive servers after 10 tries from load balancer: " + lb); } return server; } } } private int incrementAndGetModulo(int modulo) { int current; int next; do { current = this.nextServerCyclicCounter.get(); next = (current + 1) % modulo; } while(!this.nextServerCyclicCounter.compareAndSet(current, next)); return next; } public Server choose(Object key) { return this.choose(this.getLoadBalancer(), key); } public void initWithNiwsConfig(IClientConfig clientConfig) { }} -
我们主要找这个类怎么实现的IRule中的choose方法(即选中哪一个server的算法)
public Server choose(ILoadBalancer lb, Object key) { if (lb == null) { log.warn("no load balancer"); return null; } Server server = null; int count = 0;//初始计数=0 while (server == null && count++ < 10) {//count++ List<Server> reachableServers = lb.getReachableServers();//获取可访问的server/在线的server List<Server> allServers = lb.getAllServers();//获取所有server int upCount = reachableServers.size();//获取list的大小 int serverCount = allServers.size();//获取list的大小 if ((upCount == 0) || (serverCount == 0)) {//如果上面的两个list有一个=0,则不进行轮询 log.warn("No up servers available from load balancer: " + lb); return null; } int nextServerIndex = incrementAndGetModulo(serverCount);//下一个server在list中的下标 server = allServers.get(nextServerIndex);//获取对应的server if (server == null) {//server为空就线程礼让 /* Transient. */ Thread.yield(); continue; } if (server.isAlive() && (server.isReadyToServe())) {//对应的server在线并且可以提供服务,就返回当前的server return (server); } // Next. server = null; } if (count >= 10) {//上面的负载均衡器尝试10次后还没有获得到可用的、活跃的/在线的 server,返回null log.warn("No available alive servers after 10 tries from load balancer: " + lb); } return server;} -
自定义ribbon负载均衡算法/ribbon客户端
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C462SaNa-1653615477759)(SpringCloud.assets/image-20211003000327015.png)]](https://img-blog.csdnimg.cn/e6a87270975b4fb7a4aea1dcdd2acc9a.png)
-
注解@RibbonClient中的name属性用于指定注册中心中需要使用我们自定义的ribbon策略实现负载均衡的服务者集群
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y9vuPoWb-1653615477759)(SpringCloud.assets/image-20211003000420434.png)]](https://img-blog.csdnimg.cn/79e3a90b133a42e886d38d5e6290a0b5.png)
-
注解@RibbonClient中的configuration属性用于指定我们自定义的实现Ribbon的负载均衡算法的类的class对象
-
注意:注解@RibbonClient中的name属性用于指定注册中心的哪一个服务集群使用我们自定义的负载均衡策略,所以我们就不能直接将我们定义的自定义负载均衡类放在spring boot项目自动扫描的包路径下,即不能放在spring boot项目的入口程序的同级目录的文件夹中,所以我们不能直接将自定义的负载均衡类装配到原来定义好的config类中;
-
按照官方doc的解释,这是因为只要我们将自定义的类放在了spring boot项目的入口程序的同级目录的文件夹中,那么我们自定义的负载均衡策略将对注册中心中所有的服务提供者提供的服务集群生效,而不能实现只在我们指定的服务提供者提供的服务集群上生效,所以我们需要在非spring boot项目的入口程序的同级目录的文件夹中创建一个config类,为这个类加上注解@Configuration和注解@RibbonClient(name = “要应用自定义负载均衡策略的服务集群名称”,configuration = 自定义的负载均衡的类.class),最后在内部写一个@Bean方法将我们自定义的负载均衡类装配到spring容器中
-
我们可以模仿某一个ribbon已经实现了的算法进行自定义负载均衡算法编写,比如ribbon实现的随机算法
package com.netflix.loadbalancer;import com.netflix.client.config.IClientConfig;import java.util.List;import java.util.concurrent.ThreadLocalRandom;public class RandomRule extends AbstractLoadBalancerRule { // @edu.umd.cs.findbugs.annotations.SuppressWarnings(value = "RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE") public Server choose(ILoadBalancer lb, Object key) { if (lb == null) { return null; } Server server = null; while (server == null) { if (Thread.interrupted()) {//线程被中断就直接结束方法调用 return null; } List<Server> upList = lb.getReachableServers();//获取在线的、可以提供服务的服务list List<Server> allList = lb.getAllServers();//获取所有的服务 int serverCount = allList.size();//获取所有的服务的个数 if (serverCount == 0) {//如果注册中心中没有服务可以获取就直接结束方法调用 return null; } int index = chooseRandomInt(serverCount);//获取随机数 server = upList.get(index);//随机数作为下标从在线的、可以提供服务的服务list中获取一个Server if (server == null) {//如果获取到的Server对象为null,线程礼让并结束本次循环 Thread.yield(); continue; } if (server.isAlive()) {//如果服务可以被消费 return (server);//返回该服务对象,即选中这一次使用这个服务进行消费 } server = null;//将server变量清空,使得下一次获取的服务为使用上面的步骤重新挑选出来的server对象 Thread.yield();//线程礼让 } return server; } protected int chooseRandomInt(int serverCount) { return ThreadLocalRandom.current().nextInt(serverCount); }@Overridepublic Server choose(Object key) {return choose(getLoadBalancer(), key);}@Overridepublic void initWithNiwsConfig(IClientConfig clientConfig) {// TODO Auto-generated method stub}} -
我们的算法目标:每个集群中某一个服务者提供的服务被访问5次,5次之后才换下一个集群中的服务者提供的服务
-
思考:当我们现在集群的3个服务全都被执行了5次之后怎么办?应该设置一个计算器count,默认为0,一旦计数到达5就将其清零并跳转使用下一个可以消费的服务;但是3个服务怎么切换?再使用一个下标指示值index,默认为0,当count>=5的时候index+1,当index>=3的时候,就将index置0
3.代码实现
-
编写Ribbon自定义负载均衡算法类
package com.zhao.myrule;/** * ************************************************************************ * 项目名称: springcloud <br/> * 文件名称: <br/> * 文件描述: 这里添加您的类文件描述,说明当前文件要包含的功能。 <br/> * 文件创建:赵先生 <br/> * 创建时间: 2021/10/2 <br/> * 山西优逸客科技有限公司 Copyright (c) All Rights Reserved. <br/> * * @version v1.0 <br/> * @update [序号][日期YYYY-MM-DD][更改人姓名][变更描述]<br/> * ************************************************************************ */import com.netflix.client.config.IClientConfig;import com.netflix.loadbalancer.AbstractLoadBalancerRule;import com.netflix.loadbalancer.ILoadBalancer;import com.netflix.loadbalancer.Server;import org.springframework.context.annotation.Configuration;import java.util.List;import java.util.concurrent.ThreadLocalRandom;/** * @ProjectName: springcloud * @ClassName: myRandomRule * @Description: 请描述该类的功能 * @Author: 赵先生 * @Date: 2021/10/2 23:37 * @version v1.0 * Copyright (c) All Rights Reserved,山西优逸客科技有限公司,. */@Configurationpublic class myRandomRule extends AbstractLoadBalancerRule { //每个服务,访问五次,换下一个服务(3个) //count=0 默认为0,如果是五的话index加一 private int count = 0;//一个服务被调用的次数计数 private int index = 0;//当前提供服务的server的下标 //@edu.umd.cs.findbugs.annotations.SuppressWarnings(value = "RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE") public Server choose(ILoadBalancer lb, Object key) { if (lb == null) { return null; } Server server = null; while (server == null) {//线程被中断就直接结束方法调用 if (Thread.interrupted()) { return null; } List<Server> upList = lb.getReachableServers();//获取在线的、可以提供服务的服务list List<Server> allList = lb.getAllServers();//获取所有的服务 int serverCount = allList.size();//获取所有的服务的个数 if (serverCount == 0) { //如果注册中心中没有服务可以获取就直接结束方法调用 return null; }/* int index = chooseRandomInt(serverCount);//获取随机数 server = upList.get(index);*///随机数作为下标从在线的、可以提供服务的服务list中获取一个Server //======================================= if (count < 5){ server = upList.get(index); count++; } else { count = 0; index++; if (index > upList.size()){ index = 0; } server = upList.get(index);//从活着的服务中,获取指定的服务来进行操作 } //======================================= if (server == null) { Thread.yield(); continue; } if (server.isAlive()) { return (server); } server = null; Thread.yield(); } return server; } protected int chooseRandomInt(int serverCount) { return ThreadLocalRandom.current().nextInt(serverCount); } @Override public Server choose(Object key) { return choose(getLoadBalancer(), key); } @Override public void initWithNiwsConfig(IClientConfig clientConfig) { // TODO Auto-generated method stub }}![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-guLAZcQ2-1653615477759)(SpringCloud.assets/image-20211003000657207.png)]](https://img-blog.csdnimg.cn/96f49b3b3d9e4fa9a3da84ba409a1f9f.png)
-
编写config类装配自定义的Ribbon负载均衡算法对象到spring容器中
package com.thhh.myRule;import com.netflix.loadbalancer.IRule;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;/** * 用于将自定义的ribbon负载均衡算法的实现类装配到spring容器中 */@Configurationpublic class myRule{ @Bean public IRule myRandomRule(){ return new myRandomRule();//装配自定义的负载均衡算法的实现类装配到spring容器中 }} -
在入口程序上加上注解@RibbonClient(name = “SPRINGCOULD-PROVIDER-DEPT”,configuration = myRule.class)
@EnableEurekaClient@SpringBootApplication@RibbonClient(name = "SPRINGCOULD-PROVIDER-DEPT",configuration = ZhaoRule.class)public class DeptConsumer_80 { public static void main(String[] args) { SpringApplication.run(DeptConsumer_80.class,args); }} -
测试
通过测试,确实是每一个服务被消费5次之后就切换下一个服务提供者一个的服务,15次刷新之后再次轮转3个服务提供者提供的服务,一共15张图,就不截图了,亲测有效.
十二,Feign:使用接口方式调用服务
1.Feign简介
Feign负载均衡
- Feign是声明式Web Service客户端,它让微服务之间的调用变得更简单,类似controller调用service。SpringCloud集成了Ribbon和Eureka,可以使用Feigin提供负载均衡的http客户端
- 只需要创建一个接口,然后添加注解即可使用Feign
- Feign,主要是社区版,大家都习惯面向接口编程。这个是很多开发人员的规范。调用微服务访问两种方法
- 微服务名字 【ribbon,即前面我们使用ribbon实现负载均衡的时候选中哪一个服务集群是依据注册中心的 服务名称/微服务名字进行选择的,但是我们不应该在客户端中将要调用的服务集群名称写死了,而是应该是一个变量,因为一个客户端在正常情况下不会只消费一个服务者一个的服务,它会消费多个服务者提供的不同的服务,所以将服务名称写死是满足我们使用需求的,所以就出现了Feign,通过接口解决这个问题】
- 接口和注解 【feign】
- 我们需要注意:Feign是声明式Web Service客户端,说明它和ribbon一样,都是在客户端使用的负载均衡工具,所以在使用Feign的时候,我们还是要在消费者微服务中去进行代码编写
2.Feign的作用
- Feign旨在使编写Java Http客户端变得更容易
- 前面在使用Ribbon + RestTemplate时,利用RestTemplate对Http请求的封装处理,形成了一套模板化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行封装一个客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进一步的封装,由他来帮助我们定义和实现依赖服务接口的定义,在Feign的实现下,我们只需要创建一个接口并使用注解的方式来配置它 (类似以前Dao接口上标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解即可),即可完成对服务提供方的接口绑定,简化了使用Spring Cloud Ribbon 时,自动封装服务调用客户端的开发量
- Feign默认集成了Ribbon
- 利用Ribbon维护了MicroServiceCloud-Dept的服务列表信息,并且通过轮询实现了客户端的负载均衡,而与Ribbon不同的是,通过Feign只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用
3.Feign的使用步骤
-
直接在前面我们写的微服务项目中进行改造即可
-
这里为了和使用ribbon的消费者微服务model分别开,我们新创建一个使用Feign实现负载均衡的消费者model:springcould-consumer-dept-Feign
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dKZTqmF0-1653618238883)(SpringCloud.assets/image-20211003003152846.png)]](https://img-blog.csdnimg.cn/f4b3f9396d264e89bd7c5a17d2f121c2.png)
-
然后回到最开始提供实体类dept的springcould-api模块中,到现在我们应该可以理解这个模块的作用了,它的作用就是将整个服务需要的实体类抽取了出来,抽取出来之后,我们可以在其他model中通过pom.xml将它导入,导入之后就可以实现复用,而不用每一个要使用这个实体类的model中都去定义一遍这个类
-
现在使用Feign,我们需要回到这个model中,首先导入Feign的依赖,否则不能使用Feign的注解(为了等会儿我们新创建的消费者模块也可以使用Feign,在springcould-consumer-dept-Feign的pom.xml中也导入Feign的依赖)
<!-- Feign --><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-feign</artifactId> <version>1.4.7.RELEASE</version></dependency> -
Feign实现消费者模块调用服务提供者模块的原理和原来的Dubbo+zookeeper类似,即需要使用注解实现远程注入,所以我们直接在springcould-api模块中添加一个接口DeptClientService,这个接口中的方法定义自己随意,只是方法上面要像controller一样写上@RequestMapping或者它的变体@GetMapping、@PostMapping等,但是这个接口上面不需要使用注解@Controller或@RestController
-
这个接口上面需要使用注解@FeignClient(value = “服务集群在注册中心中的名称”)和注解@Component或者它的变体@Service;其中注解@FeignClient+value属性用于指定注册中心中哪一个服务中的
@Service@Component//@FeignClient:微服务客户端注解,value:指定微服务的名字,这样就可以使Feign客户端直接找到对应的微服务@FeignClient(value = "SPRINGCOULD-PROVIDER-DEPT")public interface DeptClientService { @GetMapping("/dept/queryById/{deptno}") Dept queryById(@PathVariable("deptno") Long id); @GetMapping("/dept/queryList") List<Dept> queryAll(); @PostMapping("/dept/add") boolean addDept(Dept dept);} -
注意:还需要在这个接口上加上注解@Component/@Service,否则这个接口不会被spring托管/装配到spring容器中,那么我们在消费者model中使用这个类的时候就不能使用注解@Autowired实现对象自动注入到消费者的controller中(注意:我们是在springcould-api模块中定义的这个接口,并在这个接口上面加上了注解@Component,这个注解不是要在springcould-api模块中起作用,而是要在使用springcould-api模块的其他模块中起作用,即哪个模块导入了springcould-api模块,那么在这个model启动的时候,有注解@Component的这个接口就会被装配到spring容器中去,然后我们只需要在当前的这个模块中使用注解@Autowired就可以获取到这个接口在spring容器中的实例,就可以调用它内部的方法实现对应的功能)
-
然后去修改刚刚粘贴到springcould-consumer-dept-Feign中的的controller的代码
@Controllerpublic class DeptConsumerController { //理解:消费者,不应该有service层,因为我是直接调用提供者的服务 //RestTemplate...供我们直接调用就可以了,注册到spring中 //(url,实体:map,Class<T> responseType) @Autowired private DeptClientService service; //Ribbon.我们这里的地址应该是个变量,通过服务名来实现 //请求服务者提供的服务的url的固定前缀,就是服务者程序的主机名+端口名。它的后面还应该接上对应服务的请求url/映射的地址 private static final String REST_URL_PREFIX = "http://SPRINGCLOUD-PROVIDER-DEPT"; @RequestMapping("/consumer/dept/add") public boolean add(Dept dept){ return this.service.addDept(dept); } @RequestMapping("/consumer/dept/queryById/{deptno}") public Dept queryById(@PathVariable("deptno") long id){ return this.service.queryById(id); } @RequestMapping("/consumer/dept/queryAll") public List<Dept> queryAll(){ return this.service.queryAll(); }}![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z94ZZ2G9-1653618238884)(SpringCloud.assets/image-20211003003834497.png)]](https://img-blog.csdnimg.cn/c2a58a9d6258480e9e5c696eb1631776.png)
-
最后还要在spring boot项目的入口程序处加上启动Feign的注解@EnableFeignClients(basePackages = “我们定义的service所在的包路径”),注意:这里不是实际存在于springcould-consumer-dept-feign的model下的包路径,而是我们导入的springcould-api的包路径
package com.thhh.springcould;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.cloud.netflix.eureka.EnableEurekaClient;import org.springframework.cloud.openfeign.EnableFeignClients;@SpringBootApplication@EnableEurekaClient@EnableFeignClients(basePackages = "com.zhao.springcould")public class FeignDeptConsumer_80 { public static void main(String[] args) { SpringApplication.run(FeignDeptConsumer_80.class,args); }} -
启动Feign模块测试效果,也是轮询算法
4.小结
-
注意:通过上面使用Feign实现负载均衡我们可以发现,Feign做的事情就是在本地代码中,通过在springcould-api定义一个专门用于通过Feign实现负载均衡的接口,并在接口上写上注解@FeignClient以及这个注解的name/value属性,用于绑定注册中心中指定名称的服务,就像上面的例子中
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L1uEVHgv-1653618238884)(SpringCloud.assets/image-20211003004156185.png)]](https://img-blog.csdnimg.cn/a425111aec8e4af89ecc8179785edfbb.png)
-
绑定之后,接口中的方法和注册中心已经注册的服务中的功能提供的API通过注解@RequestMapping或其变体进行绑定
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8jQP13Ej-1653618238884)(SpringCloud.assets/image-20211003004211182.png)]](https://img-blog.csdnimg.cn/038adaa9ae0740738e056590a8129016.png)
-
然后再将springcould-api模块导入其他的模块中进行复用,在需要使用服务者功能的消费者的controller中,通过注解@Autowired实现上面定义的接口的依赖注入,并在消费者的controller中直接像controller层调用service层一样,调用这个接口中的方法,实现消费者对于服务者提供的服务的消费
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DCxP2UC0-1653618238885)(SpringCloud.assets/image-20211003004306945.png)]](https://img-blog.csdnimg.cn/f31ac792dc4746488dfe606a9b59eb85.png)
-
最后在使用这个接口的model的入口程序/主启动类上添加注解@EnableFeignClients(basePackages = “springcould-api中接口所在的包路径”)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rviBtP01-1653618238885)(SpringCloud.assets/image-20211003004323464.png)]](https://img-blog.csdnimg.cn/596ed7766eff43e0a8f17ed6c1a2532f.png)
-
所以Feign的核心就是将服务者提供的服务API进行本地化,存入消费者model中,然后再通过注解@EnableFeignClients和注解@FeignClient实现通过调用消费者模块中的本地化的服务API,调用到注册中心中真正服务提供者的API的作用(所以接口上的API映射需要和服务提供者的API保持一致)
-
只需要4步就实现了Feign实现负载均衡
5.怎么选择使用Ribbon还是Feign
- 通过对比Feign和Ribbon实现负载均衡,我可以发现,二者一个是通过接口的思想实现了消费者在客户端对于服务提供者提供的服务的消费和负载均衡,一个是按照RESTFUL风格实现了消费者在客户端对于服务提供者提供的服务的消费和负载均衡,在实际的开发中我们可以根据需要选择二者中的一个实现负载均衡;如果不需要使用负载均衡我们可以直接像前面的做法,直接在消费者端将某一个服务提供者的URL写死,通过URL+服务提供者在controller中暴露的API,实现一直只调用这一个服务提供者提供的服务
- 如果对于效率要求高一些,对于代码可读性要求低一些可以选择使用Feign,因为它在中间加了一层,所以效率会变低,但是它通过接口的思想,简化了消费者调用服务者服务的流程,使得调用流程更像controller层调用service层
- 相反可以选择Ribbon
十三,Hystrix:服务熔断
1.分布式系统面临的问题
- 复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免失败!
2.服务雪崩
-
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的“扇出”,如果扇出的链路上某个微服务的调用响应时间过长,或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”
- 比如一台服务器上的众多微服务中有一个微服务叫A,如果A崩溃了,不能提供服务了,那么所有请求这个微服务的用户就会一直等待,等待地人越来越多,那么占用的服务器的系统资源就越多[因为服务器需要维持用户的请求队列,先进先出],最终将会导致资源被占完,这个服务器就会拒绝服务,那么这个服务器上的其他服务也就访问不了了,这就是雪崩效应
-
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几十秒内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障,这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统
-
我们需要,弃车保帅
- 最简单的做法就是做服务备份,注意:服务备份大多数情况下不是指将这个服务再拷贝一份,更多的时候是指当这个服务崩溃之后,系统自动切换服务备份顶上,服务备份一般不会提供服务,而是向客户端返回一些提示信息,提示当前的这个服务崩溃了,而不是让用户等待,一直占用服务器的资源;当然备份也可以是将当前这个服务拷贝一份,当这个服务奔溃的时候切换它继续提供正常的服务,但是这样成本就增加了,因为按照这种备份,原来的服务器资源需要翻倍
3.什么是Hystrix?
- 官网资料
- Hystrix是一个应用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时,异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整个体系服务失败,避免级联故障,以提高分布式系统的弹性
- “断路器/Hystrix”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控 (类似熔断保险丝) ,向调用方返回一个服务预期的,可处理的备选响应 (FallBack) ,而不是长时间的等待或者抛出调用方法无法处理的异常,这样就可以保证了服务调用方的线程不会被长时间,不必要的占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩
4.Hystrix的作用
- 服务降级
- 服务熔断
- 服务限流
- 接近实时的监控
- …
当一切正常时,请求流可以如下所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j4D8XsqZ-1653634094907)(SpringCloud.assets/image-20211003011359505.png)]](https://img-blog.csdnimg.cn/9d4a5b38fc3f45d2ab79c04ff9f049fb.png)
即以一个消费者的请求可能需要调用好几个微服务
当许多后端系统中有一个服务崩溃的时候,这个崩溃的微服务将会阻塞整个用户的请求,就比如下图中的微服务 I:
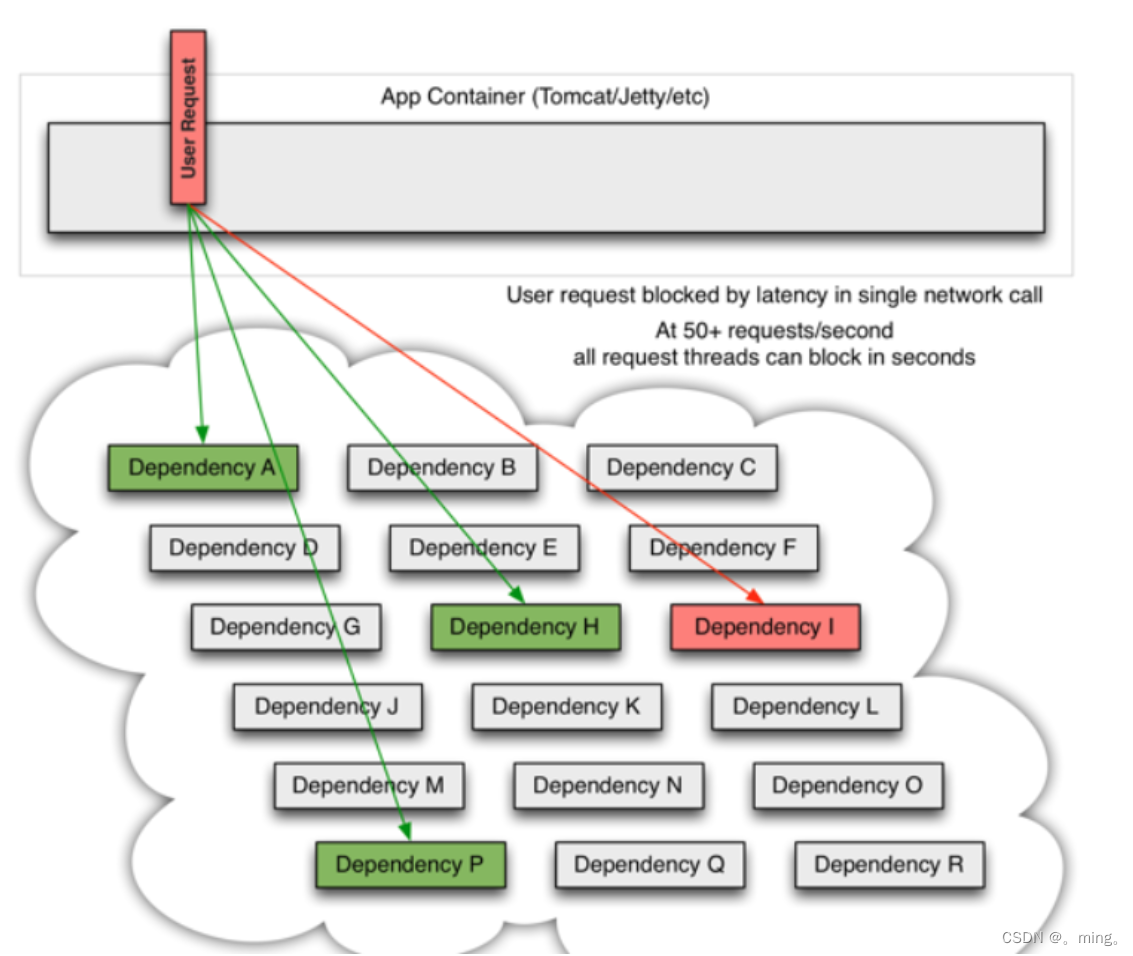
即所有需要经过微服务I的消费者的请求都会卡在微服务I这里,服务器为了维持用户先后到达的顺序就会开启队列排队并维护一些其他的必要信息,但是随着请求微服务I的用户越来越多,阻塞越来越多,服务器被消耗的资源越来越多,最终就会导致服务器资源被耗尽,就会造成服务器上其他正常的服务都不能正常的被消费者请求,即造成了服务雪崩;如下图
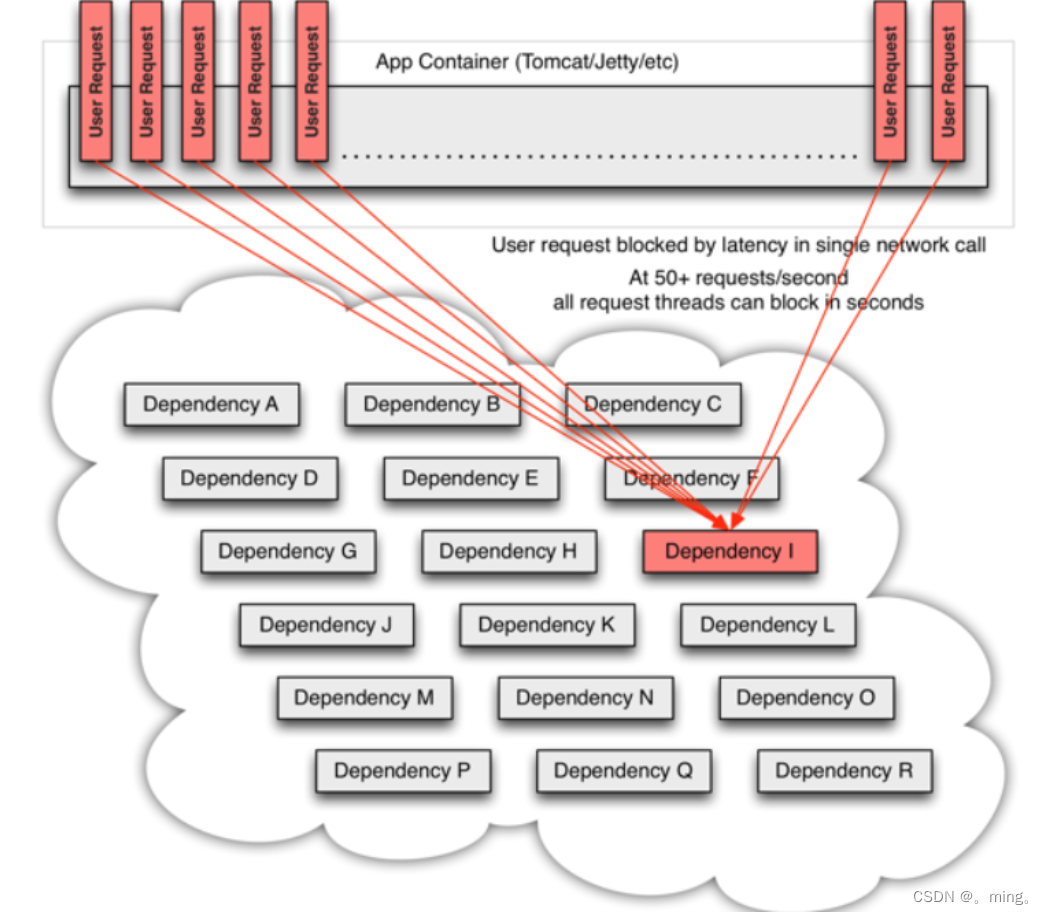
当使用hystrix包装每个基础依赖项时,上面的图表中所示的体系结构会发生类似于以下关系图的变化。即我们为每一个微服务都做一个服务备份,这个备份在微服务正常提供服务的情况下不会被调用,只有当微服务出现故障的时候才会被调用,代替原微服务继续为用户提供服务,而不是让用户一直阻塞在崩溃的微服务I这个地方,最终导致服务雪崩
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NzAsCggT-1653634094908)(SpringCloud.assets/image-20211003011507225.png)]](https://img-blog.csdnimg.cn/9478b7981adc4568a0655fdf1026dd37.png)
5.服务熔断
1.什么是服务熔断
-
熔断机制是对应服务雪崩效应的一种微服务链路保护机制,比如上面说的加一个服务的备份
-
在微服务架构中,微服务之间的数据交互通过远程调用完成,微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,此时如果链路上某个微服务的调用响应时间过长或者不可用,那么对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,导致“雪崩效应”
-
服务熔断是应对雪崩效应的一种微服务链路保护机制。例如在高压电路中,如果某个地方的电压过高,熔断器就会熔断,对电路进行保护。同样,在微服务架构中,熔断机制也是起着类似的作用。当调用链路的某个微服务不可用或者响应时间太长时,会进行服务熔断,不占用该节点微服务的调用,快速返回错误的响应信息;当检测到该节点微服务调用响应正常后,恢复调用链路。
-
当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息,检测到该节点微服务调用响应正常后恢复调用链路。在SpringCloud框架里熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定阀值缺省是5秒内20次调用失败,就会启动熔断机制,我们在spring cloud中只需要使用一个熔断机制的注解是:@HystrixCommand 即可
-
服务熔断解决如下问题:
- 当所依赖的对象不稳定时,能够起到快速失败的目的
- 快速失败后,能够根据一定的算法动态试探所依赖对象是否恢复
2.入门案例
-
创建一个新的model,但是它是在原来的8001服务提供者模块的基础上进行的修改,即在原来没有加上熔断机制的8001上加上熔断机制,而SpringCloud框架里熔断机制通过Hystrix实现,所以我们需要导入Hystrix的依赖
-
实现还是老4步
- 导入依赖- 编写配置文件- 开启这个功能:@EnableXXX- 配置类 -
创建子model:springcould-provider-dept-hystrix-8001
-
拷贝8001里的所有东西
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lUewMPDg-1653634094909)(SpringCloud.assets/image-20211003011741036.png)]](https://img-blog.csdnimg.cn/ae551c33186f4137b86982684758d11e.png)
-
导入Hystrix的依赖
<!--Hystrix依赖--><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix</artifactId> <!--可见ribbon、Feign、Hystrix的依赖套路就是只修改最后的后缀即可--> <version>1.4.7.RELEASE</version></dependency> -
修改配置文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bUv9zOkY-1653634094909)(SpringCloud.assets/image-20211003011811438.png)]](https://img-blog.csdnimg.cn/ee6bb88722aa43f1969dff32770e8330.png)
-
修改原来的controller,比如这里我们用按照id查询部门信息的方法举例子,我们让这个方法出错的时候就去调用我们备用的方法给前端返回信息(这就是使用hystrix实现的熔断机制,当原方法崩溃/报错不能正常提供服务的时候,直接切换备用的方法继续为客户端提供服务,而不是向客户端返回报错信息)
-
直接在方法queryDeptById()上加上注解@HystrixCommand,这个注解需要传递一个参数fallbackMethod,即失败的时候调用的方法的名称
@HystrixCommand(fallbackMethod = "hystrixQueryDeptById")@GetMapping("/dept/queryById/{deptno}")public Dept queryDeptById(@PathVariable("deptno") long id){//原来服务者提供的按照id查询部门信息的方法,不做任何修改,只是加上注解@HystrixCommand//和一个判断获取到的dept对象是否为null,如果为null直接手动抛出异常 Dept dept = deptService.queryDeptById(id); if (dept==null){ //注意:这个异常抛出必须有,否则hystrix不能发现这个方法执行的时候出现了异常 throw new RuntimeException("这个id====>"+id+"对应的部门不存在,或信息无法找到~"); } return dept;}public Dept hystrixQueryDeptById(@PathVariable("deptno") long id){//这个方法就是hystrix用于在上面提供的按照id查询部门信息的方法崩溃/报错的时候替换它继续提供服务的方法 return new Dept() .setDeptno(id) .setDname("抱歉,未查询到您指定的id对应的部门信息") .setDb_source("MySQL数据库中没有匹配的数据库存有查询的信息");} -
注意:我们定义的hystrix用于在原来服务者提供的按照id查询部门信息的方法崩溃/报错的时候替换它继续提供服务的方法的定义除了方法名称,其他的应该和原方法保持一致,这是为了返回的数据仍是原来的数据类型;上面熔断处理方法返回的是一个我们临时new出来的Dept对象,这个对象的属性都是我们设置的提示信息,用于正常的结束本次消费者对于服务的请求并返回给消费者提示信息
-
注意:上面我们直接返回一个消费者期望的Dept对象,或者说是原服务相同的数据类型的数据,比我们直接抛出异常然后再捕获异常再返回给消费者来的好
-
注意:异常抛出必须有,否则hystrix不能发现这个方法执行的时候出现了异常
-
去这个model的入口程序/主启动类上加上注解@EnableXXX
package com.thhh.springcould;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;import org.springframework.cloud.netflix.eureka.EnableEurekaClient;@SpringBootApplication@EnableEurekaClient //标识这是一个eureka注册中心提供服务的客户端,加上配置文件中配置的注册中心的url,服务就会被自动注册到eureka注册中心中去@EnableCircuitBreaker//开启熔断器,即添加对熔断的支持public class HystrixDeptProvider_8001 { public static void main(String[] args) { SpringApplication.run(HystrixDeptProvider_8001.class,args); }} -
测试效果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LV9ulbhI-1653634094909)(SpringCloud.assets/image-20211003012004037.png)]](https://img-blog.csdnimg.cn/8fd8d19660994d508eeb0c871fea2208.png)
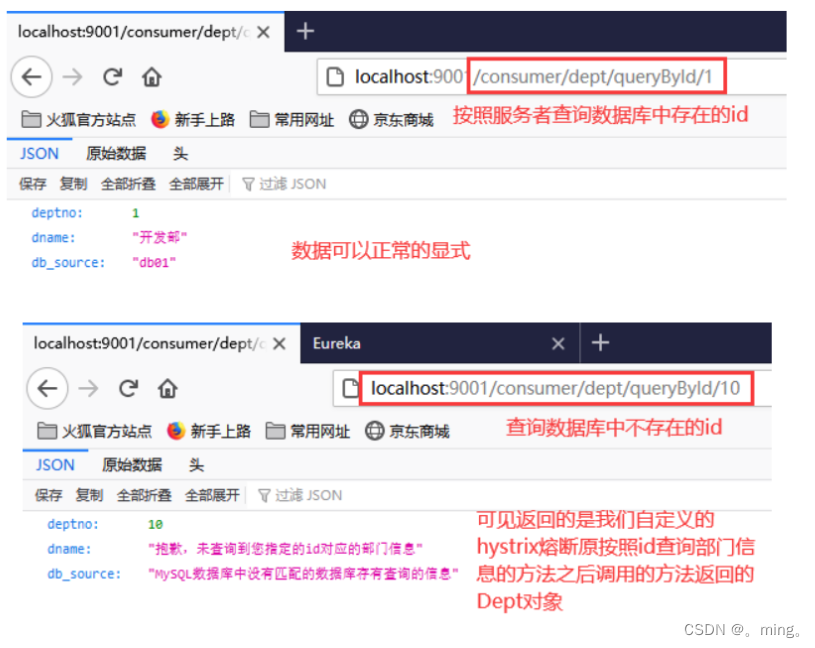
使用Hystrix实现熔断机制虽然效果很好,但是加大了增加开发的代码量,因为服务者每新增要给向外体提供服务的方法,我们就需要对应这个方法的熔断机制的备份,或许可以出现多个方法使用一个备份,但是大多数情况下,我们还是要争对不同的情况返回不同的提示消息,代码量增多。
3.显式提供服务的服务器的IP
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D0PIyB90-1653634094909)(SpringCloud.assets/image-20211003012049862.png)]](https://img-blog.csdnimg.cn/ca47b8ce386346c2b7dd161edcbc805c.png)
4.小结
- Hystrix使用步骤
- 编写hystrix熔断之后的备用方法
- 使用注解@HystrixCommand指定熔断之后调用的方法的名称
- 使用注解@EnableCircuitBreaker开启model的熔断器
- Hystrix对于用户体验更好,但是代码量增加
- 可以修改监控页面上对应的服务的Status字段下面超链接显示的地址为IP,而不是localhostXXX
十四,Hystrix:服务降级
1.什么是服务降级
-
服务降级是指当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心业务正常运作或高效运作。说白了,就是尽可能的把系统资源让给优先级高的服务
-
资源有限,而请求是无限的。如果在并发高峰期,不做服务降级处理,一方面肯定会影响整体服务的性能,严重的话可能会导致宕机某些重要的服务不可用。所以,一般在高峰期,为了保证核心功能服务的可用性,都要对某些服务降级处理。比如当双11活动时,把交易无关的服务统统降级,如查看蚂蚁深林,查看历史订单等等
-
服务降级主要用于什么场景呢?当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,可以将一些 不重要 或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用
-
降级的方式可以根据业务来,可以延迟服务,比如延迟给用户增加积分,只是放到一个缓存中,等服务平稳之后再执行 ;或者在粒度范围内关闭服务,比如关闭相关文章的推荐
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v1wF8En5-1653635263619)(SpringCloud.assets/image-20211003013337467.png)]](https://img-blog.csdnimg.cn/e8b6ef9da54a4dc2ad3ba9277124493c.png)
-
由上图可得,当某一时间内服务A的访问量暴增,而B和C的访问量较少,为了缓解A服务的压力,这时候需要B和C暂时关闭一些服务功能,去承担A的部分服务,从而为A分担压力,这就叫做服务降级
-
服务降级需要考虑的问题
- 那些服务是核心服务,哪些服务是非核心服务
- 那些服务可以支持降级,那些服务不能支持降级,降级策略是什么
- 除服务降级之外是否存在更复杂的业务放通场景,策略是什么?
-
自动降级分类
- 超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况
- 失败次数降级:主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
- 故障降级:比如要调用的远程服务挂掉了(网络故障、DNS故障、http服务返回错误的状态码、rpc服务抛出异常),则可以直接降级。降级后的处理方案有:默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)
- 限流降级:秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)
2.入门案例
-
上一章中实现的服务熔断是消费者向服务提供者暴露的API发送请求的时候,服务崩溃的时候的容错机制,注意:服务熔断是发生在服务崩溃/报错的时候,所以服务熔断应该在服务提供者提供的服务中实现
-
而服务降级是在某一时刻系统为了维持核心功能的稳定运行而暂时停止对于非核心功能的提供的容错机制;但是它是在服务提供者模块中实现还是消费者模块中实现呢?
-
注意:如果我们在服务提供者上面实现,就意味着我们需要直接将整个服务关闭,在合适的时候再将它开启,那么在此期间所有消费者都将不能访问被服务降级的服务,并且我们关闭服务的办法很暴力,就是直接关闭服务器,但是服务降级的本意是要运行非核心功能的服务器在服务降级之后分担核心功能服务器的压力,向外提供核心功能服务,所以在服务提供者上面实现是不满足需求的
-
那么我们就应该在消费者方面实现,即如果一个服务出现了服务降级,那么消费者模块就会再用户请求这个服务的时候直接在客户端返回我们已经准备好的服务降级信息,即根本就不会让客户端发送请求到服务器占用服务器的资源,而是直接在消费者model中就拦截请求并返回服务降级提示信息,这样做减轻了出现服务降级的时候服务器的压力/资源消耗
-
实现步骤也很简单,只需要在springcould-api中的service同级目录下创建一个实现FallbackFactory接口的实现类DeptClientServiceFallbackFactory即可
-
我们还是拿根据ID查询部门信息为例
在实现服务熔断的时候为了指定某一个方法熔断之后顶替它的方法,我们使用了注解@HystrixCommand,并传入了参数fallbackMethod指定顶替方法名称package com.zhao.springcloud.service;/** * ************************************************************************ * 项目名称: springcloud <br/> * 文件名称: <br/> * 文件描述: 这里添加您的类文件描述,说明当前文件要包含的功能。 <br/> * 文件创建:赵先生 <br/> * 创建时间: 2021/10/3 <br/> * 山西优逸客科技有限公司 Copyright (c) All Rights Reserved. <br/> * * @version v1.0 <br/> * @update [序号][日期YYYY-MM-DD][更改人姓名][变更描述]<br/> * ************************************************************************ */import com.zhao.springcloud.pojo.Dept;import feign.hystrix.FallbackFactory;import java.util.List;/** * @ProjectName: springcloud * @ClassName: DeptClientServiceFallbackFactory * @Description: 请描述该类的功能 * @Author: 赵先生 * @Date: 2021/10/3 1:24 * @version v1.0 * Copyright (c) All Rights Reserved,山西优逸客科技有限公司,. *///实现接口中的服务降级public class DeptClientServiceFallbackFactory implements FallbackFactory { @Override public DeptClientService create(Throwable throwable) { final DeptClientService 没有对应的数据库 = new DeptClientService() { @Override public Dept queryById(Long id) { return new Dept() .setDeptno(id) .setDname("没有找到" + id + "对应的数据,当前该服务已经出现了服务降级,该服务已经关闭,请等待服务重启之后再试") .setDb_source("没有对应的数据库"); } @Override public List<Dept> queryAll() { return null; } @Override public boolean addDept(Dept dept) { return false; } }; return 没有对应的数据库; }} -
在实现服务熔断的时候为了指定某一个方法熔断之后顶替它的方法,我们使用了注解@HystrixCommand,并传入了参数fallbackMethod指定顶替方法名称
-
实现服务降级的时候我们需要配合前面学习使用的Feign的注解@FeignClient和它的参数fallbackFactory,这个参数用于传入FallbackFactory接口的实现类,所以我们可以对学习Feign的时候创建的service接口上的注解@FeignClient进行改造,其实就是在它的注解中多传入一个参数fallbackFactory
@Service@Component//@FeignClient:微服务客户端注解,value:指定微服务的名字,这样就可以使Feign客户端直接找到对应的微服务@FeignClient(value = "SPRINGCOULD-PROVIDER-DEPT",fallbackFactory = DeptClientServiceFallbackFactory.class)public interface DeptClientService { @GetMapping("/dept/queryById/{deptno}") Dept queryById(@PathVariable("deptno") Long id); @GetMapping("/dept/queryList") List<Dept> queryAll(); @PostMapping("/dept/add") boolean addDept(Dept dept);}![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lEjKVYCp-1653635263620)(SpringCloud.assets/image-20211003013925160.png)]](https://img-blog.csdnimg.cn/1a4de6e1da224fadbd851a90377e2206.png)
-
去使用Feign作为负载均衡的消费者的model中的配置文件中开启Hystrix的降级服务
server: port: 9001#eureka配置eureka: client: register-with-eureka: false #表示不向eureka中注册自己,即表明自己是一个消费者 service-url: defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ #配置可以连接的eureka注册中心的urlfeign: hystrix: enabled: true#只需要设置该属性就可以开启该消费者model的hystrix服务降级 -
开启对应的model进行测试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CdsyAwCE-1653635263620)(SpringCloud.assets/image-20211003014017852.png)]](https://img-blog.csdnimg.cn/79464c50d65d40e3b68cc2deb7018b83.png)
-
此时我们公司的服务遇到了洪流,需要将提供上面这个功能的服务器关闭对外的服务,转而去为遇到洪流的服务器分担压力,对于正常访问这个服务的消费者而言这台服务器就和关闭了没有什么区别,所以我们可以去IDEA中关闭该服务提供者
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZJVUaOyy-1653635263621)(SpringCloud.assets/image-20211003014041267.png)]](https://img-blog.csdnimg.cn/6d035a9509d14907ba8428d69886ed79.png)
-
再次访问该服务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vSFkeNV4-1653635263621)(SpringCloud.assets/image-20211003014059747.png)]](https://img-blog.csdnimg.cn/61fdaa3012444dc88a60f2360f208c8f.png)
-
可见即使我们关闭了提供这个服务的服务器,消费者模块再次访问该服务API的时候,返回到前端的数据是一开始我们设置好的服务降级处理反馈的数据
3.小结
-
通过上面的案例我们大致可以明白服务降级的作用,以及它的实现
-
上面的例子在实现服务降级的时候只是在公用的数据model springcould-api中实现了接口FallbackFactory,实现的方法create()返回的数据类型为DeptClientService,即前面我们为了实现Feign定义的一个接口对象,但是接口不能直接new,所以我们就在方法create()中实现了接口DeptClientService,为每一个方法定义了服务降级之后再被访问的时候返回的数据
@Componentpublic class DeptClientServiceFallbackFactory implements FallbackFactory { //实现服务降级的类需要实现接口FallbackFactory,即失败回调工厂 @Override public DeptClientService create(Throwable throwable) { return new DeptClientService() { @Override public Dept queryById(Long id) { return new Dept() .setDeptno(id) .setDname("没有找到"+id+"对应的数据,当前该服务已经出现了服务降级,该服务已经关闭,请等待服务重启之后再试") .setDb_source("没有对应的数据库"); } @Override public List<Dept> queryAll() { return null; } @Override public boolean addDept(Dept dept) { return false; } }; }}![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PPmRuN0e-1653635263621)(SpringCloud.assets/image-20211003014422245.png)]](https://img-blog.csdnimg.cn/b3a03d269c9d421c88e93f8b0e05b0cf.png)
-
然后我们就需要去需要去对应的这个接口的注解@FeignClient中传入参数fallbackFactory,值就是上面我们实现接口FallbackFactory的类的class对象
@Service@Component//@FeignClient:微服务客户端注解,value:指定微服务的名字,这样就可以使Feign客户端直接找到对应的微服务@FeignClient(value = "SPRINGCOULD-PROVIDER-DEPT",fallbackFactory = DeptClientServiceFallbackFactory.class)public interface DeptClientService { @GetMapping("/dept/queryById/{id}") Dept queryById(@PathVariable("id") Long id); @GetMapping("/dept/queryList") List<Dept> queryAll(); @PostMapping("/dept/add") boolean addDept(Dept dept);} -
最后就是去使用了Feign作为负载均衡的消费者模块中的配置文件开启hystrix的服务降级功能
server: port: 9001#eureka配置eureka: client: register-with-eureka: false #表示不向eureka中注册自己,即表明自己是一个消费者 service-url: defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ #配置可以连接的eureka注册中心的urlfeign: hystrix: enabled: true![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rvs0lXHF-1653635263621)(SpringCloud.assets/image-20211003014526543.png)]](https://img-blog.csdnimg.cn/5fb2b1a135274a83a2c4fb6df8951114.png)
-
在测试的流程中,在正常的情况下(开启了服务降级的消费者模块对应消费的服务提供者模块正常运行的情况下),消费者可以正常的通过Feign的接口方式对于服务进行消费,但是一旦提供该服务的服务器不再对外提供服务的时候,即我们在IDEA中关闭了这个微服务的时候,再次请求该微服务中提供的任何服务功能,返回的都是一开始在接口FallbackFactory中定义好的提示信息
-
注意:整个实现流程中,我们并没有修改服务提供者的任何代码,只是在公共数据模块springcould-api中添加了一个实现接口FallbackFactory的类,在Feign接口的注解@FeignClient上添加了一个传入的参数,在使用Feign的消费者模块中开启了Hystrix的服务降级功能,然后就开启的服务进行了测试
4.对比服务熔断和服务降级
-
服务熔断是发生在消费者已经向服务提供者提供的服务的API发送了请求数据,并在一连串的微服务调用中出现了某一个服务崩溃的时候,它防止了大量用户访问该崩溃服务造成的服务雪崩
-
服务降级是发生在服务提供者为了满足核心功能的正常供应,将非核心功能提供的服务暂时关闭,而消费者此时又对非核心服务进行访问的时候,它防止因为当前非核心业务服务被停止供应而出现客户端异常的情况,并且在消费者模块中就对消费者对于服务的请求进行拦截,并返回定义好的服务降级的提示信息
- 触发的条件就是我们使用的Feign不能关联到注册中心中指定的服务名称的服务,从而就会去调用fallbackFactory指定的失败回调工厂返回的DeptClientService对象中对应的方法返回服务降级提示信息
- 即保证了服务器关闭之后服务将不再被调用,消费者还是可以正常的发送对应服务的请求,只是这个请求不会到达服务器,在消费者模块中自己的就进行了处理,并返回服务降级信息
- 对于服务降级,它返回的是一个缺省值,整个系统提供的服务水平下降了,但是整个系统的核心业务还能正常提供,非核心业务也能正常的返回提示信息,比服务直接挂掉要强
-
服务熔断是针对每一个方法进行的容灾手段;而服务降级是针对某一个Feign的服务接口的容灾手段,对比之下可见服务降级是对一系列服务API的容灾手段(就是一个服务者提供的所有服务API)
服务熔断:服务端~某个服务超时或者异常,引起熔断~,作用和保险丝类似~服务降级:客户端~从整体网站请求负载考虑~,当某个服务熔断或者关闭之后,服务将不再被调用~此时在客户端,我们可以准备一个FallbackFactory,返回一个默认的值(缺省值),整体的服务水平下降了~但是,好歹能用,比直接挂摊强
十五,Hystrix:Dashboard流监控
1.什么是Hystrix Dashboard
- Hystrix提供了对于微服务调用状态的监控信息,但是需要结合spring-boot-actuator模块一起使用
- Hystrix-dashboard是一款针对Hystrix进行实时监控的工具,通过Hystrix Dashboard我们可以在直观地看到各Hystrix Command实时的请求响应时间, 请求成功率等数据,可以帮助我们快速发现系统中存在的问题
- 注意:从Hystrix Dashboard的定义我们可以看出,它是专门用来监控使用了Hystrix的注解@Hystrix Command的方法的实时情况的,那么我们使用Hystrix Dashboard进行服务者某些服务的实时监控的前提为我们监控的这个服务者向外提供的API使用了Hystrix的服务熔断机制,即方法上面使用了注解@Hystrix Command,并且定义了一个备份的替代方法,那么这个方法被消费者微服务请求的情况我们才能够通过Hystrix Dashboard看到其实时的情况
2.Hystrix Dashboard入门案例
-
既然是监控服务提供者提供的服务,我们可以将这个功能单独的分离为一个微服务,哪一个使用了熔断服务的服务提供者模块需要进行Hystrix的监控了,我们就直接在这个服务提供者的入口程序中添加一个注册HystrixMetricsStreamServlet这个servlet的@Bean方法,这样这个服务提供者中使用了注解@Hystrix Command的方法的使用情况就能够被Hystrix Dashboard监控统计了
-
创建一个新的子model:springcould-provider-hystrix-dashboard-10000
-
导入使用Hystrix Dashboard需要的依赖
<dependencies> <!--Hystrix:Dashboard依赖--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix-dashboard</artifactId> <version>1.4.7.RELEASE</version> </dependency> <!--eureka完善对应服务的监控信息依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency></dependencies>- 注意:我们只导入了Hystrix Dashboard使用必要的两个依赖,其他的依赖都可以不要
-
首先在配置文件application中配置服务端口,这里我们设置为10000,然后再添加一个Hystrix Dashboard的配置
server: port: 10000hystrix: dashboard: proxy-stream-allow-list: "*" -
需要注意的是在Spring Cloud Finchley 版本以前访问路径是/hystrix.stream,如果是Finchley的话就需要加入上面的配置。因为spring Boot 2.0.x以后的actuator只暴露了info和health2个端点,这里我们把所有端点开放,include: '*'代表开放所有端点
-
编写入口程序,注意使用注解@EnableHystrixDashboard开启监控页面
@SpringBootApplication@EnableHystrixDashboard //开启监控页面public class DeptProviderDashboard_10000 { public static void main(String[] args) { SpringApplication.run(DeptProviderDashboard_10000.class,args); }} -
然后我们就可以去浏览器中输入
http://localhost:10000/hystrix(注意:10000是这个Hystrix Dashboard微服务运行的端口号,可以根据自己的设置修改),就可以获取到一个页面,这就是Dashboard的监控首页![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7HIzbsHX-1653636297251)(SpringCloud.assets/image-20211003135608520.png)]](https://img-blog.csdnimg.cn/07a06a3b210247ea80cee178d49f347a.png)
-
从首页中我们可以看出并没有具体的监控信息,从页面上的文件内容我们可以知道,Hystrix Dashboard共支持三种不同的监控方式:
- 默认的集群监控:
http://turbine-hostname:port/turbine.stream - 指定的集群监控:
http://turbine-hostname:port/turbine.stream?cluster=[clusterName] - 单体应用的监控:
http://hystrix-app:port/actuator/hystrix.stream
- 默认的集群监控:
-
页面上面的几个参数局域
- 最上面的输入框: 输入上面所说的三种监控方式的地址,用于访问具体的监控信息页面
- Delay: 该参数用来控制服务器上轮询监控信息的延迟时间,默认2000毫秒
- Title: 该参数对应头部标题Hystrix Stream之后的内容,默认会使用具体监控实例的Url
-
我们先来看下单个服务实例的监控,从http://hystrix-app:port/actuator/hystrix.stream连接中可以看出,Hystrix Dashboard监控单节点实例需要访问实例的actuator/hystrix.stream接口,我们自然就需要为服务实例添加这个端点
-
实现方法就是在直接在服务提供者的入口程序中添加一个注册HystrixMetricsStreamServlet这个servlet的@Bean方法,注意使用前提:这个服务提供者已经使用了Hystrix的服务熔断注解@HystrixCommand,否则HystrixDashboard不能使用/不能获取到监控的数据;
-
这里我们就使用前面学习服务熔断的时候创建的服务者model:springcould-provider-dept-hystrix-8001,所以我们需要在这个服务提供者的主启动类中添加一个注册servlet的@Bean方法
package com.zhao.springcloud;/** * ************************************************************************ * 项目名称: springcloud <br/> * 文件名称: <br/> * 文件描述: 这里添加您的类文件描述,说明当前文件要包含的功能。 <br/> * 文件创建:赵先生 <br/> * 创建时间: 2021/10/1 <br/> * 山西优逸客科技有限公司 Copyright (c) All Rights Reserved. <br/> * * @version v1.0 <br/> * @update [序号][日期YYYY-MM-DD][更改人姓名][变更描述]<br/> * ************************************************************************ */import com.netflix.hystrix.contrib.metrics.eventstream.HystrixMetricsStreamServlet;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.boot.web.servlet.ServletRegistrationBean;import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;import org.springframework.cloud.netflix.eureka.EnableEurekaClient;import org.springframework.context.annotation.Bean;/** * @ProjectName: springcloud * @ClassName: DeptProvider_8001 * @Description: 请描述该类的功能 * @Author: 赵先生 * @Date: 2021/10/1 18:10 * @version v1.0 * Copyright (c) All Rights Reserved,山西优逸客科技有限公司,. */@SpringBootApplication@EnableEurekaClient //标识这是一个eureka注册中心提供服务的客户端,加上配置文件中配置的注册中心的url,服务就会被自动注册到eureka注册中心中去@EnableCircuitBreaker//开启熔断器,即添加对熔断的支持public class HystrixDeptProvider_8001 { public static void main(String[] args) { SpringApplication.run(HystrixDeptProvider_8001.class,args); } @Bean public ServletRegistrationBean hystrixServletRegistrationBean(){ //在spring boot中向servlet容器中注册新的servlet并设置这个servlet的请求url ServletRegistrationBean bean = new ServletRegistrationBean(new HystrixMetricsStreamServlet()); //将新的servlet注入servlet容器中 bean.addUrlMappings("/actuator/hystrix.stream"); //设置该servlet的请求路径 return bean; }} -
注意:该servlet的请求URL映射需要为HystrixDashboard页面上单个服务实例的监控需要访问的实例的actuator/hystrix.stream接口保持一致,否则我们就不能查看当前这个服务提供者的监控信息,因为我们我们在url输入框中输入的单体应用的监控的URL对应的节点并不存在
-
测试,按照注册中心、服务提供者、服务消费者、HystrixDashboard的顺序启动各个子model,然后首先访问注册中心、服务消费者,保证此时服务可以正常的使用,在此前提下我们再谈监控服务提供者的事情
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wPDFN9UQ-1653636297251)(SpringCloud.assets/image-20211003140024451.png)]](https://img-blog.csdnimg.cn/20abee147c874e518e89ac80b720328a.png)
-
通过上面的例子我们实现了通过HystrixDashboard实现对于服务提供者中使用了Hystrix熔断服务的 方法/API 被消费者进行消费的实时监控
-
特别注意:HystrixDashboard监控的是使用了Hystrix熔断服务服务提供者的 方法/API被消费者实时消费的情况,不是随便一个服务提供者中controller中的方法都可以进行监控
3.小结
-
HystrixDashboard监控是针对性的监控,不是说监控谁就监控谁,它是专门用于监控使用了Hystrix熔断服务服务提供者的 方法/API被消费者实时消费的情况
-
HystrixDashboard用于监控的是服务提供者,不是服务消费者
-
HystrixDashboard因为需要在页面上实时查看监控数据,所以它本身需要独立成一个微服务,占用一个端口向外提供查看监控数据的服务
-
在需要使用HystrixDashboard的服务提供者中,我们不需要导入我们实现的HystrixDashboard微服务,我们只需要在这个model的入口程序中加入一个注册HystrixMetricsStreamServlet这个servlet的@Bean方法并配置其url-pattern即可,注意url-pattern需要为Hystrix Dashboard支持的三种不同的监控方式的url
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C660zcNX-1653636297252)(SpringCloud.assets/image-20211003140252625.png)]](https://img-blog.csdnimg.cn/20554c7f19f64769a96de703af07959a.png)
4.监控图怎么看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E43p349k-1653636297252)(SpringCloud.assets/image-20211003140444207.png)]](https://img-blog.csdnimg.cn/8be06eee55184c419ab8a1d1ae64d193.png)
-
一个圈
-
实心圆:它代表了两种含义,它通过颜色的变化代表了实例的健康程度,通过大小变化代表了实例的流量变化
-
它的健康程度从绿色<黄色<橙色<红色 递减
-
该实心圆除了颜色的变化之外,它的大小也会根据实例的请求流量发生变化,流量越大,该实心圆就越大,所以通过该实心圆的展示,就可以在大量的实例中快速发现故障实例和高压力实例
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sa1cf0P4-1653636297252)(SpringCloud.assets/image-20211003140537625.png)]](https://img-blog.csdnimg.cn/aa347ab4048e413f8c1aee54f6b02682.png)
-
-
一线
-
曲线:用来记录2分钟内流量的相对变化,可以通过它来观察到流量的上升和下降趋势
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5kmhYOJO-1653636297252)(SpringCloud.assets/image-20211003140555339.png)]](https://img-blog.csdnimg.cn/44161ae7c4a24375a31381d5cfe09a3e.png)
-
-
七色
- 绿色:成功数
- 蓝色:熔断数
- 浅绿色:错误请求数
- 黄色:超时数
- 紫色:线程池拒绝数
- 红色:失败/异常数
- Hosts:服务请求频率
- Circuit Closed:断路状态
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m6FxwBBP-1653636297253)(SpringCloud.assets/image-20211003140642129.png)]](https://img-blog.csdnimg.cn/721b92e109c34f628b98dc987583ef93.png)
十六,Zuul:路由网关
1.什么是zuul
-
Zull包含了对请求的路由(用来跳转的)和过滤两个最主要功能
-
其中路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础,而过滤器功能则负责对请求的处理过程进行干预,是实现请求校验,服务聚合等功能的基础
-
Zuul和Eureka进行整合,将Zuul自身注册为Eureka服务治理下的应用,同时从Eureka中获得其他服务的消息,也即以后的访问微服务都是通过Zuul跳转后获得
-
注意:Zuul服务最终还是会注册进Eureka
-
提供:代理+路由+过滤 三大功能!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qATqPNWi-1653636297253)(SpringCloud.assets/image-20211003142721650.png)]](https://img-blog.csdnimg.cn/060748aeb91e47d29102d75ab2b09b2f.png)
2.zuul的功能
- 路由
- 过滤
- 官方文档
3.入门案例
-
创建一个新的子model:springcould-zuul-9002
-
导入依赖,从上面关于zuul的讲述中我们知道,我们创建用于实现zuul的微服务要和其他的服务提供者提供的服务一样,将zuul模块的提供的路由服务作为注册中心的一个注册服务,所以我们需要eureka的依赖,要使用zuul自然需要zuul的依赖
<dependencies> <!--zuul依赖--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zuul</artifactId> <version>1.4.7.RELEASE</version> </dependency> <!--eureka的服务提供者的依赖--> <!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-eureka --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactId> <version>1.4.7.RELEASE</version> </dependency></dependencies> -
编写配置文件,将这个微服务作为一个服务提供者提供的程序注册到注册中心去,所以它的配置应该和前面服务提供者model的配置类似
#服务运行端口server: port: 9002#这个微服务在注册中心中注册的时候使用的服务名称spring: application: name: springcould-zuul-getway#设置这个服务要注册到哪些注册中心中去eureka: client: service-url: defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ #设置这个注册到注册中心去的服务的描述信息显示的数据 instance: instance-id: springcould-zuul-9002 #配置注册的服务的描述信息 prefer-ip-address: true #将描述信息对应的超链接设置为IP格式,而不是主机名称格式#完善监控信息展示info: app.name: zuul-getway路由网关 #服务的名称 company.name: com.ming -
为了方便使用,我们再去HOSTS文件中增加一个本地计算机地址的映射名称
127.0.0.1 www.zhao.com
-
编写主启动类/入口程序
package com.thhh.springcloud;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.cloud.netflix.eureka.EnableEurekaClient;import org.springframework.cloud.netflix.zuul.EnableZuulProxy;@SpringBootApplication@EnableZuulProxy //开启zuul服务代理,这个注解的作用和普通注册到eureka注册中心服务需要写的注解@EnableEurekaClient的作用类似 //可以开启eureka服务注册发现,否则这个model提供的服务不能被eureka注册中心扫描到public class ZuulApplication { public static void main(String[] args) { SpringApplication.run(ZuulApplication.class,args); }} -
测试,按照顺序启动注册中心、服务提供者、zuul模块
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lPSjWklj-1653636297253)(SpringCloud.assets/image-20211003143245668.png)]](https://img-blog.csdnimg.cn/75e4d8d702c043b9b11e91eed6ab5a22.png)
-
注意:通过上面的例子·我们就可以发现,只需要创建一个子model,导入zuul和eureka的依赖,编写配置文件application.yml,编写主启动类/入口程序并加上注解@EnableZuulProxy
-
启动注册中心、服务提供者、zuul模块,我们就可以通过zuul模块的IP+端口号+注册中心中已经注册的服务名称小写+这个服务提供者对于某一个服务暴露的API就可以实现对于这个服务提供者提供的某一个服务的调用
-
即通过向注册中心中注册一个zuul模块服务,我们就可以直接使用这个微服务模块的功能去调用其他服务提供者提供的服务,而不需要去其他服务提供者中进行任何的修改
-
这样做的好处:我们可以将服务提供者提供的服务的真实IP+端口号+服务API进行隐藏,这样可以提高系统的安全
4.使用zuul隐藏真正提供服务的服务提供者注册的服务的名称
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xAwkOirU-1653636297253)(SpringCloud.assets/image-20211003143405235.png)]](https://img-blog.csdnimg.cn/57051471fa1e40218f80813b35f6b360.png)
-
实现微服务名称的隐藏/映射的方式就是去配置文件中进行配置
zuul: routes: mydept.serviceId: springcould-provider-dept #微服务名称,key mydept.path: /mydept/** #代替这个微服务名称的path变量,即只要是"主机名称:端口号/mydept/"下面的所有请求,都去注册中心的服务springcould-provider-dept中处理 -
测试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-unUxRrp2-1653636297254)(SpringCloud.assets/image-20211003143452279.png)]](https://img-blog.csdnimg.cn/833666f497ed45f0bc37956a146e353f.png)
-
这个时候我们通过zuul模块实现消费者对于服务提供者提供的服务进行消费,并且URL中没有出现这个服务提供者在注册中心中注册的服务的名称,这进一步提高了安全性
-
但是有一点,就是将path变量换回原来的服务名称也还是能够实现消费服务,这显然不是我们需要的,我们真实的需求应该是我在zuul中为这个服务的访问定义了path值之后,原来使用服务名称消费服务的方式就应该失效,否则设置path变量的意义/安全性将会大大降低
-
实现方式,还是在配置文件中进行zuul的配置
zuul: routes: mydept.serviceId: springcould-provider-dept #微服务名称,key mydept.path: /mydept/** #代替这个微服务名称的path变量,即只要是"主机名称:端口号/mydept/"下面的所有请求,都去注册中心的服务springcould-provider-dept中处理,value ignored-services: springcould-provider-dept #设置不能再在zuul中使用这个微服务在注册中心中注册的服务名称对这个微服务进行消费 -
通过将原来服务名称消费服务失效,就真正意义上实现了隐藏注册中心服务名称的目的,这才是提高安全的做法,将我们真实项目中的东西都隐藏起来了
-
是在真实的开发中,我们不可能只隐藏上面例子中那样的一个微服务,而是应该将所有提高消费的微服务的名称全部隐藏起来,但是我们又不能写一个微服务就去配置文件中为它写上ignored-services配置,所以我们可以使用通配符
ignored-services: "*" #隐藏所有的可消费的服务的名称 -
除此之外我们还可以为每一个zuul模块设置不同的前缀,同样是使用配置文件设置zuul的属性
zuul: routes: mydept.serviceId: springcould-provider-dept #微服务名称,key mydept.path: /mydept/** #代替这个微服务名称的path变量,即只要是"主机名称:端口号/mydept/"下面的所有请求,都去注册中心的服务springcould-provider-dept中处理,value #ignored-services: springcould-provider-dept #设置不能再在zuul中使用这个微服务在注册中心中注册的服务名称对这个微服务进行消费 ignored-services: "*" #隐藏所有的可消费的服务的名称 prefix: /zhao #设置这个zuul模块配置的路由的访问前缀 -
这样在访问服务的时候我们需要在端口后面首先加上一个zuul设置的路径前缀
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0VcOWlAL-1653636297254)(SpringCloud.assets/image-20211003143732150.png)]](https://img-blog.csdnimg.cn/f5d50d4bbe604c3384847916dd6ef237.png)
-
在真实的开发中,我们一般将这个zuul模块的运行端口编程80,这样在通过它消费服务的时候就不需要设置端口号了,这就更像我们平时是的时候的样子了
5.小结
- 通过zuul模块的配置routes属性就可以实现路由
- 通过zuul模块的配置prefix属性就可以实现过滤
- 通过zuul模块的配置ignored-services属性就可以实现关闭使用服务名称通过zuul消费服务,提高整体的安全性
十七,Config:服务端连接Git配置和客户端连接服务端访问远程仓库实现
- 在学习spring cloud的时候我们就说了,它是一个C/S架构,所以我们至少写两个服务,一个是server,一个是client
1.spring cloud config 服务端实现
-
先创建server模块:springcould-config-server-3344
-
导入依赖
<dependencies> <!--config--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-server</artifactId> <version>2.2.5.RELEASE</version> </dependency></dependencies> -
编写配置文件
#设置微服务运行端口server: port: 3344#标识微服务名称spring: application: name: springcould-config-server #连接远程仓库的配置 cloud: config: server: git: uri: https://gitee.com/thhhstudy/springcloud-config.git #直接去远程仓库上复制地址,注意使用的是HTTPS,不再是使用git本地克隆的时候使用的SSH,原因就是正常分布式中微服务连接都是基于HTTP的 #注意是URI不是URL -
编写主启动类,注意使用注解@EnableConfigServer 开启config配置服务端
package com.thhh.springcloud;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.cloud.config.server.EnableConfigServer;@SpringBootApplication@EnableConfigServer //开启config配置服务端public class ConfigServer_3344 { public static void main(String[] args) { SpringApplication.run(ConfigServer_3344.class,args); }} -
测试
-
可见现在我们就可以通过创建的config的服务端获取远程仓库上的配置文件,注意:我们也只能获取到配置文件,因为spring cloud config分布式配置本来就是用来集中管理配置文件的,不是管理所有文件的
-
服务端的作用就相当于这个微服务作为了远程仓库,我们可以通过它获取到远程仓库中的配置文件
-
官方文档指出,除了使用上面例子中的URL获取到仓库中配置文件,还可以使用其他的形式获取到配置文件资源
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jq0EyYYW-1653637615332)(SpringCloud.assets/image-20211003151618892.png)]](https://img-blog.csdnimg.cn/553c733bbed743f78f2b0ceb17f09293.png)
-
可见不同的访问URL得到的数据资源格式不一样,数据也有一些不一样
2.spring cloud config 客户端实现
-
客户端就是服务提供者对应的微服务模块,在spring cloud config中,客户端需要从spring cloud config服务端获取配置文件的信息
-
在本地仓库中创建一个新的yml配置文件,作为等会儿写的服务提供者的远程配置文件
spring: profiles: active: dev ---#端口配置server: prot: 8201#spring配置spring: profiles: dev application: name: springcould-provider-dept#eureka配置eureka: client: service-url: defaultZone: http://eureka7001.com:7001/eureka/ ---#端口配置server: prot: 8202#spring配置spring: profiles: test application: name: springcould-provider-dept#eureka配置eureka: client: service-url: defaultZone: http://eureka7001.com:7001/eureka/ -
将这个文件更新push到远程仓库
- git add .
- git statuse
- git commit -m “提交的名字”
- git push origin master(分支)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f8XbXihg-1653637615333)(SpringCloud.assets/image-20211003162141325.png)]](https://img-blog.csdnimg.cn/dc733966e93a436ea1ecfa7fee955c3d.png)
-
创建一个新的子model:springcould-config-client-3355
-
导入依赖
<dependencies> <!--web--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--config--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-config</artifactId> <version>2.1.1.RELEASE</version> </dependency> <!--actuator--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency></dependencies> -
创建配置文件,这里我们需要学习一个新的配置文件:bootstrap.yml,原来我们创建的都是application.yml,那么这两个配置文件有什么区别呢?
- bootstrap.yml:代表系统级别的配置- application.yml:代表应用级别的配置- 在原来学习反射的时候,我们学习了类加载器,其中有3个类加载器- 根类加载器(bootstrap class loader)- 扩展类加载器(extensions class loader)- 系统类加载器(system class loader)- 其中根加载器的优先级别最高- 类比学习,bootstrap.yml配置文件的优先级应该比application.yml配置文件的优先级高 -
为什么要搞一个系统配置文件呢?原因就是application.yml中的配置可能和远程仓库中的配置冲突,就会造成配置不能正常的使用,而我们使用bootstrap.yml由于优先级别更高,那么最终配置就会按照bootstrap.yml中的配置为准,可以防止本地和远程仓库中的配置冲突问题
-
在spring cloud config中,只有config服务器模块才去连接远程仓库,而config客户端只应该去连接config服务器,所以config客户端的config.uri属性值应该是config服务端的地址(IP+端口)
spring: cloud: config: uri: http://localhost:3344 #连接config服务端 -
config客户端除了要配置config.uri之外,还需要配置自己需要加载远程仓库中的哪一个配置文件,按照刚刚直接通过config服务器获取配置文件的URL,我们需要配置name(配置文件名称)、profile(这个配置文件中的哪一个环境下的配置)、label(配置文件所在分支)、uri(config服务端的地址[IP+端口])
spring: cloud: config: uri: http://localhost:3344 #连接config服务端 name: config-client #配置要加载的远程仓库中配置文件的名称,注意:不要后缀 profile: dev #配置获取这个配置文件在哪一种环境下的配置 label: master #配置从哪一个分支获取配置文件 -
编写入口程序
package com.thhh.springcloud;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplicationpublic class ConfigClient_3355 { public static void main(String[] args) { SpringApplication.run(ConfigClient_3355.class,args); }} -
注意:入口程序并不需要加什么注解,按照正常的spring boot的入口程序写就行了
-
编写一个controller,用来检测config客户端模块是不是能够读取远程的配置文件并作为自己模块配置文件的一部分进行使用
package com.thhh.springcloud.controller;import org.springframework.beans.factory.annotation.Value;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;@RestControllerpublic class ConfigController { @Value("${spring.application.name}") private String applicationName; @Value("${eureka.client.service-url.defaultZone}") private String eurekaServer; @Value("${server.port}") private String serverPort; @RequestMapping("/getConfig") public String getConfig(){ return "applicationName = "+this.applicationName+"\n"+ "eurekaServer = "+this.eurekaServer+"\n"+ "serverPort = "+this.serverPort; }} -
在上面的controller中,我们使用了注解@Value,用于直接向成员属性中注入指定的值,我们又使用了${ }来解析一些的远程配置文件中才配置了的一些配置变量的值,最后通过controller的一个API向外提供输出服务,我们可以直接访问这个API,来检验config客户端是不是读取到了远程仓库中指定配置文件的内容
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qS1bYTM6-1653637615333)(SpringCloud.assets/image-20211003162756867.png)]](https://img-blog.csdnimg.cn/9e76a24a6c3746158b4261c7fdbc19db.png)
3.小结
-
通过上面的例子我们就实现了一开始学习spring cloud config的时候讲的那一幅图中的架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hvEbCead-1653637615333)(SpringCloud.assets/image-20211003162936555.png)]](https://img-blog.csdnimg.cn/ba684af75aaa49199bc291c4b7ab5bc0.png)
-
上图显示的就是我们的所有config客户端连接config服务端,由服务端再去连接远程的仓库;config服务端只需要配置一次,即在提供config服务端功能的微服务中配置上我们的远程仓库地址即可,至于每一个config客户端要使用远程仓库中的哪一个配置文件,由config客户端自己在自己的微服务模块的配置文件中进行配置即可【注意:我们需要配置name(配置文件名称)、profile(这个配置文件中的哪一个环境下的配置)、label(配置文件所在分支)、uri(config服务端的地址[IP+端口])】
十八,Config:远程配置实战测试
-
我们分别创建了两个子model:springcould-config-server-3344和springcould-config-client-3355用来作为spring cloud config分布式配置中心的服务端和客户端,我们已经实现了通过服务端连接远程仓库,通过客户端连接服务端实现读取远程仓库中配置文件的功能
-
但是在实际的开发中,我们应该将我们编写的服务提供者、消费者和注册中心的配置放在远程仓库,并将它们作为config的客户端去访问远程仓库中的配置文件,这样就实现了配置和编码的解耦,所以这一章要做的就是对原来我们写的微服务模块进行改造,将它们的配置文件放在远程仓库,而不是模块中
1.注册中心和服务提供者的配置文件改造
-
首先去本地仓库中创建一个eureka注册中心的配置文件
spring: profiles: active: dev --- spring: profiles: dev application: name: springcloud-config-eurekaserver: port: 7001#eureka配置eureka: instance: hostname: eureka7001.com #eureka server运行的主机名,所以访问eureka监控页面的url为http://localhost:7001/ client: register-with-eureka: false #表示是否向eureka注册中心注册自己,但是由于这个子model本来就是用来充当eureka服务器/注册中心的,所以设置为false #这个属性设为false同时也就表明了这个微服务是eureka服务器程序 fetch-registry: false #fetch-registry为false表示这个微服务为eureka注册中心 service-url: defaultZone: http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ #微服务提供者向注册中心的注册服务的地址,它有默认的url,为"http://localhost:8761/eureka/" #但是我们自己配置了eureka运行的主机名和端口号,所以我们在配置的时候不会将配置写死,而是获取上面我们的配置,这样后面更改的时候就只需要更改上面的显式配置,而不需要更改引用处的值---spring: profiles: test application: name: springcloud-config-eurekaserver: port: 7001#eureka配置eureka: instance: hostname: eureka7001.com #eureka server运行的主机名,所以访问eureka监控页面的url为http://localhost:7001/ client: register-with-eureka: false #表示是否向eureka注册中心注册自己,但是由于这个子model本来就是用来充当eureka服务器/注册中心的,所以设置为false #这个属性设为false同时也就表明了这个微服务是eureka服务器程序 fetch-registry: false #fetch-registry为false表示这个微服务为eureka注册中心 service-url: defaultZone: http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ #微服务提供者向注册中心的注册服务的地址,它有默认的url,为"http://localhost:8761/eureka/" #但是我们自己配置了eureka运行的主机名和端口号,所以我们在配置的时候不会将配置写死,而是获取上面我们的配置,这样后面更改的时候就只需要更改上面的显式配置,而不需要更改引用处的值 -
再写一个服务提供者的配置文件
spring: profiles: active: dev---server: port: 8001 #端口号#mybatis配置mybatis: type-aliases-package: com.thhh.springcould.pojo #mybatis的别名扫描 mapper-locations: classpath:mybatis/mapper/*.xml #mybatis去哪里读取pojo对应的mapper接口的mapper.xml文件 config-location: classpath:mybatis/mybatis-config.xml #mybatis核心配置文件,可要可不要,不要就把配置写在spring配置中#spring配置spring: profiles: dev application: name: springcould-config-provider-dept datasource: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/db01?useSSL=false&useUnicode=true&characterEncoding=utf-8 username: root password: 123456#eureka的配置eureka: client: service-url: defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ instance: instance-id: springcould-provider-dept-8001 #配置注册的服务的描述信息 prefer-ip-address: true#完善监控信息展示info: app.name: dept服务者1 #服务的名称 company.name: com.thhh---server: port: 8001 #端口号#mybatis配置mybatis: type-aliases-package: com.thhh.springcould.pojo #mybatis的别名扫描 mapper-locations: classpath:mybatis/mapper/*.xml #mybatis去哪里读取pojo对应的mapper接口的mapper.xml文件 config-location: classpath:mybatis/mybatis-config.xml #mybatis核心配置文件,可要可不要,不要就把配置写在spring配置中#spring配置spring: profiles: test application: name: springcould-config-provider-dept datasource: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/db02?useSSL=false&useUnicode=true&characterEncoding=utf-8 username: root password: 123456#eureka的配置eureka: client: service-url: defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ instance: instance-id: springcould-config-provider-dept-8001 #配置注册的服务的描述信息 prefer-ip-address: true#完善监控信息展示info: app.name: dept服务者1 #服务的名称 company.name: com.thhh -
注意:上面的两个配置文件看起来很多,其实我们只是去原来的模块中复制粘贴了配置文件,在每一个配置文件中,如果这个文件已经配置了spring.application.name属性,那么我们就为它多配置一个profiles属性,属性值为当前这个环境要使用的环境名称(比如dev或test等);如果没有配置spring.application.name属性,我们就给他配置上,并且连同profiles属性一起配置
#spring配置spring: profiles: dev application: name: name属性的值 -
一个配置文件我们就通过复制粘贴并修改profiles属性,实现配置两套环境;并在文件的上方加上以下配置实现选择当前选择哪一套环境激活使用
spring: profiles: active: 要激活的环境的profiles属性的值 -
虽然看起来很多,其实就是有一套配置好的环境,下面的直接复制粘贴,并修改profiles属性值就可以变成一套新环境了,只是上面选择激活哪一套环境需要我们自己写
-
配置好了一个注册中心的两套环境的配置文件,一个服务提供者的两套环境的配置文件,我们就可以将新创建的两个配置文件push到远程仓库中去了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4dJPwRO0-1653638146225)(SpringCloud.assets/image-20211003170238888.png)]](https://img-blog.csdnimg.cn/5f405c66f68a4cb6bf6c33553b731ec1.png)
-
接下来就是去7001注册中心和8001服务提供者中使用远程配置文件,首先我们需要删除原来的配置文件中的内容,并创建一个bootstrap.yml配置一些系统级别的配置,主要还是配置当前这个微服务要使用远程仓库中的哪一个配置文件
-
我们需要配置name(配置文件名称)、profile(这个配置文件中的哪一个环境下的配置)、label(配置文件所在分支)、uri(config服务端的地址[IP+端口])共4个属性
-
但是为了实现原来本地配置和现在远程配置的对比,我们还是直接创建两个新的model,一个为7001注册中心使用远程仓库中的配置文件的model:springcould-config-eureka-7001,一个为8001服务提供者使用远程仓库中的配置文件的model:springcould-config-provider-dept-8001;然后将这4个model进行对应的文件拷贝
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3AI0v2fw-1653638146225)(SpringCloud.assets/image-20211003170318243.png)]](https://img-blog.csdnimg.cn/814104179c8b41f0882a954a80ee6cf9.png)
-
注意:拷贝完了之后还需要为这两个新创建的model导入config客户端的依赖
<!--config--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-config</artifactId> <version>2.1.1.RELEASE</version> </dependency> -
对两个新创建的model进行config客户端改造,首先改造7001,我们需要将原来application中的配置删除,因为已经在远程配置好了;然后创建一个新的配置文件bootstrap.yml
spring: cloud: config: name: config-client-eureka #配置要加载的远程仓库中配置文件的名称,注意:不要后缀 profile: dev #配置获取这个配置文件在哪一种环境下的配置 label: master #配置从哪一个分支获取配置文件 uri: http://localhost:3344 #连接config服务端 -
对应配置8001模块的配置文件
spring: cloud: config: name: config-client-Dept-Provider #配置要加载的远程仓库中配置文件的名称,注意:不要后缀 profile: dev #配置获取这个配置文件在哪一种环境下的配置 label: master #配置从哪一个分支获取配置文件 uri: http://localhost:3344 #连接config服务端 -
注意:在创建了bootstrap.yml文件之后原来的application.yml还是应该保留,它可以在公共的远程仓库读取的配置文件的配置中加上一些这个模块独特的application配置,即它可以在远程仓库的配置文件基础上增加一些配置,所以保留它还是有用处的
-
两个模块都准备好的之后就准备启动测试效果
-
注意启动顺序,先启动config服务端3344,再启动注册中心7001,最后启动服务提供者8001
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WRgG3WYm-1653638146225)(SpringCloud.assets/image-20211003170514633.png)]](https://img-blog.csdnimg.cn/8693f5bf6f7d4cd3a2ee0edd4a865269.png)
2.小结
-
通过上面的例子我们就知道子spring cloud config分布式配置在平时开发的微服务中怎么使用了
-
我们甚至可以将所有的配置文件都变成远程托管,在编写微服务的时候直接去远程获取即可,这样做除了实现了编码和配置的解耦,也提高了配置文件的重用性,我们可以将一些公用的配置都写在远程仓库的配置文件中,而对于本微服务特别的配置就在这个微服务的配置文件中写上,这样配置文件就能简化很多重复的配置
-
在前面没有使用spring cloud config分布式配置的时候,我们都是写一个微服务就必须为它编写一个完整的配置文件,现在有了远程仓库,我们就直接从远程拿过来就使用,需要覆盖的我们可以将配置修在bootstrap.yml中,远程仓库配置文件没有的我们可以直接写在application.yml或bootstrap.yml中
-
在团队协作开发的时候一个人写好了的配置文件上次到远程仓库,所有人就都可以使用了
十九, SpringCloud总结和展望
1.总结SpringCloud
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SkXAKQFZ-1653638608048)(SpringCloud.assets/springcloud完结.png)]](https://img-blog.csdnimg.cn/98e8586d7a9d4f90a1dbd32f76359340.png)
2.后期怎么学习
- 框架源码
- 设计模式
- 新的知识探索/学习【新技术】
- Java版本的新特性
- 框架底层
- HTTP、TCP/IP原理和源码
- JVM[参考书:深入理解Java虚拟机]
- 数据结构与算法
