常见操作系统 windows macos 乌班图Linux 对上控制软件 对下控制硬件
1.windows中 C D···等 被称为根目录 c:、 有多个根目录
2. Linux中 没有盘符的概念,只有一个根目录 / 所有文件都在其下面
3.当在终端中输入 /home, 其实是在告诉电脑 先从/(根目录)开始,在进入到home目录 home是用户的主目录 然后是以用户名命名的家目录
4.打开终端:ctrl + alt + t
5.终端命令格式 command [-options] [parament]
6. man 是manua 的缩写,是Linux提供的一个手册,例如 查询 ls 命令 :man ls
7.使用man时的操作键 空格:显示手册的下一屏 enter键 一次滚动手册页的一行; b:回滚一屏; f:前滚一屏 ; q:退出 ; /xxx: 搜索xxx
8. xxx --help 查询xxx命令
9.pwd 显示当前的工作目录 tree : 以树状图列出目录内容 ls: 列举目录内容 ls -a 显示所有文件 a-all 包括隐藏文件
10.ls的两个选项 -l 以详细信息的方式显示列表内容 -h 以更加人性化的方式显示文件夹内容
11.切换工作目录cd指令用法: cd 路径 切换到指定路径 cd 一键回家目录 cd~ 一键回家目录
cd . 当前目录 cd .. 上级目录 cd - 返回上次所在目录
./ 当前目录 ../ 上一级目录
12. mkdir 创建目录,递归创建 添加-p选项 mkdir -p a/b/c ; touch 创建文件 创建一个文件 touch 文件名, 创建多个文件 touch 文件1 文件2 文件3 getdir 编辑文件 打开文件后,终端进入等待状态 ,可以同时编辑多个文件 gedit 文件1 文件2 文件3
13. rm删除文件或文件夹 文件删除之后不能恢复 rm后面使用-i; 删除文件:rm 文件名
rm -i 文件名 (以交互模式删除) rm -f 文件名 (强制删除不提示 ) rm -r 文件夹名(删除文件夹,递归删除目录中的内容)
14.cp 复制文件;cp 源文件位置路径 目标位置路径
cp -i 交互模式拷贝 -f 强制拷贝不提示 -a拷贝原有属性 -v 显示拷贝过程 cp -r 源路径 目标路径 拷贝目录
15. (mv 源路径 目标路径 ) -i 交互方式进行文件的移动 -v 显示移动的过程 -f 强制覆盖不提示 移动文件夹不用 加-r
重命名文件或者文件夹:在一个目录中进行移动 才能进行重命名( mv 旧文件名 新文件名 )
mv作用: 移动文件或者文件夹 重命名文件和文件夹
16.清屏:clear 或者 ctrl+L 自动补全:tab键 查看命令位置: which 命令 终止命令 :ctrl +c
放大终端窗口的字体显示:ctrl + shift + = 减小字体 ctrl + -
17. cal 显示日历 -3 上月 当前月 下一个月 -y 显示一年的日历 -j 以一年中的天数显示日历
date 查看日期时间 ; 格式化显示 date "+%y" 输出年份 %m 月份 %d 天数 %H 时 %M分 %S 秒 %F等同于 " %Y-%m-%d" %T等同于 " %H:%M:%S"
18. history 查看所有历史指令 history 50 查看最近的50条指令 !编号 执行某个编号的历史指令
19.cat 查看或者连接文件 1.查看文件 (cat 文件名)2.查看文件并对每一行进行编号(cat -n)
3.非空行进行编号(cat -b)4.连续2行以上的空行,只显示1行(cat -s)
5.连接文件 把两个文件内容合并输出(cat 文件1 文件2)
20.more 分页/分屏查看文件内容 (cat不分)选项: +num 从第num行查看文件 ; -p 先清屏再查看文件; -s 连续两行以上的空行,只显示一行
快捷键: 回车 查看下一行 空格 查看系一屏 ctrl+f/ f 下一屏 ctrl+b/ b上一屏 q 退出
21.数据流重定向 管道命令
输入流:从键盘或者文件中读取内容到内存中
输出流:从计算机内存中把数据写入到文件或者显示到显示器上
标准错误输出流:
重定向:改变数据的定向(一般重定向到文件中) > 重定向 >>以追加的方式重定向
管道:一个命令的输出作为另外一个命令的输入去使用 指令1 | 指令2 其中指令1必须有输出
22.软连接 :相当于快捷方式 通过软链接可以修改源文件内容 ln -s 源文件 连接文件
硬链接:一个文件有多个名字通过硬链接可以修改源文件内容 ln 源文件 连接文件
删除软硬链接,对源文件没有影响
删除源文件,软连接不可用
删除源文件,如果文件还有多个硬链接,则无影响
软链接可以指向一个不存在的文件,硬链接不可以
可以对目录创建软链接,硬链接不可以
23.文本内部搜索 grep : grep ‘内容’ 路径 -n 查看结果的行数 -i 忽略大小写 -v 取反
grep正则搜索 : grep ‘^a’ 文件路径 搜索以a开头的行
在计算机中搜索文件 find : find 目标的目录 选项 条件
按照名称搜索 -name : find ./ -name test.txt find ./ -name '*.txt' 所有的txt文件
* 任一一个或多个字符
? 任意一个字符
[ ] 范围
按照大小搜索 -size
find ./ -size +30M 大于30M的文件
find ./ -size -20M 小于20M的文件
find ./ -size +15M-size -20M 大于15 小于20的文件
24.tar归档管理 多文件归档: tar [参数] 打包文件名 文件1 文件2
目录归档: tar [参数] 打包文件名 目录
归档: tar -cvf 归档文件名。tar 待归档文件1 待归档文件2 (-c 归档 -v显示进度 -f指定档案文件名称,-f后面一定是.tar文件,所以必须放选项最后)
解档:tar -xxf 归档文件名(-x 解档)
25.归档-压缩 和 解压+解档
tar -zcvf归档文件名.tar.gz 待归档文件1 待归档文件2
tar -zxvf归档文件名.tar.gz
如果需要指定解档的目录:tar -zxvf归档文件名.tar.gz -C 要解档的目录
26.zip \ unzip 文档压缩解压
压缩文件: zip [-r] 压缩文件(可以没有扩展名) 源文件
压缩目录: zip -r xxx.zip 目录 (zip -r a.zip a 把a目录压缩为 a.zip)
unzip 解压缩: unzip xxx.zip
27.文件的权限构成
9个字母、3组(拥有者权限u 组内权限 g 其他用户权限o) 所有用户权限a
每一组权限可选的权限有:r可读 w可写 x可执行(文件:文件可以直接运行;绿色 目录:表示这个目录可以打开) - 没有权限
28.文件权限修改 chmod
字母法:
用户: u g o a
权限设置: +(增加) -(减少) =(直接设置)
具体权限 : r 读 w写 x运行
用法:chmod 用户 权限设置 具体权限 文件名 (chmod u+w 1.txt 给1.txt的拥有者增加w权限)
数字法: r -4 w -2 x-1 - -0
chmod 权限数字 文件目录 例如:chomd 777 a.txt(权限数字: 第一位文件拥有者权限 第二位 同组用户权限 第三位 其他用户权限)
目录权限:如果想要递归所有目录加上相同权限,需要加上参数‘-R’ 如:chmod -R 777 test test目录下所有文件加777权限。 一个目录具有可执行权限,表示可以切换到该目录
29.用户管理
- 切换用户
临时切换 :sudo 命令 (sudo touch 1.txt 可以在根目录下创建文件1.txt ,一般是没有权限创建的)
永久切换:1.su 用户名 输入用户名对应的密码 2.sudo -s 默认切换到root用户 输入当前用 户的密码
- passwd修改密码
passwd 修改当前用户的密码 passwd xxx 修改xxx用户的密码 sudo passwd xxx
- exit退出
exit 如果没有用户在栈中 直接退出终端 如果多次切换用户,退出到上一次登录的用户
- who
查看当前系统登陆了哪些用户 -q统计用户数量 -u显示最后一次距离现在的时间
30. 关机、重启
reboot 重新启动操作系统
shutdown -r now 重新启动操作系统,shutdown会给别的用户提示
shutdown -h now 立刻关机,其中now相当于时间为0的状态
shutdown -h 20:25 系统会在今天的20:25关机 ‘shutdown -c’ 可以取消关机
shutdown -h +10 系统会在过十分钟后自动关机 ‘shutdown -c’ 可以取消关机
31.安装软件 make install 、 deb包方式、 apt-get
apt-get 方式安装:
- 配置软件源 修改 /etc/apt/source.list
- 更新软件源 sudo apt-get update
- 安装xxxsudo apt-get install xxx (要先配置软件源)
- 卸载删除xxx sudo apt-get remove xxx
32. ssh远程登陆
服务器端安装 ssh server :sudo apt-get install openssh-server
客户端登陆: ssh 服务器用户名@服务器地址
33.scp拷贝(上传/下载)
使用该命令的前提是目标主机已经成功安装 openssh-server
上传:scp 本地路径 服务器用户@服务器ip : 服务器路径
scp ./ssh_test2.txt vvvn@192.168.1.104:/home/vvvn/python20
下载:scp 服务器用户@服务器ip:服务器路径 本地路径
scp vvvn@192.168.1.104:/home/vvvn/python20/1.txt ./1.txt
如果操作的是目录使用 : scp -r
34. vi有三种基本工作模式: 命令模式(移动光标,删除,复制) 文本输入模式(编辑文件) 末 行模式(保存文件、查找替换)
打开文件 默认是命令模式 编辑文件 a i o等键进入输入模式 保存文件 esc退出输入模式 : 键 进入末行模式
35. vim编辑器操作
- 创建文件:vi 文件名 ——> i键 进入编辑模式 ——>编辑文件 ——>esc到命令模式 ——>:键到末行模式 ——>wq 保存退出
- vi编辑器进入输入模式:
i 光标前插入 I 首行插入
a 光标后 A行尾
o光标下一行产生新一行 O光标上一行产生新一行
- 进入命令模式:任何模式下 esc键 进入命令模式
36.psutil 获取服务器的硬件信息
- CPU的核心数 psutil.cpu_count()
- CPU的使用率psutil.cpu_percent(interval=0.5)
- 内存信息psutil.virtual_memory()
- 内存的使用率psutil.virtual_memory().percent
- 磁盘的分区信息psutil.disk_partitions()
- 硬盘的指定路径的硬盘信息psutil.disk_usage('/')
- 硬盘的使用率psutil.disk_usage('/').percent
- 网络数据信息
- 收到的字节数psutil.net_io_counters().bytes_recv
- 发送的字节数psutil.net_io_counters().bytes_sent
37.__name__ 的值
- 如果 a文件被其他文件导入,此时__name__ 就是指的a文件的名称
- 如果a文件直接运行,此时__name__ 值是__main__
38.三句话,让yamail给我发邮件
- 导入模块 import yagmail
- 创建发件对象 yagmail.SMTP(user = '发件人邮箱', password = ‘邮箱授权码’, host = ‘发件服务器’)
- 发送邮件 obj.send ('收件人',‘主题’,‘内容’)
39.虚拟环境
- python虚拟环境:允许安装不同版本的套件
- 创建:mkvirtualenv 虚拟环境名称 (默认python2.7)
- 进入: workon 虚拟环境名称
- 查看所有虚拟环境: workon+回车
- 删除: 先退出虚拟环境----rmvitualenv 虚拟环境名称
- 退出:deactivate
- 创建虚拟环境,指定python路径: mkvirtualenv -p /usr/bin/python3.6 xxx
- 在虚拟环境中安装套件: pip install 套件名==版本
40. 虚拟机网卡设置
虚拟机联网方式:
- NAT(网络地址转换模式):虚拟机会使用主机VMnet8 这块虚拟网卡与我们的真实机进行通信,默认状况下 和物理机同一网络中的其它机器不能访问虚拟机,但虚拟机能够访问其它物理机。服务器
- Bridged(桥接模式):虚拟机如同一台真是存在的计算机,在内网中获取和真实主机同网段IP地址 (这时两者之间可以相互访问)
命令 ifconfig :查看IP地址
命令 ping 检测某个主机是否建立连接
41. 什么是端口?
端口是英文port的意译,可以认为是设备与外界通讯交流的出口。端口可以分为虚拟端口和物理端口,其中虚拟端口指的是 计算机内部或交换机路由器内的端口。
- 知名端口:众所周知的端口,范围从0-1023,固定不变,用户不可用
常见协议:FTP 默认端口:21 协议基本作用:文件上传、下载
常见协议:SSH 默认端口:22 协议基本作用:安全的远程登录
常见协议:HTTP 默认端口:80 协议基本作用:超文本传输
- 动态端口的范围是1024到65535,一般不固定分配某种服务,而是动态分配(动态分配是指,当一个系统程序或应用程序需要网络通信时,他向主机申请一个端口,主机从可用的端口中分配一个供他使用)
- netstat -an 查看所有端口
- netstat -an | grep :22 搜索22 端口
- sudo lsof -i :22(22端口是哪个程序在使用):查看某个端口,是哪个程序使用
42.安装虚拟环境
其中:# 1. 安装完成后,在`~/.bashrc`写如以下内容
# ~Envs为存放虚拟环境的目录
export WORKON_HOME=~Envs(这个我没有设置,我创建的虚拟环境都保存在 /home/.virtualenvs 目录下)
#指定python解释器(根据自己的安装位置更改)
export VIRTUALENVWRAPPER_PYTHON=/opt/python36/bin/python3
# Python安装目录下/bin/virtualenvwrapper.sh (根据自己的安装位置更改)
source /opt/python36/bin/virtualenvwrapper.sh
- python虚拟环境:允许安装不同版本的套件
- 创建虚拟环境:mkvirtualrnv 虚拟环境名称
- 进入:workon 虚拟环境名称
- 查看所有虚拟环境:workon + 回车
- 删除:先退出虚拟环境 rmvirtualenv
- 退出:deactivate
- 创建虚拟环境,指定Python路径: mkvirtualenv -p /usr/bin/python3.6 xxxx
- 在虚拟环境中安装套件:pip install xxx(==版本)
- 在pycharm在已有的虚拟环境中新建的project--perviously configured interpret---/虚拟环境路径下的/bin/python3.10。
- 切换虚拟环境--settings--->project:test--->project interpreter更换
43.socket简介
两台电脑通信:IP地址--两者的地址; 端口号--门牌号;传输方式--快递种类;socket--快递员派送,网路通信的控制单元,实现数据的收发。
socket 简称套接字,用套接字中的相关函数完成通信过程
- # 1.导入socket模块
- import socket
- # 2.创建套接字,使用IPv4 UDP方式
socket.socket(协议类型,传输方式)
参数一:socket.AF_INET 使用IPv4 socket.AF_INET6 使用IPv6
参数二:socket.SOCK_DGRAM 使用UDP socket.SOCK_STREAM 使用TCP
- udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
- # 3.数据的传递
udp_socket.sendto(数据,IP和端口)数据。encode()转换为二进制
- udp_socket.sendto('Hello,world'.encode(), ('192.168.61.1', 10000))
- # 4.关闭套接字
- udp_socket.close()
开启网络调试助手:设置协议方式:UDP 设置IP地址,设置端口,连接网络
44.UDP 网络发送和接受数据
#1.导入模块
import socket
#2.创建套接字
upd_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
#3.发送数据
upd_socket.bind(('192.168.61.128', 4545))
upd_socket.sendto('www'.encode(), ('192.168.61.1', 8080))
#4.接收数据
recv_data = upd_socket.recvfrom(1024)
recvfrom(1024) :每次接收1024字节,此方法会造成程序阻塞,等待另一台计算机发来数据 自动接触阻塞,否则一直等待
recv_data 是一个元组 第一个元素recv_data[0]:收到数据的二进制。 第二个元素 recv_data[1]:发送方的IP和端口。
#5.解码数据
recv_text = recv_data[0].decode()
把接受的数据进行解码:二进制--->字符串 [二进制数据.decode('GBK') GBK 有时需要]
#6.输出显示接收到的内容
print('来自:', recv_data[1], '消息:', recv_text)
#7.关闭套接字
upd_socket.close()
45.UDP绑定端口
核心方法 bind(address)
address要是一个元组,第一元素是IP地址(可以省略,表示自己的IP),第二个元素是 端口号
upd_socket.bind(('192.168.61.128', 4545))
bind(‘ ’,4545)#IP尽可能写为空的,好处是 当计算机有多个网卡时,都可以被接收
46.python3编码转换
GBK:中文编码 UTF-8:万国码 (Ubuntu默认UTF-8编码)
编码encode()默认UTF-8编码,
解码decode( ) 默认有两个参数decode(encoding=‘UTF-8’, errors = ‘strict’)
encoding=‘UTF-8’ :指定解码格式,Windows发送字符串为GBK,解码也要GBK
错误处理方式:
errors = ‘strict’ ----严格模式,解码失败,出错
errors = ‘ignore’ ----解码失败,忽略错误
47.UDP发送广播
广播地址:xxx.xxx.xxx.255 或者 255.255.255.255
- 导入模块
import socket
- 创建套接字
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
- 设置广播权限(套接字默认不允许发送广播,需要开启相关权限)
udp_socket.setsockopt(套接字, 属性,属性值)
socket.SOL_SOCKET(当前的套接字)
socket.SO_BROADCAST(广播属性)
udp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_BROADCAST, True)
- 发送数据
udp_socket.sendto('ni hao a'.encode(), ('255.255.255.255', 8080))
- 关闭套接字
udp_socket.close()
48.UDP聊天器
思路分析:
一、功能(1.发送信息 2.接收信息 3.退出系统)
二、框架设计
1.发送信息 send——mesg()
2.接收信息 recv_msg()
3.程序的主入口main()
4.当程序独立运行的时候,才启动聊天器
三、实现步骤
1.发送信息 send_mesg()
定义变量接收用户与输入的接收方IP地址
定义变量接受用户与输入的接收方的端口
定义变量接收用户与输入的接收方的内容
使用socket的sendto()发送信息
2.接收信息 recv_msg()
使用socket接收数据
解码数据
输出显示
3.主入口main()
创建套接字
绑定端口
打印菜单
接受用户输入选项
判断用户的选择,并调用对应的函数
关闭套接字
49.TCP协议:面向连接的、可靠的、基于字节流的传输通信协议
TCP通信过程:1.建立连接,数据传送,终止连接
TCP特点:1.面向连接 ,TCP不适用于广播传输
2.可靠传输 ,TCP采用发送应答机制;超时重传;错误校验(顺序校验,去除重复);流量控制,阻塞控制
TCP严格区分客户端 服务器端
客户端流程:socket对象------connect-------send(recv)----close
服务器端流程:socket对象----bind----listen----accept----recv(send)---close
50.TCP网络程序--客户端
1、导入模块
import socket
2、创建套接字
tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#3、建立连接connect
tcp_client_socket.connect(('192.168.61.1', 8080))
#4、发送数据
tcp_client_socket.send('hello'.encode())
5、接收数据
recv_data = tcp_client_socket.recv(1024) #recv_data保存的是服务端回复消息的二进制
recv_text = recv_data.decode('GBK') 解码
print(recv_text)
5、关闭套接字
tcp_client_socket.close()
51、TCP网络程序--服务端
0、导入模块
import socket
1、socket创建一个套接字
tcp_socket_service = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
2、bind绑定IP和port
tcp_socket_service.bind(('', 8081))
3、listen使套接字变为可以被动链接 开启监听
开启监听(设置套接字为被动模式)
listen()的作用设置,对象为被动监听模式,不能主动发送数据
128是允许接收的最大连接数,在Windows下有效 Linux下无效
tcp_socket_service.listen(128)
4、accept 等待客户端的链接
new_client_socket, client_ip_port = tcp_socket_service.accept()
accept()开始接受客户端的连接,程序会默认进入阻塞状态(等待客户链接),如果客户链接后,程序会自动解除阻塞。
tcp_socket_service.accept() 会返回两部分,一是:返回了一个新的套接字socket对象,只会服务当前套接字,会为每一个新的连接客户端分配一个新的套接字对象。二是:客户端的IP和端口。两者是一个元组
5、recv/send接收发送数据 (使用新的套接字接收客户端发送的消息,然后关闭新的套接字)
recv_data = new_client_socket.recv(1024) #recv会让程序再次阻塞,收到信息后解除阻塞
recv_text = recv_data.decode('GBK') #Windows传来的是GBK编码 默认是UTF-8编码
print('from %s text : %s' % (str(client_ip_port), recv_text))
new_client_socket.close() #表示不能再和当前的客户端通信了
6、关闭服务器的套接字
tcp_socket_service.close() #服务器不再接收新的客户端,老客户端可以继续服务
52.with open
with open (‘文件名’, 打开方式)as file:
等同于:file = open(‘文件名’, 打开方式)
53 文件下载器
客户端:
1.导入模块
2.创建套接字
3.建立连接
4.接收用户输入的要下载的文件名字
5.将要下载的文件发送给服务器端
6.创建文件准备保存数据
7.接收数据保存在文件里 循环
8.关闭套接字
服务器端
1.导入模块
2.创建套接字
3.绑定IP
4.设置监听
5.连接客户端
6.接收客户端发送的文件名,返回新的套接字 根据文件名读取文件内容
7.根据读取的内容发送数据 循环
8.关闭新的套接字 关闭和当前客户端的连接
9.关闭套接字
54...TCP.三次握手,四次挥手
UDP 传输速度快,占用资源少,性能损耗少,稳定性弱
TCP 稳定性强
SYN 同步位(=1 表示进行一个连接请求) ACK 确认位(=1 确认有效 =0 确认无效 ) ack 确认号 对方发送的序号+1 seq 序号随机的
TCP连接 (三次握手)
1 客户端 主动发起一个请求(SYN=1 seq=u)---->服务器
2 服务器(SYN=1 ACK =1 ack=u+1 seq=w)---->客户端
3 客户端(ACK=1 ack=w+1 seq=u+1)--->服务器
传输数据
TCP断开连接(四次挥手)
FIN=1 申请断开连接 并且停止向服务器发数据
1 客户端 主动发起一个请求(FIN=1 seq=u)---->服务器
2 服务器(ACK=1 ack=u+1 seq=w)---->客户端
·以上半关闭状态 还可以向客户端发送数据 等发送完数据
3 服务器(FIN=1 ACK =1 ack=u+1 seq=w)---->客户端
4 客户端 (ACK=1 ack=w+1seq=u+1)---->服务器 然后关闭
等待一个时间 关闭
55.IP地址和域名
IP的全程是 互联网协议地址,就是网络地址。具有唯一性。IP地址分为IPv4 互联网协议的第四个版本 32位二进制构成,点分十进制;IPv6 互联网协议的第六个版本 点分十六进制
特殊IP地址:127.0.0.1 每台电脑都有,是电脑内部的地址,自己访问自己,外网无法访问
域名:
一个特殊的名称 也就是网址 IP地址取一个别名 简称DN ,可以理解为网址 组成:字母,数字,中划线 不超过255个字符 .com商业机构,顶级域名。.cn国内专用域名 .gov 国内政府事业单位域名 .org
各种组织的域名 .net 最初用于网络组织 .com.cn 国内常见二级域名
localhost 是一个域名,不是地址,可以被配置为任意的IP地址
56.浏览器访问服务器的过程
DNS 域名解析系统:将域名翻译成相应的IP地址
先到本地DNS查询,没有的话再去请求远程的DNS服务器查询
浏览器---->输入网址---->本地DNS服务器查询IP---->远程DNS服务器---->建立TCP连接
本地DNS服务器是一个文件: WindowsC:\Windows\System32\drivers\etc\hosts
Ubuntu /ets/hosts
57.HTTP协议 超文本传输协议,发布和传输HTTP文本也就是网页 规定了浏览器和服务器请求响应规则
分为两部分:请求协议,响应协议
协议由协议项来构成,协议项:1 协议名 2.协议值
58.HTTP协议格式查看
web中, 服务器把网页传给浏览器(HTML代码发给浏览器,浏览器解析显示),而浏览器和服务器之间的传输应用层协议就是HTTP协议:
所以 HTML是一种用来定义网页的文本,会HTML就可以编写网页
HTTP是用来在网络上传输HTML文本的协议,用于浏览器和服务器的通信
59.HTTP协议 ------请求协议
1.GET 方式有 请求行,请求头,空行 GET /HTTP/1.1 请求方式
2,POST方式,请求行,请求头,空行,主体
请求报文格式:
请求行:请求方式 资源路径 协议及版本\r\n
请求头:协议项(协议名:协议值\r\n)
请求空行:分割请求头和请求主体
请求主体:浏览器发送给服务端的内容(get方式没有请求体,post方式有请求体)
响应报文格式总结:
相应行:HTTP版本 状态码 原因短语\r\n (HTTP/1.1 200 OK、人、n)
响应头:头名称:头对应的值\r\n Server:BWS/1.1\r\n
空行
响应内容 hello world
60.长连接,短连接
长连接:一次连接,多次数据传输,通信结束,关闭连接
特点:一旦连接,速度有保障。当瞬间访问压力较大时,服务器不可用 HTTP长连接的 协议,会在响应头加 Connection:keep-alive
短连接:一次连接,一次传输就关闭
特点:会频繁的建立和断开连接,当瞬间访问压力比较大,服务器响应过慢
61.模拟浏览器
导入模块
创建套接字
建立连接
拼接请求协议
发送请求协议
请求报文默认是字符串,要转换程二进制
接收服务器响应
find查找 然后字符串截取
保存数据
关闭连接
62.web服务器
面向对象封装
- 创建新的类WebServer
- 创建对象的方法 __init() start()
- 修改代码
- 把套接字初始化的操作放到__init()
- 把接收客户端连接的代码,放到start()
- 把request_handler()函数,变成 对象方法
- 把main()函数中创建对象 ws = WebServer()然后启动 ws.start()
63.简单Web服务器--框架构建
创建框架构建相关的文件夹
创建app模块文件挨app.py(一个模块就是一个文件)
在app模块中创建application函数(用于处理请求)
将request_handler()中的处理逻辑交由app模块的application函数完成
app模块的application 函数返回响应报文
64.给服务器加上命令行参数
在终端运行web服务器
启动格式:python3 webserver.py 8080(webserver.py 是web服务器文件 8080是其对外服务端口)
sys中argv模块,argv 参量变数 一般在命令行调用的时候由系统传递给程序,这个变量其实是一个list列表, argv[0]: 一般是被调用的脚本文件或全路径,和操作系统有关
argv[1]:是所有参数
isdigit()
isdigit()方法检测字符串是否只有数字组成,如果是返回True 否则返回False
65.网游服务端 --能够利用web服务器选择发布web项目
功能
1.用户使用浏览器打开指定网址
2.游戏运行方启动服务器,选择要发布的游戏
3.客户端刷新浏览器即可畅玩新游戏
实现方法:
1.给类增加一个初始化的方法 init_project() ,在初始化方法中配置当前项目
1.1 显示游戏菜单
1.2 接收用户的选择
1.3 根据用户的选择发布指定的项目(保存用户选择的游戏到对应的本地目录)
3.更改web服务器打开的文件目录
核心代码:
1.dict():创建一个空字典
2.projects_dict.key():返回值是一个含有字典所有key的对象,可以通过list()得到一个列表
3.enumerate()会把列表组合为一个索引序列
4.Content-Type: text/html 服务器响应头中加入这句话,表示浏览器优先使用html解析服务器返回的内容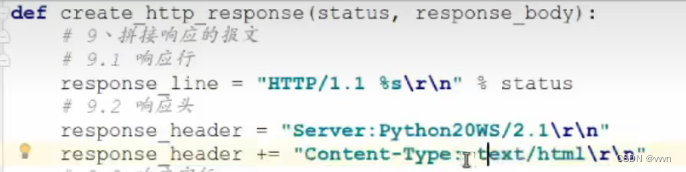
66.总结
http协议分为:请求协议, 响应协议
请求协议 :
请求行:请求方式 资源路径 版本协议\r\n
请求头:协议项 (协议名:协议值)
请求空行:分隔请求头和请求主体
请求主体:浏览器要发送给服务端的内容 (get方式没有请求主体,post方式有请求主体)
响应协议:
响应行:协议及版本,状态码,状态描述\r\n(常见状态码:400客户端请求资源不存在 302重 定向 200一些正常)
响应头:协议项构成(协议名:协议值)\r\n
响应空行:\r\n分隔响应头和响应主体
响应主体:服务器响应给客户端的数据
67.多任务(同时运行多个任务)三种实现方法:线程、进程、协程
Python 默认是单任务
68.多任务实现的第一个方法:线程
可以简单理解为程序执行的一条分支,也是程序执行流的最小单元。线程是被系统CPU独立调度和分派的基本单位
主线程:当一个程序启动时,就有一个进程被操作系统创建,于此同时一个线程也会立刻执行,该线程叫做程序的主线程 (主线程是产生其他子线程的线程;主线程必须最后完成执行)
子线程:可以看作是程序的一条分支,子线程启动之后会和主线程一起执行 。
使用threading模块创建子线程 方法:
1. threading.Thread(target = 函数名) threading模块的Thread类创建子线程对象
2.线程对象.start() 启动子线程
查看线程数量
threading.enumerate()获取当前所有活跃的线程对象列表,
使用len()对列表求长度可以看到当前活跃的线程个数。len(threading.enumerate())
threading.current_thread() 获取当前线程对象,对象中含有名称
线程参数和顺序
传递参数有3种方法:1.元组args2.字典kwargs 3.混合元组和字典

线程执行时无序的,线程会由CPU 调度执行,CPU会根据运行状态由调度算法去 调度执行。
守护线程:如果在程序种将子线程设置为守护线程,则该子线程会在主线程结束时自动退 出,设置方式thread.setDaemon(True),要在thread.start()之前设置,默认是false,也 就是主线程结束时,子线程依然在执行,
并行和并发
并发:任务数量大于CPU核数 ,通过操作系统的各种任务调度算法,实现多个任务’一起执行‘的现象(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去像一起执行而已)
并行:任务数量小于CPU核数
自定义线程类(通过继承threading.Thread 可以实现自定义线程类 )
1.可以应用于 多线程下载 2.多线程爬虫
2.自定义线程类步骤(1.导入模块 2.创建子类并继承threading.Thread 3.重写父类run() 4. 创建对象并且调用start方法)
3.如果要修改初始化__init__()方法,先通过super调用父类的初始化方法,子类再初始化
def __init__(self, num): #在init中,先去调用父类的init方法 super.__init__() self.num = num多线程-共享全局变量--------会有问题----锁来解决这个问题
多线程之间可以共享全局变量 ,但也存在问题---当多线程同时访问同一个资源时,会出现资源竞争的问题。
解决:
方法1:优先让某一个线程先执行 (线程对象.join()) 缺点:多线程变成了单线程,影响整体效率。
方法2:使用锁,同一时间只有一个线程访问资源,同步锁。
同步异步
同步:多任务,多个任务之间执行的时候要求由先后顺序,必须先执行完成之后,另一个才能继续执行,只有一个主线
异步:多个任务之间没有先后顺序,可以同时运行,执行的先后顺序不会有什么影响,存在多条主线
线程锁:当线程获取资源后立刻进行锁定,资源使用完毕后解锁。(因为轮流调度还是有线程的交互,但是避免了重叠)
互斥锁:当多个线程几乎同时修改某个共享数据的时候,需要同步控制,线程同步能够保证多个线程安全访问竞争资源,简单的同步机制就是引入互斥锁。原则:尽可能少的锁定竞争资源
1.创建一把锁 lock1 = threading.Lock()
2.上锁 lock1.acquire()
3.解锁 lock1.release()
死锁:在多线程间共享多个资源时,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
避免死锁:锁使用完毕之后及时释放。
案例:多任务版udp聊天器
创建子线程,单独接收用户发来的信息
# 创建接受子线程thread_recv = threading.Thread(target=rec_msg, args=(udp_socket, ))# 启动线程thread_recv.start()使用循环,可以接收多条信息
案例:tcp服务端 支持多线程
每来一个客户端就创建一个新的线程
69.实现多任务的第二种方法:进程
1.进程也是实现多任务的一种方式,是资源分配的最小单位,也是线程的容器。 一个进程包 含多个线程。
2.程序:xxx.py 这是程序,是静态的。
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单位。
3.进程的状态:新建、就绪、运行、等待、死亡
4.进程基本使用步骤:
- 导入模块
- 通过模块提供的processing类,创建进程对象
- 启动进程
5.进程名称:使用 getpid 和 getppid 获取进程id 和 进程父id
multiprocessing.current_process()
设置名称
multiprocessing.current_process(targe=xxx, name=‘进程名称’)
获取进程的编号
方法1:multiprocessing.current_process().pid
方法2:os.getpid()
获取进程的父id
os.getppid()
结束进程
kill -9 进程的编号
5.进程的参数、全局变量共享问题
参数的传递有3种方式:
# 1)使用args 传递元组
# 2)使用kwargs 传递字典
# 3)混合使用 args 和 kwargs
多进程之间是不能共享全局变量的,子进程运行时,是把主进程资源数据复制一份到子进程内部运行,不会影响主进程的内容。
5.1.消息队列Queue-基本操作------多进程之间实现数据的传递、共享
消息队列:为了实现进程间的通信,传递数据,实现共享
队列的创建
导入模块
创建对象multiprocessing.Queue(5) #队列长度是5
队列的操作
放值--从队列尾部放入值 queue.put()
取值--从队列头部取值 queue.get()
xx_nowait() 方式 put_nowait() 队列未满,同put() 已满 会报错 不等待
get_nowait() 队列未空,同get() 已空会报错 不等待
判断队列是否为满queue.full()
判断队列是否为空queue.empty()
取出队列中消息的数量queue.qsize()
6.守护主进程
子进程和主进程的约定,当主进程结束时,子进程也随之结束: pro_obj.daemon = True
结束子进程的执行:pro_obj.terminate()
80.进程和线程的区别
1.进程是系统进行资源分配和调度的独立单位
2.线程是进程的一个实体,是CPU调度和分派的基本单位,它是一个比进程更小的能独立运行的基本单位。
3.一个程序至少有一个进程,一个进程至少有一个线程
· 频繁创建销毁的优先使用线程(如:web服务器)
· 线程的切换速度快,所有需要大量的计算,切换频繁时用线程(如图像处理,算法处理)
· CPU密集型,进程优先(可以调用所有CPU),I/O密集型 线程
· 稳定安全用进程,速度需要用线程
python原始解释器Cpytho 种存在着 GIL全局解释器锁,造成在多核CPU中,多线程也只是一个核做分时切换,只有一个核工作。如果是I/O操作则不是这样
多进程会调用所有
总结:进程和线程的对比:
- 进程是资源分配的基本单位,线程是CPU调度的基本单位
- 进程运行需要独立的内存资源,线程只需要必不可少的一点资源‘
- 进程切换慢,线程切换更快。
- 线程不能独立运行,必须运行在进程中(进程提供资源)
- CPU密集型 进程;I/O密集型 线程
- 程序更稳定 进程;线程相比较不够稳定。
- 一般线程 进程组合使用。
81.进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing 中的Process动态生成多个进程,但是如果成百上千个目标,手动去创建进程的工作量就是巨大的,此时可以用multiprocesing 模块提供的Pool方法。‘
作用:管理和维护进程,两种工作方式 :同步 和 异步;
核心方法:
1.apply(函数名,(参数1,参数2....)):进程池中的进程以同步的方式执行任务:进程一个一个执行,一个执行完毕后另一个才能执行,有先后顺序
2.apply_async(函数名, (参数1,参数2..)): 异步方式 :进程池中的进程一起执行,多个进程一起执行,没有先后顺序非阻塞方式。1.还要关闭进程pool.close(),表示不再接收新的任务 2.还要join(),表示主进程等待进程结束后再关闭
3.进程池创建两步:1.导入模块 2.创建进程池 pool = multiprocessing.Pool(n) 允许创建最大进程数为n
82.使用队列Queue 实现 进程池中的进程之间的通信
进程池中队列创建方法:multiprocessing.Manager().Queue()
注意:异步方式:先要close 再 join 想让一个进程执行完再执行另一个 用wait方法
异步方式 # apply_async() 返回值是 APPLYRESULT 的一个对象,该对象有一个wait()方法,类似join# wait()方法表示 先让当前进程执行完毕,再执行后续进程 result = pool.apply_async(write_queue, (queue, )) result.wait() pool.apply_async(read_queue, (queue, )) pool.close() pool.join()83.文件copy器:使用进程实现文件夹 整体 拷贝到另外一个目录
源文件夹 ---目标文件夹
思路
1.定义变量 保存源文件和目标文件夹的路径
2.在目标路径创建新文件夹 用来保存文件
3.获取源文件夹中所有的文件(列表)
4.遍历列表 获取文件名
5.定义函数拷贝文件 参数:源文件夹路径 目标文件夹路径 文件名
5.1 拼接源文件和目标文件的具体路径
5.2 打开源文件,创建目标文件
5.3 获取源文件内容,写到目标文件中(while)
创建文件夹 导入os模块 os.mkdir(路径)
获取文件夹中的内容 os.listdir(路径)
70.实现多任务的第三种方法:协程
可迭代对象---迭代器----生成器----协程
1.可迭代对象:迭代也称为遍历(可以用for in 遍历) 列表 元组 字符串 字典 都是可迭代对象
- 可迭代--可遍历
- 哪些可以迭代:列表 元组 字符串 字典 range()
- 哪些不可以迭代:10, 自定义myclass类
2. 如果myclass对象所属的类Myclass中包含了__iter__()方法,此时myclass对象就是一个可迭代的
- 可迭代对象的本质:对象所属的类中包含了__iter__()方法
3. 检测可迭代对象:isinstance(待检测对象, iterable) 返回值True:可迭代 返回值False:不可迭
4.可迭代器:可迭代对象进行迭代使用的过程中,每迭代一次都会返回对象中的下一条数据,一直向后读取数据直到迭代了所有数据后结束,帮助我们进行数据迭代的 称为 迭代器。
可迭代对象 通过 __iter__() 方法向我们提供一个迭代器,我们在迭代一个可迭代对象的时候,实际上就是先获取该对象提供的一个迭代器,然后通过这个迭代器来依次获取对象中的每一个数据
可迭代对象--->迭代器--->通过迭代器获取每一个数据
一个可迭代对象可以提供一个迭代的对象
可迭代对象----> 获取迭代器:iter(可迭代对象)----->获取可迭代对象的值:next(迭代器)
5. 迭代器特点: 记录遍历的位置; 提供下一个元素的值(配合next())
6.for循环的本质:
1)通过iter(可迭代对象)获取要遍历对象的迭代器;
2)next(迭代器) 获取下一个元素;
3)帮我们捕获了StopIteration异常。
7.
# 自定义迭代器类, 满足两点:# 1.必须含有__iter__() 方法# 2. 必须含有__next__() 方法class MyIterator(object): def __iter__(self): pass # 当 next(迭代器)的时候 会自动调用该方法 def __next__(self): pass8. 迭代器的应用----自定义列表
1.Mylist类
1) 初始化方法
2)__iter__()方法,对外提供迭代器
3)additem()方法 添加数据
2.MyIterator() 类
1)初始化方法
2)迭代器方法__iter__()
3)获取下一个值的方法__next__()
目标:
for value in mylist:
print(value)
9.斐波那契数列
通过for in 循环来遍历迭代 斐波那契数列中的前 n 个数。
其中斐波那契数列由迭代器生成
a= 1 b =1 -------a=b b=a+b
自定义迭代器
1.定义迭代器类
2.类中定义__iter__方法 一般返回自己
3.类中定义__next__方法
目标:
Fib = Fibnacci(5) #指定生成5列斐波那契数列
1.value = next(Fib)
10. 生成器概念:特殊的迭代器(按照一定的规律生成数列)
生成器创建方式
1.列表推导式 data_list2 = (x*2 for x in range(10))
2.函数中使用 yield
def test2():
yield 10
m2 = test2()
value = next(m2)
print(value)
11.斐波那契数列 --生成器
1.创建一个生成器
目标:实现斐波那契数列
1) 定义变量保存第一列和第二列的值
2)定义变量保存当前生成的位置
3) 循环生成数据 。。条件:当前生成的位置<生成总列数
4)保存a的值
5) a=1 b= a a,b = b, a+b
6)返回a的值 yield a
2.定义变量保存生成器
3.next(生成器) 得到下一个值
yield作用 :1.能够充当return的作用 2.能够保存程序的状态 并且暂停程序执行 3.当next()时 可以唤醒生成器下一次从yield位置向下执行
12.生成器的注意事项
- send方法能够启动生成器并传递参数
- 生成器中 Return的作用
return : 生成器中可以使用return,让生成器结束。可以捕获异常,异常的内容就是return。
send的作用:生成器.send(传递给生成器的值)
fib.send(参数值)
xxx = yield data 》》》xxx = 参数值
13.协程》》》yield 关键字
协程就是可以暂停执行的函数,协程在不开辟新的线程的基础上,实现多任务。
特殊的迭代器--生成器
特殊的生成器--协程
14.协程》》》greenlet
Greenlet是python的一个C扩展,第三方模块,可以提供协程,targe.switch(value) 可以切换到指定的协程(targe)然后 yield value = greenlet 用 switch 来表示协程的切换
使用步骤1.导入模块from greenlet import greenlet
2.创建greenlet对象g1 = greenlet(work1)
3.切换任务g1.switch()
15 . 协程》》》gevent
1.gevent 是一个第三方库,自动识别程序中的耗时操作
2.使用步骤
1)导入模块 import gevent
2)指派任务 g1 = gevent.spawn(函数名,参数1,参数2···)
3)join()让主线程等待协程执行完毕再退出
gevent不能识别程序耗时的时候给程序打补丁(猴子补丁)
4)gevent 不能识别耗时操作的问题
默认情况下 gevent不能识别 time.sleep(0.5) 为耗时操作 解决方法2个:
1. time.sleep(0.5) 改为 gevent.sleep(0.5)
2.给gevent打补丁 (目的是让gevent识别 time.sleep(0.5) 为耗时操作)
1)导入monkey模块 from gevent import monkey
2)破解补丁 monkey.patch_all()
3.猴子补丁作用: 1.运行时替换方法、属性 2.在不修改第三方代码的情况下增加原来不支持的功能 3. 在运行时为内存中的对象增加patch 而不是在磁盘源代码中增加
90.进程、线程、协程总结
1.进程:资源分配基本单位 线程CPU调度的基本单位 协程单线程执行多任务
2. 切换效率:协程> 线程> 进程
3. 高效方式:进程+协程
多进程:密集CPU 任务,需要充分使用多核CPU资源(服务器、大量的并行计算)的时候用多进程
缺点:多个进程之间通信成本高,切换开销大
多线程:密集I/O任务使用多线程
缺点:同一个时间切片只能运行一个线程,不能做到高并行,但是可以做到高并发
协程:当程序中存在大量不需要CPU操作的时候(例如I/O) 适用于协程
多线程请求返回是无序的,那个线程有数据返回就是处理哪个线程,而协程返回的数据是有限的
缺点:单线程执行,处理密集CPU和本地磁盘IO 的时候,性能低,处理网络I/O性能高
91.并发下载器
使用协程实现网络图片的下载(并发下载多张图片)
方法
- urllib.request.urlopen() ---打开网址并且返回对应的内容(二进制流)
- joinall({列表}):批量把协程join
gevent.joinall({ gevent.spawn(download, img_1, '1.img'), gevent.spawn(download, img_2, '2.img'), gevent.spawn(download, img_3, '3.img') })下载图片--打开相应的地址---将数据保存到本地
1.定义变量保存要下载的图片的地址---调用文件下载函数(打开地址得到二进制数据--再本地创建文件--循环保存数据--捕获异常)
2.思路:
- 1.定义变量保存要 下载图片的路径
- 2.调用文件下载函数,专门下载文件
- 文件下载函数:
- 1.获取要下载图片的路径,根据url地址请求网络资源
- 2.在本地创建文件,准备保存
- 3.(循环)读取网络资源的数据
- 4.捕获异常
92.协程版-Web服务器
思路:
1.导入gevent模块
2. 使用gevent 调用 request.handler函数,实现多任务
3.引入monkey,对程序打补丁
93. 正则表达式
正则表达式:一套特殊的使用规则,又称规则表达式 regex、regexp、RE,用来检索,替换某些符合某个模式(规则)的文本。
- 测试字符串的某个模式,即数据有效性验证
- 实现按照某种规则替换文本
- 根据模式匹配从字符串中提取一个子字符串(爬虫)
1. 正则表达式的构成:
- 原子(普通字符,如英文字符)
- 元字符(有特殊功用的字符)
- 以及模式修正字符组成
2.测试正则表达式正确性的软件regexbuddy
- 选择版本
- test选项卡
3. 正则表达式--匹配单个字符
. 匹配任意一个字符 除了\n
[ ] 匹配[ ]中列举的字符
[ab] 匹配a或者b
[a-z] 匹配所有小写字母
[a-z] 匹配所有大写字母
[0-9] 匹配数字
[a-zA-Z] 匹配所有小写字母和所有大写字母
\d 匹配数字 0-9
\D 匹配非数字
\s 匹配空格
\S 匹配非空格
\w 匹配单词字符 即 0-9 a-z A-Z _
\W 匹配非单词字符
4. 正则表达式--匹配多个字符
* 匹配前一个字符出现0次或者无限次,即可有可无
+ 匹配前一个字符出现1次或者无限次
? 匹配前一个字符出现0次或者1次
{m} 表示前一个字符连续出现m次
{m,n} 表示前一个字符连续出现最少m次,最多n次 m<n
5. 正则表达式--匹配开头和结尾
^ 表示匹配 以 后一个字符开头
1) 匹配以指定字符开头
^[a-zA-Z_] :必须以小写字母,大写字母,下划线开头
2)在[ ]内部,用于取反
[^he] :匹配不含有h 和 e 的字符
$ 匹配以 前一个字符结尾
6. re模块操作
作用:python中使用re模块,可以使正则表达式对字符串进行匹配。
1.re.match(patten, string, flags = 0)
1)patten 正则表达式
2)string 要匹配的字符
3)flags 匹配模式
2. 匹配成功会返回一个 match.object对象,该对象有下列方法;匹配失败None
1) group() 返回被re匹配的字符串
2) start()返回匹配开始的位置
3) end()返回匹配结束的位置
4) span()返回一个元组包含匹配(开始,结束)的位置
3. re模块使用步骤:
1)导入模块
2)使用match方法 检测匹配
result = re.match('^[0-9]?[0-9]$|^100$', '100')
3)判断匹配是否成功
if result:
# 4. 如果成功获取匹配结果
print('匹配成功,结果为:', result.group())
else:
print('匹配失败')
4)取出匹配的具体内容
result.group()
7.匹配分组
| 作用:或者的关系,多个正则表达式满足任意一个都可以
^[0-9]?[0-9]$|^100$ :^[0-9]?[0-9]$ 或者^100$ 满足任意一个
( ) 作用:1. 分组,整体匹配
result = re.match('\w{4,20}@(163|qq|126)\.com$','15633798331@126.com') 2. 提取字符串
1 2
result = re.match('(\d{3,4})-(\d{7,8})','010-1234567')
result.group() :获取匹配结果
result.group(1) :获取第一个小括号的内容
result.group(2) :获取第二个小括号的内容
\ 作用: 引用 分组 匹配到的字符串
1 2
<([a-zA-Z0-9]+)><([a-zA-Z0-9]+)>.*</\\2></\\1>
<html><h1>test</h1></html> 引用第一组表示要和第一组完全相同
\\1 表示引用第一组; \\是转义字符,转义后代表一个\(在python中需要转义)
\\2 表示引用第二组
?P<name> 作用: 给分组起别名,别名为name (?P=name) 引用别名为name的分组
re.match('<(?P<name1>[a-zA-Z0-9]+)><(?P<name2>[a-zA-Z0-9]+)>.*</(?P=name2)></(?P=name1)>', '<html><h1>test</h1></html>')
8. re模块的高级方法
- search 搜索匹配
match 与 search 的区别:
1》 match 从需要检测的字符串的开头位置匹配,如果失败返回 none
2》search 从需要检测的字符串中搜索满足正则的内容,有则返回对象
- finall('正则表达式','待查找内容') 在需要匹配的字符串中查找全部满足正则内容,返回值是列表
-
sub('正则表达式','新的内容','要替换的字符串') 字符串替换(按照正则,查找字符串并且替换为指定的内容)返回替换后的内容
-
split('正则表达式','待拆分的字符串') 按照正则拆分字符串,返回值是一个列表
9. 贪婪 和 非贪婪
python里数量词默认是 贪婪的,总是尝试匹配尽可能多的字符;非贪婪相反,总是尽可能少的匹配字符。
贪婪:满足正则的情况下,尽可能多的取内容,默认为贪婪模式
非贪婪模式:满足正则的情况下,尽可能小的取内容,默认为贪婪模式
把贪婪模式转换为非贪婪模式,需要使用:? 在 * + ? { } 后添加? 表示非贪婪
result = re.search('src=\"(.*?)\"',str)
10.r的作用
- python中在正则字符串前面加上‘r’表示,让正则中的 \ 不再具有转义功能,只是表示一个\
之前\\ 表示\ 现在r后 用\表示\
11.应用案例:简单爬虫--批量获取电影下载列表
思路
一、 定义函数 获取 列表页的内容页地址
- 定义列表的地址
- 打开url地址,获取资源
- 读取资源数据
- 解码数据
- 使用正则得到所有的影片内容地址
5.1 遍历,取出内容地址
5.2 拼接内容地址
5.3 根据内容地址 打开内容页
5.4 获取数据,读取数据
5.4 解码数据,得到html内容页文本
5.5 使用正则,获取下载地址的链接
5.6 把影片信息和下载链接,保存到字典中
二、主函数main’
1.调用 一的函数,得到字典
2.遍历字典,显示下载内容
